기준 자료:
lecture_04.pdf(CS336 Lecture 4). 각 페이지를 하나의 제목으로 두고, 원문 흐름을 유지하면서 한국어로 상세 해설을 붙인 정리본입니다.
수식은 Markdown의 LaTeX 수식 표기(
$...$,$$...$$)로 정리했습니다. GitHub/Obsidian/Typora/VS Code Markdown Preview 등 LaTeX 렌더링을 지원하는 뷰어에서 수식 형태로 확인할 수 있습니다.
Page 1.
Attention Alternatives and Mixture of Expert가 이번 강의의 주제입니다. 즉, Transformer의 핵심 병목인 attention 비용을 줄이는 방법과, 모델 파라미터 수를 크게 늘리면서도 계산량은 제한하는 MoE 구조를 다룹니다.
핵심 질문은 두 개 입니다.
- 첫째, context length가 길어질수록 attention 비용이 커지는 데, 이를 어떻게 줄일 것인가?
- 둘째, 모델을 크게 만들고 싶은데 모든 토큰이 모든 파라미터를 쓰면 너무 비싸므로, 일부만 선택적으로 쓰게 만들 수 있는가?
Page 2.
이 페이지는 왜 attention 대체 구조가 필요한가를 보여줍니다. LLM의 context window는 계속 길어지고 있습니다. 문제는 표준 self-attention의 계산량이 sequence length $n$에 대해 대략 $O(n^2)$로 증가한다는 점입니다.
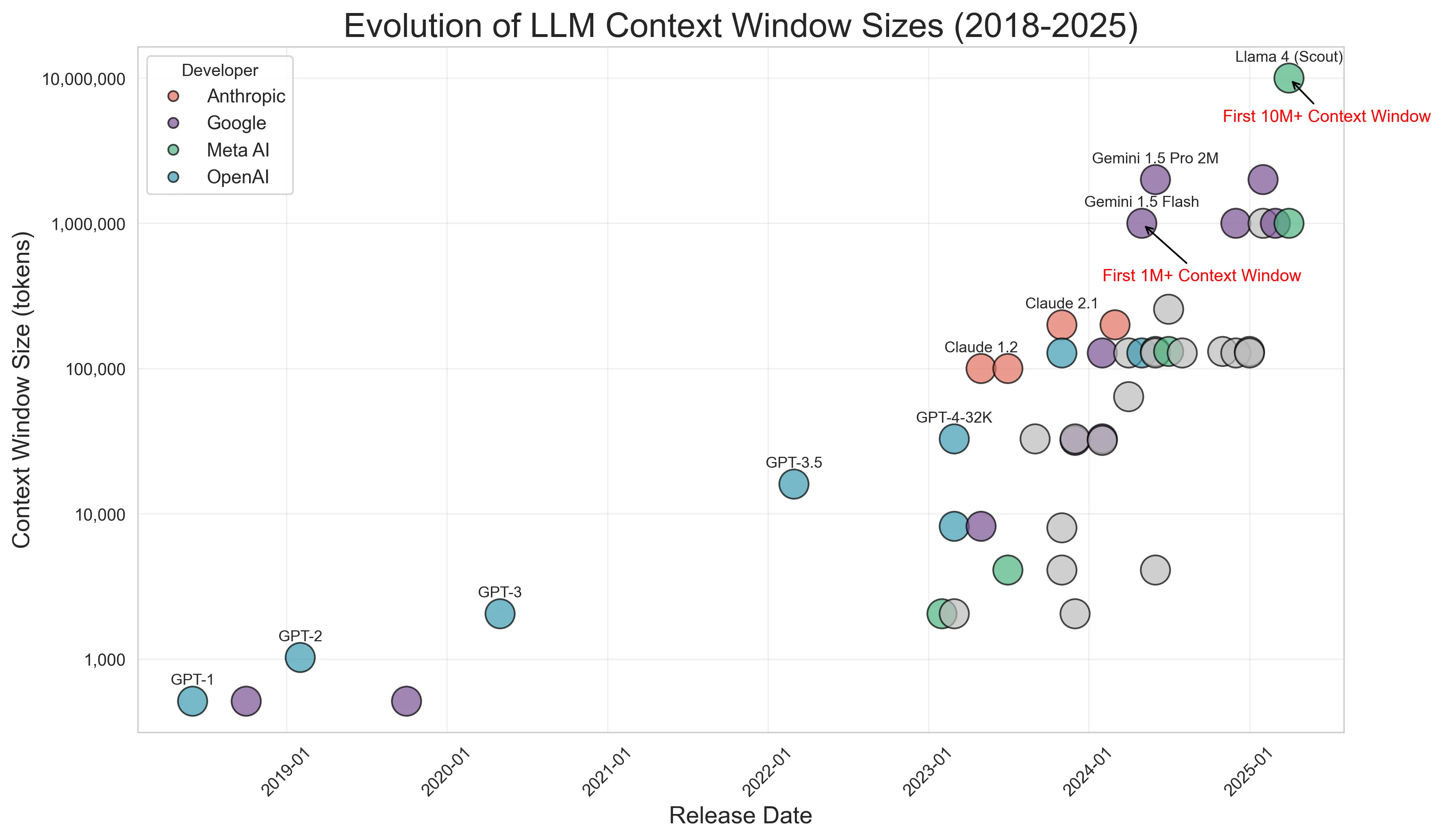
아래 그림을 보시면 아시겠지만 확실히 Attention이 시간 복잡도를 많이 잡아먹는다는 것을 알 수 있습니다.
예를 들어 토큰 길이가 2배가 되면 attention score matrix는 단순히 2배가 아니라 4배 가까이 커지게 됩니다. 그래서 context length가 길수록 attention이 memory와 compute의 핵심 병목이 됩니다.
이 페이지의 메시지는 단순합니다.
“긴 Context를 쓰고 싶은데, full attention을 그대로 쓰면 너무 비싸다. 그러면 attention을 더 싸게 만드는 구조가 필요하다”
Page 3. The basic toolkit
여기서는 attention 비용을 줄이는 기본 도구를 소개합니다. 크게 두 가지인데요.
첫째, local attention + global attention 조합입니다.
local attention은 각 토큰이 주변 토큰만 보는 방식입니다. 예를 들어 현재 토큰이 앞뒤 512개 토큰만 본다면 전체 $n^2$ attention보다 훨씬 쌉니다.
하지만 주면만 보면 멀리 떨어진 중요한 정보는 놓칠 수 있습니다. 그래서 일부 global token이나 global attention pattern을 섞습니다.
둘째, systems engineering입니다.
FlashAttention 같은 kernel-level 최적화가 여기에 해당합니다. attention 수식을 바꾸지 않더라도 GPU memory access를 최적화해서 훨씬 빠르게 만드는 방식입니다.
다만 슬라이드의 마지막 질문이 중요합니다.
“그런데 더 근본적이고 큰 이득을 얻고 싶다면??”
즉, local/global attention이나 FlashAttention만으로는 부족할 수 있으니, attention 자체를 다른 형태로 바꾸는 방법을 보자는 흐름입니다.
Page 4. Linear attention
Page 4의 출발점은 Transformer의 일반적인 attention 수식입니다.
\mathrm{Attn}(Q, K, V) = \rho\!\left(QK^\top\right)V
여기서 $Q, K, V$는 각각 query, key, value 행렬입니다.
Q \in \mathbb{R}^{n \times d_k}
K \in \mathbb{R}^{n \times d_k}
V \in \mathbb{R}^{n \times d_v}
각 기호의 의미는 다음과 같은데요.
-
$n$: sequence length, 즉 입력 토큰 개수
-
$d_k$: query/key vector의 차원
-
$d_v$: value vector의 차원
예를 들어 입력 문장이 1,000개의 토큰으로 이루어져 있으면 $n = 1000$입니다. 각 토큰은 모델 내부에서 query 벡터, key 벡터, value 벡터로 변환됩니다. 이때 query와 key는 서로 비교하기 위한 표현이고, value는 실제로 가져올 정보라고 볼 수 있습니다.
1. 기존 attention은 무엇을 계산하는가?
attention에서 가장 먼저 주목해야 할 부분은 다음 항입니다.
QK^\top
행렬의 크기를 보면 다음과 같습니다.
Q \in \mathbb{R}^{n \times d_k}, \qquad K^\top \in \mathbb{R}^{d_k \times n}
따라서 두 행렬을 곱하면:
QK^\top \in \mathbb{R}^{n \times n}
이 됩니다.
이 $n \times n$ 행렬은 모든 query token과 모든 key token 사이의 점수를 담은 attention score matrix입니다.
풀어 쓰면 다음과 같습니다:
QK^\top =
\begin{bmatrix}
q_1^\top k_1 & q_1^\top k_2 & \cdots & q_1^\top k_n \\
q_2^\top k_1 & q_2^\top k_2 & \cdots & q_2^\top k_n \\
\vdots & \vdots & \ddots & \vdots \\
q_n^\top k_1 & q_n^\top k_2 & \cdots & q_n^\top k_n
\end{bmatrix}
여기서 $q_i^\top k_j$는 “$i$번째 토큰이 $j$번째 토큰을 얼마나 참고할 것인가?”를 나타내는 점수입니다.
($q$에 전치를 한 것은 column 벡터로 표기하기 위함입니다.)
즉, standard attention은 모든 토큰 쌍을 직접 비교합니다.
1번 토큰의 query와 1번 토큰의 key 비교
1번 토큰의 query와 2번 토큰의 key 비교
...
1번 토큰의 query와 n번 토큰의 key 비교
2번 토큰의 query와 1번 토큰의 key 비교
...
n번 토큰의 query와 n번 토큰의 key 비교
총 비교 수는 $n \times n = n^2$개 입니다.. 그래서 sequence length가 길어질수록 attention의 비용은 빠르게 커지게 되는것 입니다.
2. 기존 attention의 계산량: 왜 $n^2d_k + n^2d_v$인가?
기존 attention을 단순화해서 다음과 같이 보면:
(QK^\top)V
먼저 $QK^\top$를 계산하고, 그 결과에 $V$를 곱하는 방식입니다.
Step 1. $QK^\top$ 계산
QK^\top = (n \times d_k)(d_k \times n)
결과 행렬의 크기는:
n \times n
이다.
행렬 곱셈 $(a \times b)(b \times c)$의 계산량은 대략 $abc$다. 따라서 $QK^\top$의 계산량은:
n \cdot d_k \cdot n = n^2d_k
입니다.
여기서 $n^2$은 query-key token pair의 개수이고, $d_k$는 각 pair의 dot product를 계산하는 데 필요한 벡터 차원입니다. 즉, score matrix 자체의 크기는 $n^2$이지만, 그 score들을 계산하는 연산량은 $n^2d_k$가 되는거죠.
Step 2. $(QK^\top)V$계산
이제 $QK^\top$의 결과는 $n \times n$ 행렬입니다. 여기에 $V$를 곱합니다.
(QK^\top)V = (n \times n)(n \times d_v)
결과 행렬의 크기는:
n \times d_v
입니다.
계산량은:
n \cdot n \cdot d_v = n^2d_v
입니다.
따라서 전체 계산량은 다음과 같습니다.
n^2d_k + n^2d_v
즉, sequence length $n$에 대해 quadratic하게 증가합니다. 이것이 긴 context에서 standard attention이 비싸지는 핵심 이유입니다.
3. 그러면 $\rho$는 무엇인가?
슬라이드의 식은 다음과 같았습니다.
\mathrm{Attn}(Q, K, V) = \rho\!\left(QK^\top\right)V
여기서 $\rho$는 $QK^\top$에 적용되는 어떤 함수라고 보면 됩니다. 일반적인 Transformer attention에서는 $\rho$가 사실상 softmax에 해당합니다.
일반적인 scaled dot-product attention은 다음과 같이 쓴다.
\mathrm{Attention}(Q,K,V)
=
\mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
즉, standard attention에서는 $QK^\top$를 계산한 뒤, 각 query token마다 key token들에 대한 score를 softmax로 확률처럼 정규화한다.
예를 들어 $i$번째 query에 대해:
[q_i^\top k_1, q_i^\top k_2, \ldots, q_i^\top k_n]
라는 점수 벡터가 있으면, softmax는 이것을 다음과 같은 attention distribution으로 바꿉니다.
[\alpha_{i1}, \alpha_{i2}, \ldots, \alpha_{in}]
그리고 이 가중치로 value들을 섞습니다.
y_i = \sum_{j=1}^{n} \alpha_{ij}v_j
따라서 softmax attention은 query마다 “어떤 token을 얼마나 볼지”를 매우 세밀하게 정할 수 있다.
4. 그런데 왜 갑자기 $\rho$를 identity로 두는가?
Page 4에서 가장 헷갈릴 수 있는 지점이 바로 이것입니다. 슬라이드는 갑자기 “$\rho$가 identity라고 해보자”는 가정을 둡니다.
identity function이란 입력을 그대로 내보내는 함수입니다:
\rho(x) = x
따라서 $\rho$가 identity라면:
\rho\!\left(QK^\top\right) = QK^\top
이 됩니다. 그러면 attention 식은 다음처럼 단순해집니다.
\mathrm{Attn}(Q,K,V) = QK^\top V
이 가정은 “실제 Transformer attention에서 softmax를 없애도 된다”는 뜻이 아닙니다. 여기서는 먼저 attention을 선형 연산처럼 볼 수 있다면 어떤 일이 가능해지는지 보여주기 위한 출발점이라고 볼 수 있습니다.
즉, 슬라이드가 하고 싶은 말은 다음과 같습니다.
softmax 같은 비선형 함수가 중간에 있으면 행렬 곱셈 순서를 마음대로 바꿀 수 없다. 하지만 $\rho$가 identity라면 전체 식이 순수한 행렬 곱셈이 되므로, 행렬 곱셈의 결합법칙을 적용할 수 있다.
따라서 $\rho$를 identity로 두는 이유는 계산을 단순화하기 위해서가 아니라, linear attention이 왜 가능한지 보여주는 수학적 구조를 드러내기 위해서다.
5. 결합법칙을 적용하면 무엇이 달라지는가?
$\rho$가 identity라면 attention 식은 다음과 같습니다.
QK^\top V
행렬 곱셈은 결합법칙을 만족하므로 다음 두 방식은 수학적으로 같은 결과를 냅니다.
(QK^\top)V = Q(K^\top V)
하지만 두 방식의 계산 비용은 크게 다릅니다.
6. 기존 방식: $(QK^\top)V$
기존 방식은 먼저 $QK^\top$를 계산합니다.
QK^\top = (n \times d_k)(d_k \times n)
결과는:
n \times n
이다. 이 시점에서 이미 $n^2$ 크기의 attention score matrix를 만듭니다.
그다음:
(QK^\top)V = (n \times n)(n \times d_v)
를 계산합니다.
전체 계산량은:
n^2d_k + n^2d_v
입니다.
7. 순서를 바꾼 방식: $Q(K^\top V)$
이제 결합법칙을 이용해 먼저 $K^\top V$를 계산해봅시다.
K^\top V = (d_k \times n)(n \times d_v)
결과는:
d_k \times d_v
이다.
여기서 중요한 점은 중간 결과가 $n \times n$이 아니라 $d_k \times d_v$라는 것입니다.
기존 방식에서는 token 수 $n$이 커질수록 중간 행렬이 $n^2$로 커졌습니다. 하지만 순서를 바꾼 방식에서는 중간 행렬 크기가 $d_kd_v$입니다. 일반적으로 $d_k$, $d_v$는 모델 차원에 의해 정해지는 값이고, sequence length $n$처럼 수만, 수십만까지 커지는 값은 아닙니다.
$K^\top V$의 계산량은:
nd_kd_v
입니다.
그다음 $Q$를 곱한다.
Q(K^\top V) = (n \times d_k)(d_k \times d_v)
결과는:
n \times d_v
입니다.
계산량은:
nd_kd_v
입니다.
따라서 전체 계산량은:
nd_kd_v + nd_kd_v = 2nd_kd_v
입니다.
즉, 기존의:
n^2d_k + n^2d_v
에서:
2nd_kd_v
로 바뀝니다.
이제 비용은 sequence length $n$에 대해 quadratic이 아니라 linear하게 증가합니다.
9. 이게 왜 linear attention인가?
기존 attention은 $QK^\top$를 직접 만들기 때문에 $n \times n$ token-pair matrix가 생긴다. 따라서 sequence length $n$에 대해 $O(n^2)$ 비용이 듭니다.
반면 결합법칙을 이용해 $K^\top V$를 먼저 계산하면, 중간에 $n \times n$ 행렬을 만들지 않습니다. 대신 $d_k \times d_v$ 크기의 압축된 state를 만듭니다.
S = K^\top V
그 후 query가 이 state를 읽는다면?
Y = QS
이때 전체 비용은 $2nd_kd_v$이므로, sequence length $n$에 대해 선형적으로 증가한다. 그래서 이 계열의 아이디어를 linear attention이라고 부릅니다.
직관적으로 보면 무엇이 바뀐 것일까요?
standard attention은 각 query token이 모든 key token을 직접 만납니다.
각 query가 모든 key와 직접 비교한다. 그래서 query-key pair score를 전부 만든다.
반면 linear attention은 먼저 모든 key-value 정보를 하나의 matrix에 모읍니다.
S = K^\top V
이를 풀어 쓰면:
S = \sum_{j=1}^{n} k_j v_j^\top
입니다.
즉, 각 token의 key-value 정보를 하나의 state에 누적합니다. 그 다음 각 query는 이 state를 읽습니다.
y_i = q_i^\top S
다시 말해, standard attention은 “각 query가 모든 token을 직접 비교하는 방식”이고, linear attention은 “전체 key-value 정보를 먼저 압축한 뒤, query가 그 압축 state를 읽는 방식”입니다.
이 차이 때문에 linear attention은 $n \times n$ attention score matrix를 만들지 않아도 됩니다..
10. 다만 이것은 softmax attention과 동일한가?
아닙니다. 이 점이 매우 중요한데요.
Page 4의 단순한 결합법칙 변형은 $\rho$가 identity일 때만 성립합니다. 즉:
\rho(x)=x
일 때:
\rho(QK^\top)V = QK^\top V = Q(K^\top V)
가 가능합니다.
하지만 일반 Transformer의 softmax attention은:
\mathrm{softmax}(QK^\top)V
형태이므로 그대로는:
Q(K^\top V)
로 바꿀 수 없습니다.
따라서 Page 4의 설명은 “standard attention을 그대로 빠르게 계산하는 방법”이라기보다는, “attention을 선형 형태로 바꾸면 어떤 계산 이득이 생기는가”를 보여주는 출발점입니다.
실제 linear attention 연구들은 softmax attention을 완전히 버리거나, kernel feature map 등을 사용해 softmax attention과 비슷한 효과를 내면서도 선형 형태로 계산할 수 있도록 설계합니다.
Page 5. Recurrent Form of Linear Attention
Page 5는 Page 4에서 본 linear attention 식이 어떻게 recurrent state update 형태로 바뀌는지를 설명합니다.
Page 4에서는 전체 sequence에 대해 다음과 같은 식을 봤습니다.
Y = Q(K^\top V)
여기서:
S = K^\top V
라고 두면:
Y = QS
입니다.
Page 5는 이 $S$를 한 번에 계산하는 대신, token이 들어올 때마다 조금씩 업데이트하는 방식으로 다시 씁니다.
1. $K^\top V$를 풀어 쓰기
먼저 $K^\top V$가 무엇인지 다시 봅시다.
$K$는 모든 token의 key를 모아놓은 행렬이고, $V$는 모든 token의 value를 모아놓은 행렬입니다.
K =
\begin{bmatrix}
- & k_1^\top & - \\
- & k_2^\top & - \\
& \vdots & \\
- & k_n^\top & -
\end{bmatrix}
V =
\begin{bmatrix}
- & v_1^\top & - \\
- & v_2^\top & - \\
& \vdots & \\
- & v_n^\top & -
\end{bmatrix}
그렇다면:
K^\top V
는 다음처럼 쓸 수 있다.
K^\top V = \sum_{t=1}^{n} k_t v_t^\top
여기서 $k_t v_t^\top$는 outer product다.
$k_t \in \mathbb{R}^{d_k}$, $v_t \in \mathbb{R}^{d_v}$라면:
k_t v_t^\top \in \mathbb{R}^{d_k \times d_v}
입니다.
즉, 각 token은 자기 자신의 key-value 정보를 $d_k \times d_v$ matrix 형태로 state에 더하게 됩니다.
2. recurrent state $S_t$ 정의
Page 5에서는 다음과 같은 state를 정의합니다.
S_t = S_{t-1} + k_t v_t^\top
이 식의 의미는 간단합니다.
-
$S_{t-1}$: $t-1$번째 token까지 누적된 key-value memory
-
$k_t v_t^\top$: 현재 $t$번째 token이 새로 추가하는 key-value 정보
-
$S_t$: $t$번째 token까지 반영된 새로운 memory
초기 상태를 $S_0 = 0$이라고 하면:
S_1 = k_1v_1^\top
S_2 = S_1 + k_2v_2^\top = k_1v_1^\top + k_2v_2^\top
S_3 = S_2 + k_3v_3^\top = k_1v_1^\top + k_2v_2^\top + k_3v_3^\top
따라서 일반적으로:
S_t = \sum_{i=1}^{t} k_i v_i^\top
입니다.
즉, $S_t$는 현재 시점 $t$까지의 모든 key-value 정보를 누적한 state다.
3. 출력 $y_t$는 어떻게 계산되는가?
Page 5의 두 번째 식은 다음과 같습니다.
y_t = q_t^\top S_t
여기서:
-
$q_t$: 현재 token의 query
-
$S_t$: 현재 시점까지 누적된 key-value state
-
$y_t$: 현재 token의 attention output
즉, 현재 query $q_t$가 지금까지 누적된 memory $S_t$를 읽어서 output $y_t$를 만듭니다.
이를 풀어 쓰면:
y_t = q_t^\top \left(\sum_{i=1}^{t} k_i v_i^\top\right)
분배법칙을 적용하면:
y_t = \sum_{i=1}^{t} (q_t^\top k_i)v_i^\top
이 식을 보면, linear attention의 recurrent form도 과거 token들의 value를 조합한다는 점은 standard attention과 유사합니다. 다만 차이는 $q_t$가 모든 $k_i$와의 점수를 하나씩 명시적으로 계산해서 attention score vector를 만드는 것이 아니라, 이미 누적된 state $S_t$를 읽는다는 점입니다.
4. 왜 recurrent form이 중요한가?
recurrent form이 중요한 이유는 inference 효율성 때문입니다.
standard attention에서는 새로운 token을 생성할 때마다 현재 query가 과거의 모든 key와 attention을 해야 한다. KV cache를 사용하더라도, 현재 token의 query는 과거 token들의 key와 모두 dot product를 수행해야 합니다.
즉, autoregressive decoding에서 $t$번째 token을 생성할 때 현재 token은 현재까지의 $t$개의 token을 본다. 그래서 token이 길어질수록 step당 attention 비용이 증가합니다.
반면 linear attention의 recurrent form에서는 과거 key-value 정보를 모두 $S_{t-1}$에 누적해두었습니다.
새 token이 들어오면 다음 두 단계만 수행하면 되는거죠.
- state 업데이트
S_t = S_{t-1} + k_t v_t^\top
- 현재 query로 state 읽기
y_t = q_t^\top S_t
이때 과거 token 전체를 다시 훑을 필요가 없습니다. 과거 정보는 이미 $S_t$에 압축되어 있기 때문입니다.
따라서 inference 시에는 sequence length가 길어져도 매 step에서 유지해야 하는 것은 전체 과거 token pair matrix가 아니라 fixed-size state $S_t$다.
5. 그럼 training도 recurrent하게 해야 하는가?
반드시 그렇지는 않습니다. 이 점이 중요합니다.
linear attention 계열의 장점은 두 가지 관점으로 볼 수 있다는 것인데요.
병렬 형태
전체 sequence를 한 번에 처리할 때는 Page 4처럼 쓸 수 있습니다.
Y = Q(K^\top V)
이 방식은 GPU에서 병렬 계산하기 좋다.
recurrent 형태
autoregressive inference에서는 Page 5처럼 쓸 수 있습니다.
S_t = S_{t-1} + k_t v_t^\top
y_t = q_t^\top S_t
이 방식은 token을 하나씩 생성할 때 효율적입니다.
즉, linear attention은 training에서는 병렬화가 가능하고, inference에서는 recurrent state로 효율적으로 계산할 수 있는 구조를 제공합니다.
6. causal attention과의 관계
언어 모델은 보통 causal attention을 사용합니다. 즉, 현재 token은 미래 token을 볼 수 없고 과거 token만 볼 수 있습니다.
Page 5의 recurrent form은 causal 구조와 자연스럽게 맞습니다.
왜냐하면 $S_t$가 다음처럼 정의되기 때문입니다.
S_t = \sum_{i=1}^{t} k_i v_i^\top
즉, $S_t$에는 $1$번부터 $t$번 token까지의 정보만 들어 있다. 미래 token인 $t+1$, $t+2$의 정보는 아직 state에 들어가지 않습니다.
따라서:
y_t = q_t^\top S_t
는 현재 token이 현재까지의 정보만 읽는 causal attention 형태로 해석할 수 있습니다.
7. Page 5의 한계도 이해해야 합니다.
Page 5의 recurrent form은 매우 효율적이지만, standard softmax attention과 완전히 같은 것은 아닙니다.
standard attention은 query마다 과거 token들에 대한 개별 attention distribution을 만듭니다. 그래서 특정 token 하나를 강하게 선택하거나, 문맥에 따라 매우 sharp한 attention pattern을 만들 수 있습니다.
반면 linear attention은 과거 정보를 $S_t$라는 fixed-size state에 누적합니다. 이 과정에서 개별 token의 정보가 압축되므로, token-level pairwise 관계를 standard attention만큼 세밀하게 보존하기 어렵습니다.
그래서 실제 모델에서는 linear attention만 단독으로 쓰기보다는, 일부 full attention layer를 섞거나, gating, decay, state update 개선 등을 추가하는 경우가 많습니다.
이 흐름이 이후 슬라이드의 RetNet, Mamba-2, Gated Delta Net, hybrid architecture로 이어집니다.
Page 6. Minimax M1
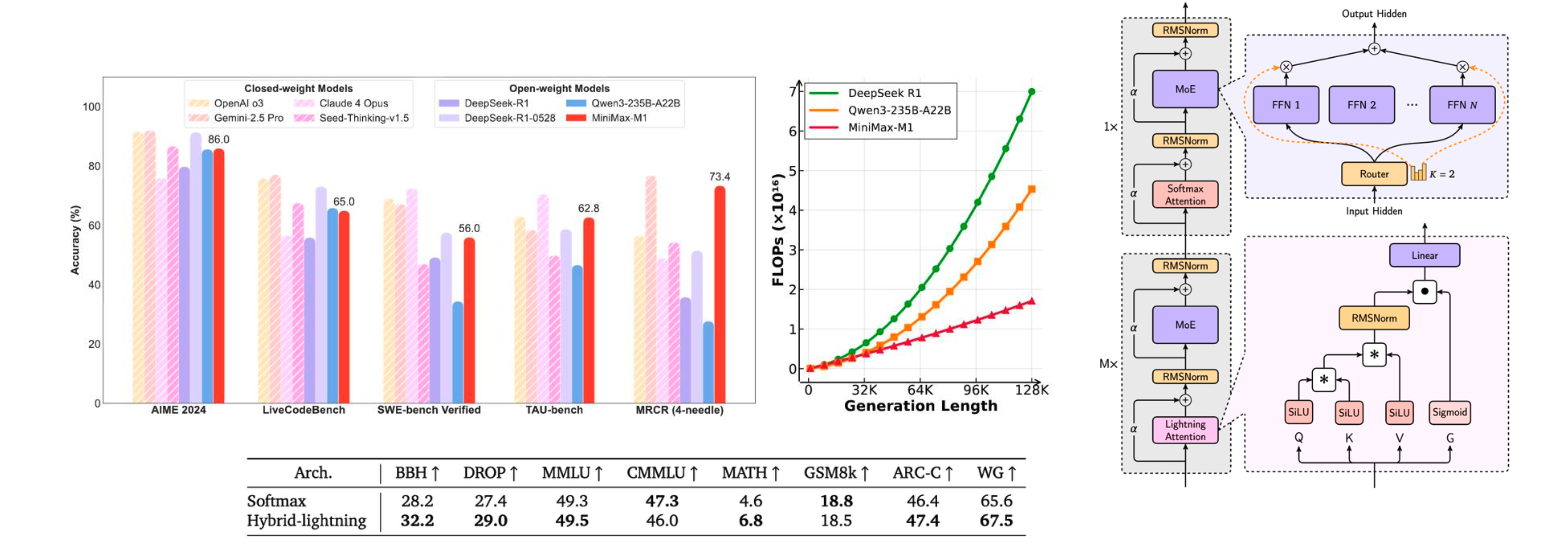
MiniMax M1은 linear attention과 full attention을 섞은 hybrid 구조 예시입니다.
슬라이드에서는 MiniMax M1이 7-to-1 hybrid, 즉 linear attention layer 7개에 full attention layer 1개 정도를 섞는다고 설명합니다..
왜 full attention을 완전히 버리지 않을까요?
linear attention은 효율적이지만, 모든 token pair를 직접 비교하는 full attention보다 표현력이 약할 수 있습니다. 그래서 대부분은 “전부 linear로 바꾸자”가 아니라, “대부분은 linear로 싸게 처리하고, 일부 layer에서는 full attention으로 전역 상호작용을 보완하자”는 방식으로 갑니다.
이 페이지의 핵심은 다음입니다.
attention을 완전히 제거하기보다는, linear attention과 full attention을 적절히 섞으면 long-context 효율성과 성능을 동시에 노릴 수 있다.
Page7. From linear attention to Mamba-2
Page 7은 Page 5에서 본 linear attention의 recurrent form을 조금 더 일반화해서, Mamba-2와 어떻게 연결되는지를 설명하는 페이지입니다.
먼저 Page 5에서 본 linear attention의 recurrent form을 다시 보면 다음과 같습니다.
S_t = S_{t-1} + k_t v_t^\top
y_t = q_t^\top S_t
여기서 $S_t$는 현재 시점 $t$까지 누적된 key-value memory입니다.
즉, 매 token마다 $k_t v_t^\top$를 state에 계속 더하고, 현재 query $q_t$가 그 state를 읽어서 output $y_t$를 만드는 구조입니다.
하지만 이 방식에는 한 가지 한계가 있습니다.
기본 linear attention에서는 과거 정보가 계속 단순히 누적됩니다.
S_t = S_{t-1} + k_t v_t^\top
즉, 한 번 들어온 정보는 계속 state 안에 남아 있습니다.
물론 이것은 계산 효율성 측면에서는 좋지만, 표현력 측면에서는 부족할 수 있습니다.
왜냐하면 실제 언어 모델에서는 모든 과거 정보를 똑같이 계속 유지할 필요가 없기 때문입니다.
예를 들어 어떤 정보는 오래 유지해야 하고, 어떤 정보는 현재 문맥에서는 더 이상 중요하지 않을 수 있습니다.
따라서 모델 입장에서는 다음과 같은 능력이 필요합니다.
“과거 정보를 무조건 누적하는 것이 아니라, 필요한 정보는 유지하고 필요 없는 정보는 약하게 만들거나 지우고 싶다.”
이 아이디어를 반영한것이 Mamba-2 형태입니다.
슬라이드에서는 Mamba-2를 다음과 같이 표현합니다.
S_t = \gamma_t S_{t-1} + k_t v_t^\top
y_t = q_t^\top S_t + v_t^\top D
\gamma_t = f(x_t)
여기서 새롭게 등장한 중요한 항은 $\gamma_t$입니다.
$\gamma_t$는 이전 state $S_{t-1}$를 얼마나 유지할지 결정하는 gate입니다.
즉, $\gamma_t$는 과거 memory에 곱해지는 가중치라고 볼 수 있습니다.
만약 $\gamma_t$가 1에 가까우면 다음과 같습니다.
S_t \approx S_{t-1} + k_t v_t^\top
이 경우 과거 state를 거의 그대로 유지합니다.
반대로 $\gamma_t$가 0에 가까우면 다음과 같습니다.
S_t \approx k_t v_t^\top
이 경우 과거 state의 영향이 거의 사라집니다.
즉, $\gamma_t$는 일종의 forget gate 또는 decay gate처럼 동작합니다.
중요한 점은 $\gamma_t$가 고정된 값이 아니라는 것입니다.
\gamma_t = f(x_t)
즉, 현재 입력 $x_t$를 보고 모델이 $\gamma_t$를 결정합니다.
그래서 Mamba-2에서는 token마다 “이전 state를 얼마나 유지할지”를 다르게 조절할 수 있습니다.
이를 직관적으로 말하면 다음과 같습니다.
linear attention은 과거 정보를 계속 더하는 구조이고, Mamba-2는 과거 정보를 얼마나 유지할지 gate를 통해 조절하는 구조입니다.
또 하나의 항은 다음 부분입니다.
v_t^\top D
이 항은 현재 token의 value 정보를 output에 직접 반영하는 역할을 합니다.
Mamba-2 같은 recurrent/state-space 구조에서는 정보가 state $S_t$를 통해 전달됩니다.
그런데 모든 정보를 state에 넣고 다시 읽어오게 만들면, 현재 token의 local information이 약해질 수 있습니다.
그래서 현재 입력에서 바로 output으로 가는 경로를 하나 둡니다.
즉, state $S_t$를 통해 누적 memory를 읽는 경로와 별개로, 현재 입력 자체를 output에 직접 전달하는 skip connection 또는 direct path처럼 볼 수 있습니다.
따라서 Mamba-2의 출력은 크게 두 부분으로 구성됩니다.
-
$q_t^\top S_t$: 누적된 state에서 읽어온 정보
-
$v_t^\top D$: 현재 token에서 직접 온 정보
이 구조는 단순한 linear attention보다 더 표현력이 좋습니다.
기본 linear attention은 다음처럼 과거 정보를 계속 누적합니다.
S_t = S_{t-1} + k_t v_t^\top
하지만 Mamba-2는 다음처럼 과거 정보를 조절합니다.
S_t = \gamma_t S_{t-1} + k_t v_t^\top
즉, Mamba-2는 linear attention에 input-dependent gating을 추가한 형태라고 이해할 수 있습니다.
여기서 슬라이드의 핵심 메시지는 다음입니다.
linear attention은 계산 효율성이 좋지만 표현력이 제한될 수 있습니다.
Mamba-2는 여기에 gating을 추가해서 어떤 정보를 유지하고 어떤 정보를 약화할지 조절함으로써 표현력을 높입니다.
그리고 이 구조의 장점은 Page 5에서 본 duality를 어느 정도 유지한다는 점입니다.
즉, training할 때는 병렬적으로 계산할 수 있고, inference할 때는 recurrent state를 이용해 효율적으로 계산할 수 있습니다.
정리하면 Page 7의 핵심은 다음과 같습니다.
Mamba-2는 linear attention의 recurrent state 구조를 기반으로 하되, $\gamma_t$라는 gate를 통해 과거 state를 선택적으로 유지하거나 잊게 만든 구조입니다.
따라서 linear attention보다 더 유연하고 expressive한 long-context 모델링이 가능합니다.
Page 8. Nemotron 3
Page 8은 Nemotron 3를 예시로 들어, 실제 모델들이 linear attention 계열 구조와 full attention을 어떻게 섞는지를 보여줍니다.
슬라이드의 핵심 문장은 다음입니다.
Mamba attention hybrid, roughly 3-to-1.
즉, Nemotron 3는 Mamba 계열 layer와 full attention layer를 섞은 hybrid architecture입니다.
여기서 3-to-1이라는 말은 대략적으로 다음과 같은 구조를 의미합니다.
Mamba layer
Mamba layer
Mamba layer
Full attention layer
Mamba layer
Mamba layer
Mamba layer
Full attention layer
...
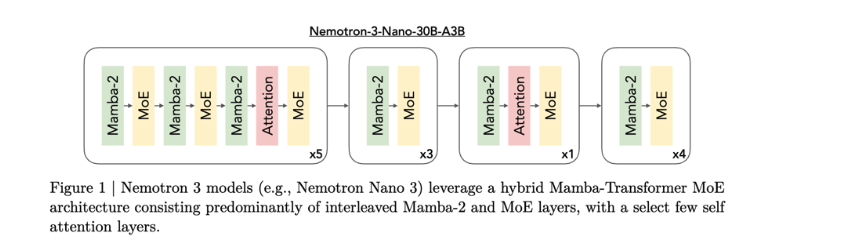
즉, 모든 layer를 full attention으로 구성하지 않고, 대부분은 Mamba 계열의 효율적인 recurrent/state-space layer로 처리합니다.
그리고 일정한 간격마다 full attention layer를 넣어줍니다.
왜 이렇게 할까요?
이유는 linear attention이나 Mamba 계열 구조가 효율적이기는 하지만, full attention만큼 모든 token pair의 관계를 직접적으로 모델링하지는 못하기 때문입니다.
full attention은 다음과 같이 모든 token pair를 직접 비교합니다.
QK^\top \in \mathbb{R}^{n \times n}
즉, 각 token이 다른 모든 token과 직접 상호작용할 수 있습니다.
반면 Mamba나 linear attention 계열은 과거 정보를 state에 압축해서 저장합니다.
이 방식은 효율적이지만, token-level pairwise interaction을 full attention만큼 세밀하게 보존하기는 어렵습니다.
따라서 실제 모델에서는 다음과 같은 절충을 선택합니다.
대부분의 layer는 Mamba/linear attention 계열로 싸게 처리하고, 일부 layer에서는 full attention을 사용해서 전역적인 token 간 상호작용을 보완합니다.
이것이 hybrid architecture의 핵심입니다.
Page 6의 MiniMax M1도 비슷한 흐름이었습니다.
MiniMax M1은 7-to-1 hybrid, 즉 linear attention layer 7개에 full attention layer 1개를 섞는 구조였습니다.
Nemotron 3는 이와 유사하게 Mamba와 attention을 섞습니다.
다만 슬라이드에서는 대략 3-to-1 정도의 비율을 언급합니다.
이 페이지에서 중요한 점은 다음입니다.
최근 long-context 모델들은 full attention을 완전히 버리기보다는, 효율적인 state-based layer와 full attention layer를 섞는 방향으로 가고 있습니다.
이 방식의 장점은 명확합니다.
첫째, inference 효율성이 좋아집니다.
Mamba 계열 layer는 recurrent state를 활용할 수 있기 때문에 긴 context에서도 full attention보다 더 효율적으로 동작할 수 있습니다.
둘째, 성능 저하를 줄일 수 있습니다.
일부 full attention layer가 남아 있기 때문에, 모델이 token 간 직접적인 상호작용을 완전히 잃지는 않습니다.
따라서 Nemotron 3는 다음과 같은 설계 철학을 보여줍니다.
“모든 layer에서 full attention을 쓰는 것은 비쌉니다. 하지만 full attention을 완전히 제거하면 성능이 떨어질 수 있습니다.
그러므로 Mamba 계열 layer와 full attention layer를 적절히 섞습니다.”
정리하면 Page 8의 핵심은 다음입니다.
Nemotron 3는 Mamba와 full attention을 섞은 hybrid model입니다. 대부분의 계산은 효율적인 Mamba layer가 담당하고, 일부 layer에서 full attention을 사용해 표현력을 보완합니다.
Page 9. Gated Delta Net
Page 9는 Gated Delta Net을 설명하는 페이지입니다.
앞에서 본 linear attention과 Mamba-2가 “과거 정보를 state에 누적하고, 현재 query가 그 state를 읽는 구조”였다면, Gated Delta Net은 여기서 한 단계 더 나아가 state에 무엇을 쓸지, 무엇을 지울지까지 조절하는 구조입니다.
1. 출발점: linear attention의 state update
먼저 linear attention의 recurrent form을 다시 보겠습니다.
S_t = S_{t-1} + k_t v_t^\top
y_t = q_t^\top S_t
여기서 $S_t$는 현재 시점 $t$까지의 key-value 정보를 누적한 memory state입니다.
이를 풀어 쓰면 다음과 같습니다.
S_t = \sum_{i=1}^{t} k_i v_i^\top
즉, 각 token이 자기 자신의 key-value 정보를 $k_i v_i^\top$ 형태로 state에 계속 더합니다.
이 구조는 효율적입니다. 하지만 단점도 있습니다.
과거 정보가 계속 단순히 누적되기 때문에, 새로운 정보가 들어왔을 때 기존 정보를 선택적으로 지우거나 갱신하기 어렵습니다.
예를 들어 어떤 key 방향에 대해 예전 value가 이미 저장되어 있는데, 나중에 같은 key 방향에 더 적절한 value가 들어왔다고 해보겠습니다.
단순 linear attention에서는 기존 정보를 지우지 않고 새 정보를 그냥 더합니다.
즉, memory가 다음처럼 계속 쌓입니다.
old memory + new memory
이 경우 비슷한 key 방향에 여러 value가 섞여 저장될 수 있습니다.
그래서 나중에 query가 그 방향을 읽을 때, 과거 정보와 현재 정보가 섞여 나올 수 있습니다.
2. Mamba-2는 무엇을 추가했는가?
Mamba-2는 linear attention의 단순 누적 구조에 gate를 추가합니다.
S_t = \gamma_t S_{t-1} + k_t v_t^\top
y_t = q_t^\top S_t + v_t^\top D
여기서 $\gamma_t$는 이전 state를 얼마나 유지할지 결정하는 gate입니다.
만약 $\gamma_t$가 1에 가까우면 과거 state를 거의 그대로 유지합니다.
S_t \approx S_{t-1} + k_t v_t^\top
반대로 $\gamma_t$가 0에 가까우면 과거 state를 거의 잊고 현재 정보 중심으로 state를 구성합니다.
S_t \approx k_t v_t^\top
즉, Mamba-2는 과거 state 전체를 얼마나 유지할지 조절할 수 있습니다.
하지만 여전히 한계가 있습니다.
Mamba-2의 $\gamma_t$는 state 전체에 곱해지는 gate입니다.
따라서 특정 key 방향의 정보만 골라서 지우는 구조는 아닙니다.
3. Gated Delta Net의 핵심 수식
Gated Delta Net은 다음과 같은 state update를 사용합니다.
S_t = \gamma_t (I - \beta_t k_t k_t^\top) S_{t-1} + \beta_t k_t v_t^\top
출력은 다음과 같습니다.
y_t = q_t^\top S_t
그리고 gate들은 현재 입력에 의해 결정됩니다.
\gamma_t = f(x_t)
\beta_t = f(x_t)
여기서 새롭게 중요한 값은 $\beta_t$입니다.
$\gamma_t$는 Mamba-2처럼 과거 state 전체를 얼마나 유지할지 조절하는 gate입니다.
반면 $\beta_t$는 현재 입력을 state에 얼마나 쓸지, 그리고 현재 key 방향의 과거 정보를 얼마나 지울지를 조절하는 gate입니다.
4. 식을 두 부분으로 나눠서 보기
Gated Delta Net의 state update는 두 부분으로 나눠서 이해하면 쉽습니다.
S_t = \underbrace{\gamma_t (I - \beta_t k_t k_t^\top) S_{t-1}}_{\text{erase old memory}} + \underbrace{\beta_t k_t v_t^\top}_{\text{write new memory}}
첫 번째 항은 기존 memory를 수정하는 부분입니다.
\gamma_t (I - \beta_t k_t k_t^\top) S_{t-1}
두 번째 항은 현재 token의 key-value 정보를 새로 쓰는 부분입니다.
\beta_t k_t v_t^\top
즉, Gated Delta Net은 단순히 memory를 누적하지 않습니다.
1. 현재 key 방향과 관련된 과거 memory를 일부 지웁니다.
2. 현재 key-value 정보를 새로 씁니다.
그래서 Gated Delta Net은 erase-and-write memory update로 이해할 수 있습니다.
5. $k_t k_t^\top$는 왜 projection처럼 볼 수 있는가?
가장 헷갈리는 부분은 다음 항입니다.
k_t k_t^\top
이 행렬은 현재 key $k_t$ 방향에 해당하는 성분을 뽑아내는 projection matrix처럼 볼 수 있습니다.
이 말을 이해하려면 먼저 벡터 projection을 생각해야 합니다.
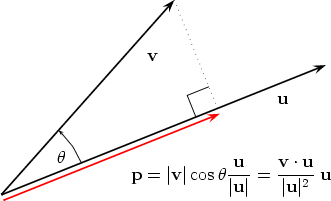
어떤 벡터 $x$가 있고, 특정 방향 벡터 $k$가 있다고 하겠습니다.
x \in \mathbb{R}^{d_k}
k \in \mathbb{R}^{d_k}
우리가 알고 싶은 것은 다음입니다.
$x$ 안에 $k$ 방향 성분이 얼마나 들어 있는가?
만약 $k$가 길이 1인 unit vector라면, $x$를 $k$ 방향으로 projection한 결과는 다음입니다.
\mathrm{proj}_k(x) = k(k^\top x)
여기서 $k^\top x$는 scalar입니다.
즉, $x$가 $k$ 방향과 얼마나 비슷한지를 나타내는 값입니다.
그리고 그 scalar를 다시 $k$에 곱하면, $k$ 방향 위에 놓인 벡터가 됩니다.
행렬 곱셈 관점에서 보면 다음과 같습니다.
k(k^\top x) = (kk^\top)x
따라서 $kk^\top$는 어떤 벡터 $x$가 들어왔을 때, 그 벡터에서 $k$ 방향 성분만 뽑아내는 행렬처럼 동작합니다.
6. 2차원 예시로 보기
예를 들어 $k$가 x축 방향이라고 하겠습니다.
k =
\begin{bmatrix}
1 \\
0
\end{bmatrix}
그러면 $kk^\top$는 다음과 같습니다.
kk^\top =
\begin{bmatrix}
1 \\
0
\end{bmatrix}
\begin{bmatrix}
1 & 0
\end{bmatrix}
=
\begin{bmatrix}
1 & 0 \\
0 & 0
\end{bmatrix}
이제 어떤 벡터 $x$가 있다고 하겠습니다.
x =
\begin{bmatrix}
3 \\
5
\end{bmatrix}
여기에 $kk^\top$를 곱하면 다음과 같습니다.
kk^\top x =
\begin{bmatrix}
1 & 0 \\
0 & 0
\end{bmatrix}
\begin{bmatrix}
3 \\
5
\end{bmatrix}
=
\begin{bmatrix}
3 \\
0
\end{bmatrix}
원래 벡터 $x$는 x축 성분 3과 y축 성분 5를 가지고 있었습니다.
그런데 $kk^\top x$를 계산하니 x축 성분만 남고 y축 성분은 사라졌습니다.
즉, $kk^\top$는 $k$ 방향 성분만 뽑아내는 역할을 합니다.
그래서 $k_t k_t^\top$를 현재 key $k_t$ 방향의 성분을 뽑아내는 projection-like matrix라고 말할 수 있습니다.
7. 왜 “normalize되어 있으면” 정확한 projection인가?
정확한 projection matrix는 사실 다음과 같습니다.
\frac{kk^\top}{k^\top k}
여기서 $k^\top k$는 $k$의 길이 제곱입니다.
만약 $k$가 unit vector라면:
k^\top k = 1
이므로 다음이 됩니다.
\frac{kk^\top}{k^\top k} = kk^\top
따라서 $k$가 normalize되어 있으면 $kk^\top$ 자체가 정확한 projection matrix입니다.
하지만 $k$가 normalize되어 있지 않으면 $kk^\top$는 정확한 projection이 아니라, $k$ 방향 성분을 뽑으면서 크기도 함께 스케일링하는 연산이 됩니다.
그래서 엄밀히 말하면 $k_t k_t^\top$는 항상 정확한 projection matrix라고 말하기보다는, projection-like operator라고 보는 것이 안전합니다.
8. $I - \beta_t k_t k_t^\top$는 무엇을 하는가?
이제 다음 항을 보겠습니다.
I - \beta_t k_t k_t^\top
먼저 $I$는 identity matrix입니다.
즉, 아무것도 바꾸지 않는 행렬입니다.
Ix = x
반면 $k_t k_t^\top$는 현재 key $k_t$ 방향의 성분을 뽑아내는 행렬처럼 동작합니다.
따라서 $I - k_t k_t^\top$는 $k_t$ 방향 성분을 제거하는 연산처럼 볼 수 있습니다.
앞의 2차원 예시에서:
k =
\begin{bmatrix}
1 \\
0
\end{bmatrix}
이면:
kk^\top =
\begin{bmatrix}
1 & 0 \\
0 & 0
\end{bmatrix}
입니다.
그러면:
I - kk^\top =
\begin{bmatrix}
1 & 0 \\
0 & 1
\end{bmatrix}
-
\begin{bmatrix}
1 & 0 \\
0 & 0
\end{bmatrix}
=
\begin{bmatrix}
0 & 0 \\
0 & 1
\end{bmatrix}
여기에 $x = [3, 5]^\top$를 곱하면:
(I - kk^\top)x =
\begin{bmatrix}
0 & 0 \\
0 & 1
\end{bmatrix}
\begin{bmatrix}
3 \\
5
\end{bmatrix}
=
\begin{bmatrix}
0 \\
5
\end{bmatrix}
즉, $k$ 방향인 x축 성분은 제거되고, 나머지 성분만 남습니다.
따라서:
I - k_t k_t^\top
는 현재 key 방향의 정보를 제거하는 연산으로 이해할 수 있습니다.
여기에 $\beta_t$가 붙으면, 제거 강도를 조절할 수 있습니다.
I - \beta_t k_t k_t^\top
-
$\beta_t = 0$이면 아무것도 지우지 않습니다.
-
$\beta_t = 1$이면 현재 key 방향 성분을 강하게 지웁니다.
-
$0 < \beta_t < 1$이면 현재 key 방향 성분을 부분적으로 약화시킵니다.
9. 왜 이걸 state $S_{t-1}$에 곱하는가?
Gated Delta Net에서는 다음 항이 과거 state에 곱해집니다.
(I - \beta_t k_t k_t^\top)S_{t-1}
여기서 $S_{t-1}$는 key-value memory matrix입니다.
이 matrix는 직관적으로 다음과 같은 역할을 합니다.
key 방향으로 query하면, 그 방향에 연결된 value 정보를 반환하는 memory
출력은 다음처럼 계산됩니다.
y_t = q_t^\top S_t
즉, query $q_t$가 memory matrix $S_t$를 읽습니다.
그런데 현재 새로운 key $k_t$가 들어왔습니다.
이때 모델은 기존 state에서 현재 key $k_t$ 방향과 관련된 과거 정보를 먼저 지우고 싶을 수 있습니다.
그 이유는 현재 key 방향에 새로운 value $v_t$를 써야 하기 때문입니다.
따라서 다음 연산을 먼저 합니다.
(I - \beta_t k_t k_t^\top)S_{t-1}
그렇기 때문에 이 연산은 과거 memory 중에서 현재 key 방향과 관련된 성분을 일부 제거하는것입니다.
그다음 현재 key-value 정보를 새로 씁니다.
\beta_t k_t v_t^\top
전체적으로 보면 다음과 같습니다.
S_t = \gamma_t \underbrace{(I - \beta_t k_t k_t^\top)S_{t-1}}_{\text{현재 key 방향의 과거 memory 제거}} + \underbrace{\beta_t k_t v_t^\top}_{\text{현재 key-value 새로 쓰기}}
10. $\beta_t$가 0이면 왜 no input operation인가?
슬라이드에서는 $\beta_t = 0$일 때를 no input operation gate처럼 설명합니다.
실제로 $\beta_t = 0$을 식에 넣어보겠습니다.
S_t = \gamma_t (I - 0 \cdot k_t k_t^\top)S_{t-1} + 0 \cdot k_t v_t^\top
정리하면:
S_t = \gamma_t S_{t-1}
입니다.
즉, 현재 token의 정보 $k_t v_t^\top$는 state에 쓰이지 않습니다.
또한 현재 key 방향의 과거 memory도 지워지지 않습니다.
따라서 $\beta_t = 0$이면 현재 입력은 state update에 거의 관여하지 않습니다.
그래서 no input operation이라고 볼 수 있습니다.
11. $\beta_t$가 1이면 어떤 일이 일어나는가?
반대로 $\beta_t = 1$이면 식은 다음처럼 됩니다.
S_t = \gamma_t (I - k_t k_t^\top)S_{t-1} + k_t v_t^\top
이 경우 현재 key 방향과 관련된 과거 memory를 강하게 제거합니다.
그리고 현재 key-value 정보를 새로 씁니다.
즉, 현재 key 방향에 대해 일종의 overwrite가 일어납니다.
현재 key 방향의 old value 제거
현재 key 방향에 new value 기록
이 점에서 Gated Delta Net은 단순 누적 memory가 아니라, key 방향별로 memory를 갱신하는 구조에 가깝습니다.
Page 10. Qwen 3.5 / Qwen Next
Page 10은 Qwen 3.5 또는 Qwen Next 계열 모델이 Gated Delta Net과 attention을 섞은 hybrid 구조를 사용한다는 점을 보여줍니다.
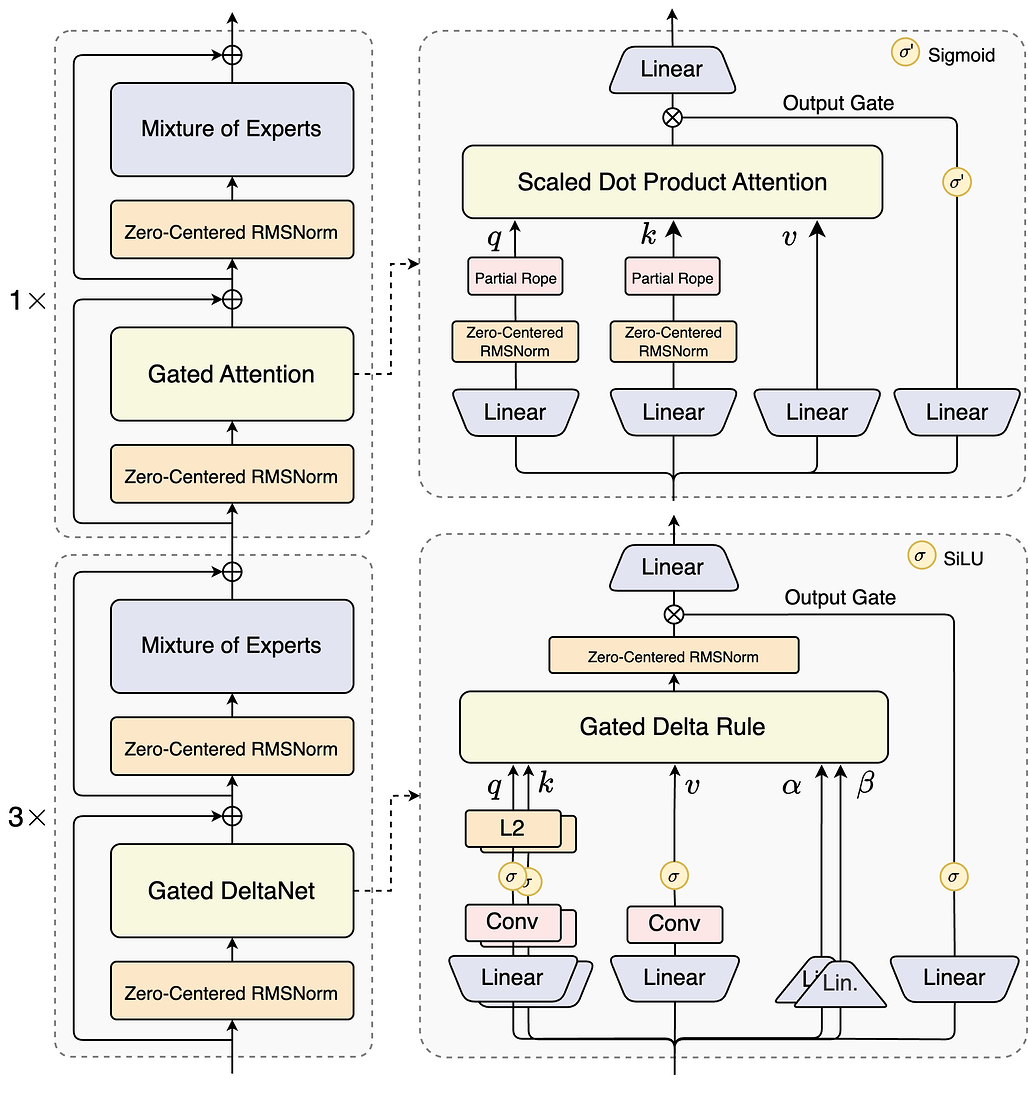 위 그림은 Qwen3-Next 구조입니다.
위 그림은 Qwen3-Next 구조입니다.
슬라이드에서는 다음과 같이 설명합니다.
The newest Qwen are 3-1 GDN / Attention hybrids.
즉, Qwen 계열의 최신 구조는 대략적으로 Gated Delta Net layer 3개 + Attention layer 1개의 비율로 구성된 hybrid architecture라는 의미입니다.
여기서 Gated Delta Net은 Page 9에서 설명한 효율적인 state update layer입니다.
즉, 모든 token pair를 직접 비교하는 full attention 대신, recurrent state를 업데이트하고 읽는 방식으로 정보를 처리합니다.
반면 attention layer는 여전히 full attention을 수행합니다.
따라서 token 간 직접적인 상호작용을 보완하는 역할을 합니다.
이 설계의 목적은 명확합니다.
long-context와 inference 효율성을 위해 대부분은 GDN으로 처리하고, full attention layer를 일부 남겨 성능과 표현력을 보완하는 것입니다.
이 구조는 Page 6의 MiniMax M1, Page 8의 Nemotron 3와 같은 흐름에 있습니다.
-
MiniMax M1: linear attention + full attention hybrid
-
Nemotron 3: Mamba + full attention hybrid
-
Qwen 3.5 / Qwen Next: GDN + full attention hybrid
즉, 최근 모델들의 공통적인 방향은 다음입니다.
full attention을 완전히 버리지는 않습니다. 하지만 모든 layer에서 full attention을 쓰지도 않습니다. 대신 효율적인 state-based layer와 full attention을 섞습니다.
아래 그래프는 이런 구조가 성능 면에서도 어느 정도 합리적이고, inference 특성도 좋다는 점을 보여줍니다.
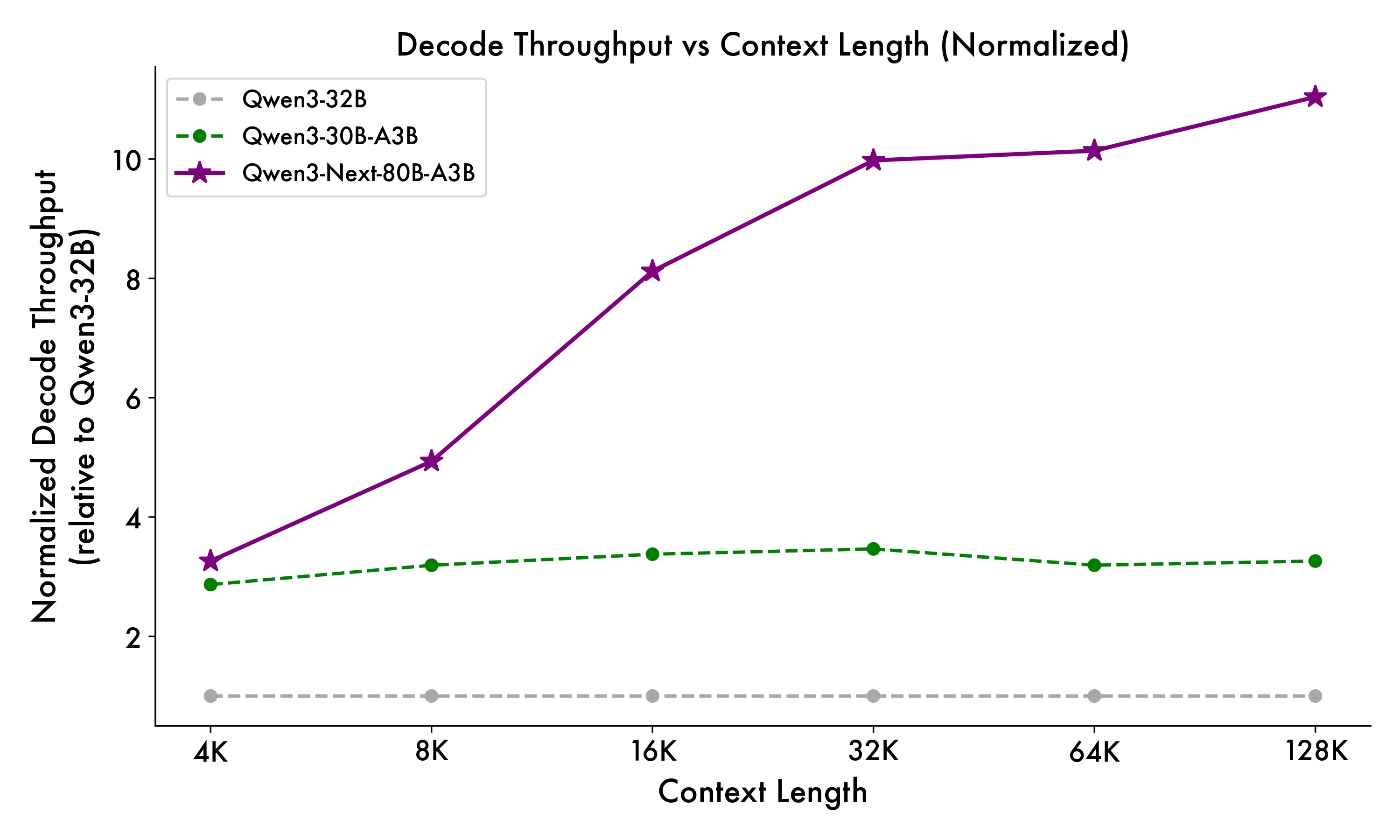
특히 context length가 길어질수록 full attention 기반 모델은 비용이 빠르게 증가합니다.
반면 GDN/attention hybrid는 많은 layer가 효율적인 recurrent 구조를 사용하기 때문에 더 좋은 inference 특성을 가질 수 있습니다.
Page 11.
Page 11은 hybrid architecture의 성능에 대한 슬라이드입니다.
슬라이드의 핵심 문장은 다음입니다.
Not many controlled ablations, but some evidence of low losses at small hybrid ratios.
즉, hybrid architecture에 대한 완전히 엄밀한 통제 실험은 아직 많지 않지만, 적은 수의 full attention layer만 섞어도 loss가 꽤 낮게 유지된다는 증거들이 있다는 의미입니다.
Page 12.
Page 12는 hybrid architecture와는 다른 접근을 소개합니다.
지금까지 본 방식은 대부분 다음과 같은 흐름이었습니다.
full attention이 비싸므로, linear attention, Mamba, GDN 같은 대체 layer를 사용하고, 일부 full attention layer를 섞어서 성능을 보완합니다.
그런데 Page 12에서는 다른 대안을 제시합니다.
attention을 완전히 다른 layer로 바꾸는 대신, attention 자체를 sparse하게 만들자.
즉, 모든 token을 보지 말고, 필요한 token 일부만 보자는 아이디어입니다.
표준 causal attention에서는 현재 token $t$가 이전의 모든 token을 볼 수 있습니다.
y_t = \sum_{i=1}^{t} \alpha_{ti} v_i
여기서 현재 token은 $1$번부터 $t$번까지의 모든 token에 대해 attention score를 계산합니다.
하지만 sparse attention에서는 현재 token이 모든 과거 token을 보는 것이 아니라, 선택된 일부 token만 봅니다.
선택된 token 집합을 $\mathcal{I}_t$라고 하면 다음과 같습니다.
\mathcal{I}_t \subset \{1, 2, \ldots, t\}
그리고 sparse attention은 다음처럼 계산됩니다.
y_t = \sum_{i \in \mathcal{I}_t} \alpha_{ti} v_i
즉, attention 대상이 전체 과거 token이 아니라 선택된 token subset으로 줄어듭니다.
만약 전체 과거 token 수가 $t$개인데, 그중 $k$개만 선택한다면 attention 비용은 크게 줄어듭니다.
표준 attention의 비용은 per token 기준으로 대략 다음과 같습니다.
O(t)
전체 sequence에 대해서는 다음과 같습니다.
O(n^2)
반면 sparse attention에서 각 token이 $k$개 token만 본다면 전체 비용은 대략 다음과 같습니다.
O(nk)
여기서 $k$가 $n$보다 훨씬 작다면 큰 효율 이득을 얻을 수 있습니다.
Page 12에서 언급하는 DSA는 이러한 sparse attention 계열의 한 예시입니다.
DSA는 DeepSeek Sparse Attention을 의미합니다.
핵심 아이디어는 attention을 수행하기 전에, 어떤 token을 볼지 선택하는 가벼운 indexer를 두는 것입니다.
구조를 단순화하면 다음과 같습니다.
1. 현재 query token이 들어옵니다.
2. lightweight indexer가 관련 있어 보이는 과거 token들을 고릅니다.
3. full attention은 선택된 token들에 대해서만 수행됩니다.
여기서 indexer는 매우 가벼워야 합니다.
왜냐하면 token을 고르는 과정 자체가 너무 비싸면 sparse attention의 장점이 사라지기 때문입니다.
즉, indexer의 역할은 다음과 같습니다.
“현재 token이 어떤 과거 token을 참고해야 할지 빠르게 후보를 추린다.”
이 방식은 local attention과도 다릅니다.
local attention은 보통 현재 token 주변의 일정 window만 봅니다.
예를 들어 다음과 같습니다.
현재 token 기준 앞뒤 512개 token만 보기
이런 식입니다.
하지만 sparse attention은 꼭 주변 token만 보는 것이 아닙니다.
멀리 떨어진 token이라도 중요하다고 판단되면 선택할 수 있습니다.
따라서 sparse attention은 다음과 같은 장점을 가집니다.
local attention:
가깝다는 이유로 token을 선택합니다.
sparse attention:
관련성이 높다는 이유로 token을 선택합니다.
Page 12에서 또 중요한 표현은 post hoc adapted after dense short context pretraining입니다.
이 말은 모델을 처음부터 sparse attention으로 pretraining하지 않아도 된다는 뜻입니다.
즉, 먼저 일반적인 dense attention 기반으로 짧은 context에서 pretraining을 합니다.
그 후 sparse attention 구조를 추가하거나 변형해서 long-context에 맞게 적응시킬 수 있다는 의미입니다.
이것은 실용적으로 중요합니다.
왜냐하면 대형 모델을 처음부터 sparse attention으로 다시 pretraining하는 것은 비용이 너무 크기 때문입니다.
반면 이미 학습된 dense model을 sparse attention 방식으로 사후 적응할 수 있다면, 훨씬 현실적인 접근이 됩니다.
정리하면 Page 12의 핵심은 다음입니다.
hybrid architecture는 attention을 일부 layer에만 남기는 방식입니다.
반면 sparse adaptation은 attention을 유지하되, 모든 token을 보지 않고 중요한 token 일부만 보게 만드는 방식입니다. DSA는 lightweight indexer를 사용해 attention 대상을 선택하고, 이를 통해 long-context 효율성을 높이려는 접근입니다.
Page 13. DSA - Deepseek Sparse Attention (v3.2, GLM5)
 Page 13의 그래프들은 DSA가 여러 benchmark에서 dense attention 기반 모델과 비교해 성능을 어느 정도 유지하면서도, prefill과 decoding 측면에서 효율성을 개선할 수 있음을 보여주는 흐름입니다.
Page 13의 그래프들은 DSA가 여러 benchmark에서 dense attention 기반 모델과 비교해 성능을 어느 정도 유지하면서도, prefill과 decoding 측면에서 효율성을 개선할 수 있음을 보여주는 흐름입니다.
여기서 prefill과 decoding을 구분해서 이해해야 합니다.
1. Prefill
Prefill은 prompt 전체를 모델에 넣고 KV cache를 만드는 단계입니다.
예를 들어 사용자가 긴 문서를 입력했다면, 모델은 답변을 생성하기 전에 그 문서 전체를 처리해야 합니다.
이 단계가 prefill입니다.
긴 context에서는 prefill 비용이 매우 커질 수 있습니다.
왜냐하면 prompt token들 사이의 attention 계산이 많이 필요하기 때문입니다.
DSA는 모든 token pair에 대해 attention을 하지 않기 때문에 prefill 비용을 줄일 수 있습니다.
2. Decoding
Decoding은 모델이 답변 token을 하나씩 생성하는 단계입니다.
autoregressive generation에서는 매번 새로운 token을 생성할 때 과거 context를 참고해야 합니다.
표준 attention에서는 현재 token이 과거 token들의 key와 attention을 수행합니다.
KV cache가 있어도 현재 query와 과거 key들 간의 dot product는 필요합니다.
따라서 context가 길수록 decoding 단계에서도 부담이 커집니다.
DSA는 이때도 모든 과거 token을 보는 것이 아니라 선택된 일부 token만 보게 하므로 decoding 비용을 줄일 수 있습니다.
Page 13의 핵심은 단순히 “DSA가 빠르다”가 아닙니다.
더 중요한 메시지는 다음입니다.
sparse attention은 long-context에서 효율성을 높이면서도,
full attention의 장점인 token-level retrieval 능력을 어느 정도 유지하려는 접근입니다.
다만 DSA에도 한계는 있습니다.
가장 큰 한계는 indexer가 중요한 token을 잘 골라야 한다는 점입니다.
만약 indexer가 중요한 token을 놓치면, 이후 attention 단계에서는 그 token을 볼 수 없습니다.
즉, sparse attention의 성능은 token selection 품질에 크게 의존합니다.
따라서 DSA의 성공 조건은 다음과 같습니다.
1. indexer가 충분히 가벼워야 합니다.
2. indexer가 중요한 token을 잘 골라야 합니다.
3. 선택된 token 수가 너무 많지 않아야 합니다.
4. sparse attention으로 바꿔도 모델 성능이 크게 떨어지지 않아야 합니다.
정리하면 Page 13의 핵심은 다음입니다.
DSA는 full attention을 완전히 대체하는 linear state 구조가 아니라, attention을 유지하되 중요한 token 일부만 선택해서 보는 sparse attention 방식입니다. 이를 통해 long-context에서 prefill과 decoding 비용을 줄이면서도 성능 저하를 최소화하려고 합니다.
Page 14. Mixture of Experts
Page 14는 새로운 파트의 시작입니다. 앞부분에서는 linear attention, Mamba 계열, hybrid attention처럼 attention 비용을 줄이는 구조를 다뤘습니다. 이제부터는 모델의 또 다른 핵심 구성요소인 feed-forward network, 즉 FFN을 어떻게 확장할 것인가를 다룹니다.
Transformer layer는 보통 크게 두 블록으로 구성됩니다.
- Attention block
- Feed-forward block 또는 MLP block
앞부분의 주제가 attention block을 더 효율적으로 만드는 방법이었다면, MoE는 주로 두 번째 블록인 FFN/MLP를 sparse하게 확장하는 방법입니다.

슬라이드에 GPT-4 (?)라고 적혀 있는 것은 GPT-4가 MoE 구조일 가능성이 널리 추정되어 왔다는 맥락을 암시합니다. 다만 공식적으로 구조가 완전히 공개된 것은 아니므로, 여기서 중요한 것은 “GPT-4가 정확히 MoE냐 아니냐”가 아니라, 최근 고성능 LLM에서 MoE가 매우 중요한 구조적 트렌드가 되었다는 점입니다.
핵심 메시지는 다음과 같습니다.
Attention을 효율화하는 방법만큼이나, FFN을 sparse하게 확장하는 MoE도 현대 LLM 구조에서 매우 중요한 축입니다.
Page 15. What’s a MoE?
Page 15는 MoE의 기본 정의를 설명합니다.
MoE는 Mixture of Experts의 약자입니다. 말 그대로 여러 개의 expert, 즉 여러 개의 전문가 네트워크를 두고, 입력 token마다 그중 일부 expert만 선택해서 사용하는 구조입니다.
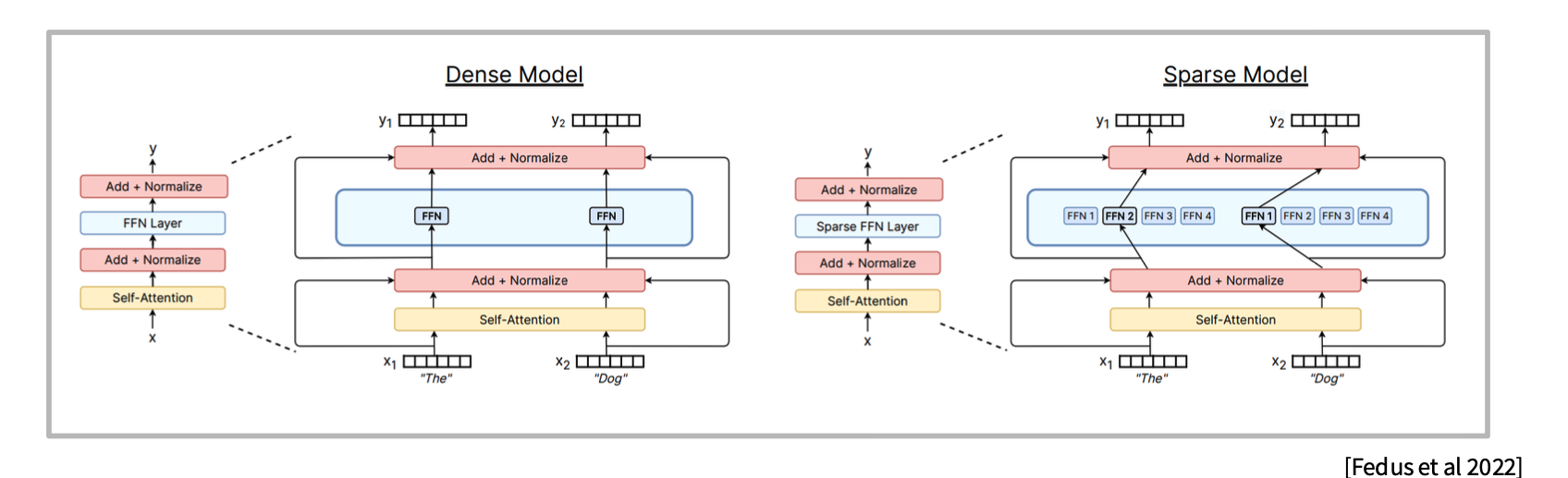
일반적인 dense Transformer에서는 각 token이 같은 FFN을 통과합니다.
Dense Transformer layer
Token -> Attention -> FFN -> Output
여기서 FFN은 모든 token에 대해 항상 동일하게 사용됩니다. 즉, 모든 token이 같은 FFN 파라미터를 거칩니다.
반면 MoE에서는 FFN 하나를 여러 개의 expert FFN으로 바꿉니다.
MoE Transformer layer
Token -> Attention -> Router -> Expert 1 / Expert 2 / Expert 3 / ... -> Output
즉, 기존에는 하나의 큰 FFN이 있었다면, MoE에서는 여러 개의 FFN을 두고 token마다 일부만 선택합니다.
슬라이드의 문장은 다음과 같습니다.
Replace big feedforward with (many) big feedforward networks and a selector layer
이 말은 기존 Transformer의 FFN을 여러 개의 FFN expert로 바꾸고, 이 expert들 중 어떤 것을 쓸지 고르는 selector 또는 router를 추가한다는 뜻입니다.
Dense model과 sparse model의 차이
Dense model에서는 모든 token이 모든 관련 파라미터를 사용합니다.
Token A -> FFN 전체 사용
Token B -> FFN 전체 사용
Token C -> FFN 전체 사용
반면 sparse MoE에서는 token마다 일부 expert만 사용합니다.
Token A -> Expert 2, Expert 5 사용
Token B -> Expert 1, Expert 3 사용
Token C -> Expert 5, Expert 7 사용
여기서 중요한 점은 전체 expert 수는 많지만, 한 token이 실제로 사용하는 expert 수는 적다는 것입니다.
예를 들어 expert가 8개 있고, 각 token이 top-2 expert만 사용한다고 해보겠습니다.
전체 expert 수: 8개
token 하나가 사용하는 expert 수: 2개
그러면 모델은 전체적으로는 8개의 expert를 가지고 있으므로 파라미터 수가 커집니다. 하지만 각 token이 실제 forward pass에서 사용하는 것은 2개 expert뿐이므로 계산량은 제한됩니다.
이것이 슬라이드의 두 번째 문장입니다.
You can increase the # experts without affecting FLOPs
정확히 말하면, expert 수를 늘리면 전체 파라미터 수는 늘어나지만, token당 선택되는 expert 수 kk를 고정하면 token당 계산량은 크게 늘어나지 않습니다.
예를 들어 top-2 routing을 사용하면:
8 experts 중 2개 사용
16 experts 중 2개 사용
64 experts 중 2개 사용
128 experts 중 2개 사용
이렇게 expert 전체 개수가 늘어나도, token당 활성화되는 expert 수가 2개라면 활성 계산량은 대략 유지됩니다. 대신 모델이 보유한 전체 capacity는 커집니다.
핵심 메시지는 다음과 같습니다.
MoE는 모든 token이 모든 파라미터를 쓰는 dense 구조가 아니라, token마다 일부 expert만 사용하는 sparse 구조입니다. 그래서 전체 파라미터 수는 크게 늘리면서도 token당 FLOPs는 제한할 수 있습니다.
Page 16. Why are MoEs getting popular? - Same FLOP, more parameter does better
Page 16은 MoE가 인기를 얻는 첫 번째 이유를 설명합니다.
슬라이드의 핵심 문장은 다음입니다.
Same FLOP, more param does better
즉, 같은 계산량을 쓰더라도 더 많은 파라미터를 가진 모델이 더 좋은 성능을 낼 수 있다는 것입니다.
일반적인 dense model에서는 파라미터 수를 늘리면 계산량도 같이 늘어납니다.
Dense model
파라미터 증가 -> 대부분의 forward 계산량도 증가
예를 들어 FFN의 hidden dimension을 키우면 모델 파라미터도 늘고, 모든 token이 그 커진 FFN을 통과하므로 계산량도 같이 커집니다.
하지만 MoE에서는 다릅니다.
MoE model
전체 expert 수 증가 -> 전체 파라미터 수 증가
하지만 token당 선택 expert 수 고정 -> token당 계산량은 상대적으로 유지
이 구조 덕분에 MoE는 계산량 대비 파라미터 수를 크게 늘릴 수 있는 방법이 됩니다.
왜 파라미터가 많으면 도움이 되는가?
LLM에서 파라미터 수가 많다는 것은 모델이 더 많은 패턴, 지식, 표현을 저장할 capacity가 커진다는 뜻입니다. 물론 모든 파라미터를 매번 다 쓰면 계산량이 너무 커집니다. MoE는 이 문제를 다음처럼 해결합니다.
전체 모델 capacity는 크게 만든다.
하지만 각 token은 필요한 일부 expert만 사용한다.
그래서 같은 FLOPs 예산 안에서 dense model보다 더 많은 total parameter를 가질 수 있습니다.
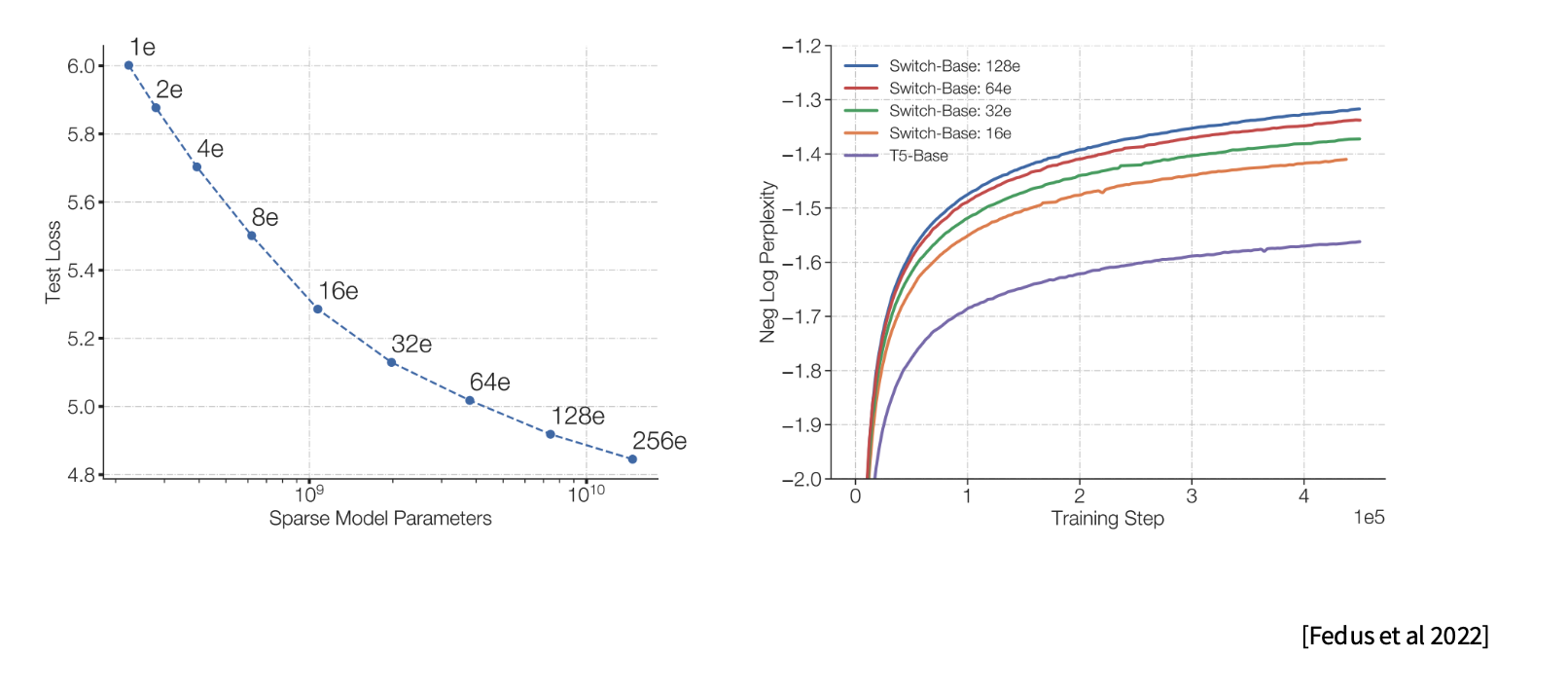
슬라이드의 그래프는 expert 수나 sparse model parameter가 증가할수록 loss/perplexity가 개선되는 경향을 보여주는 맥락입니다. 중요한 해석은 다음입니다.
동일한 compute budget에서도 sparse MoE는 더 큰 parameter capacity를 활용할 수 있기 때문에 dense model보다 좋은 성능을 낼 수 있습니다.
다만 여기서 말하는 파라미터는 두 종류로 나누어 이해해야 합니다.
| 구분 | 의미 |
|---|---|
| Total parameters | 모델이 전체적으로 가지고 있는 모든 파라미터 |
| Active parameters | 특정 token을 처리할 때 실제로 사용되는 파라미터 |
MoE의 장점은 total parameters는 크게 만들고, active parameters는 제한할 수 있다는 점입니다.
Page 17. Why are MoEs getting popular? - Faster to train MoEs
Page 17은 MoE가 인기를 얻는 두 번째 이유입니다.
핵심은 MoE가 같은 성능 수준에 더 빠르게 도달할 수 있다는 점입니다.
dense model에서 성능을 높이려면 보통 모델 전체 크기를 키워야 합니다. 그런데 dense model은 모든 token이 모든 파라미터를 사용하므로, 모델을 키우면 training FLOPs도 크게 늘어납니다.
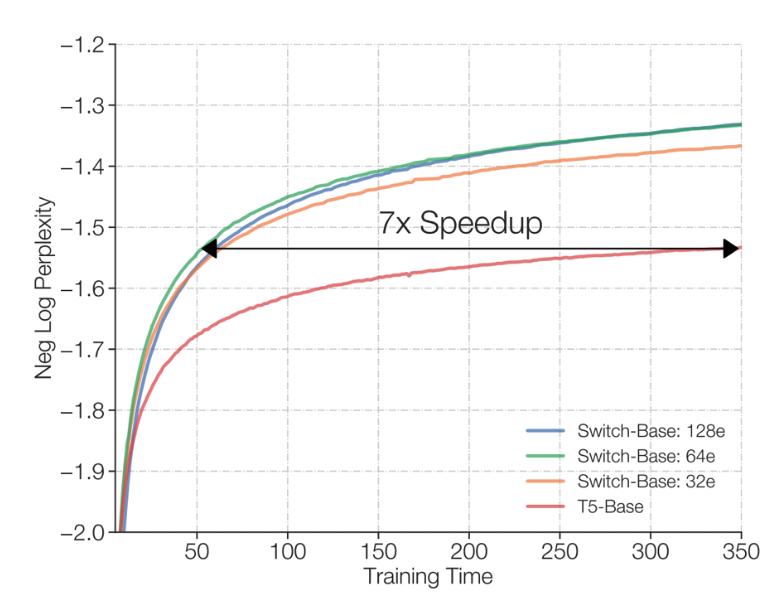
반면 MoE는 많은 expert를 갖고 있지만, token마다 일부 expert만 활성화합니다. 그래서 다음과 같은 장점이 생깁니다.
전체 capacity는 큼
하지만 token당 계산량은 제한됨
따라서 같은 compute로 더 큰 모델 효과를 얻을 수 있음
슬라이드에서는 OLMoE 결과를 예시로 보여줍니다. 자세한 숫자를 외우는 것보다는, 그래프가 전달하는 메시지를 이해하는 것이 중요합니다.
MoE는 dense model에 비해 training compute 대비 더 좋은 loss/performance trade-off를 보일 수 있습니다.
즉, MoE는 단순히 inference용 구조가 아니라, training-time efficiency 측면에서도 매력적입니다.
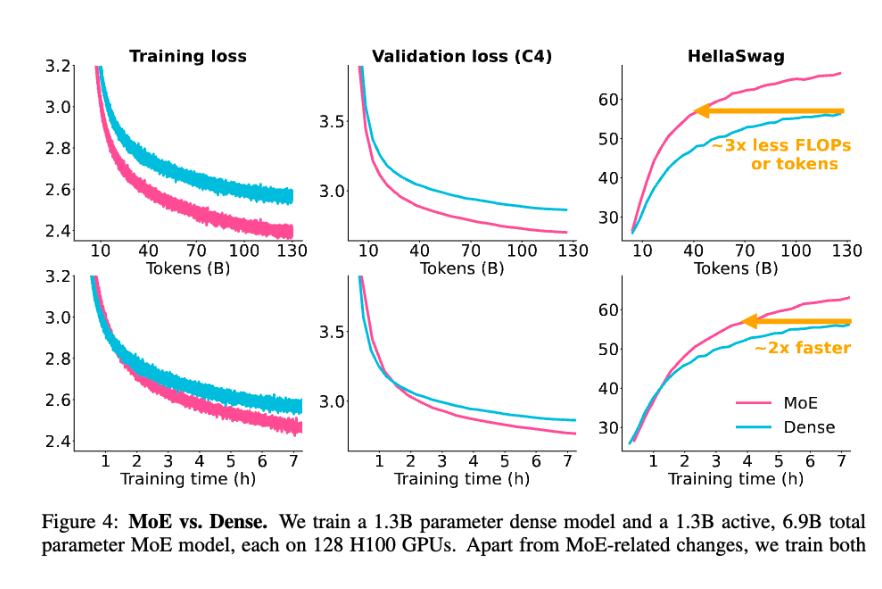
하지만 “항상 MoE가 더 빠르다”라고 단순화하면 안 됩니다. MoE는 계산량 측면에서는 유리할 수 있지만, 실제 학습 시스템에서는 routing, expert parallelism, all-to-all communication, load balancing 같은 복잡한 문제가 생깁니다. 그래서 이론적으로는 compute-efficient하지만, 시스템 구현은 훨씬 어렵다고 이해하는 것이 좋습니다.
Page 18. Why are MoEs getting popular? - Highly competitive vs dense equivalents
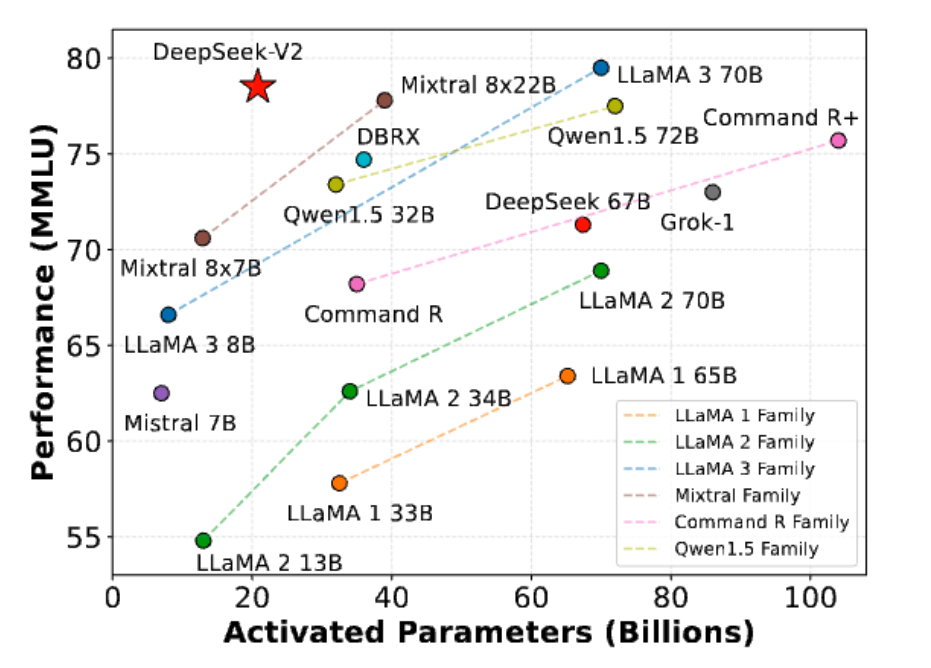 Page 18은 MoE가 dense model과 비교해 실제 성능 면에서도 충분히 경쟁력이 있다는 것을 보여줍니다.
Page 18은 MoE가 dense model과 비교해 실제 성능 면에서도 충분히 경쟁력이 있다는 것을 보여줍니다.
MoE가 처음에는 약간 특수한 구조처럼 보일 수 있습니다. 왜냐하면 token마다 일부 expert만 사용하기 때문에, 직관적으로는 “모든 파라미터를 다 쓰는 dense model보다 약하지 않을까?”라는 의문이 생길 수 있습니다.
하지만 최근 결과들은 MoE가 dense equivalent와 비교해 매우 경쟁력 있는 성능을 낼 수 있음을 보여줍니다.
여기서 dense equivalent란 대략 비슷한 compute budget, 비슷한 active parameter budget, 또는 비슷한 training budget에서 비교되는 dense model을 의미합니다.
Page 19. Why are MoEs getting popular? - Parallelizable to many devices
Page 19는 MoE의 시스템 측면 장점을 설명합니다.
MoE는 expert가 여러 개로 나뉘어 있기 때문에, expert들을 여러 GPU나 여러 node에 나누어 배치할 수 있습니다. 이를 보통 expert parallelism이라고 부릅니다.
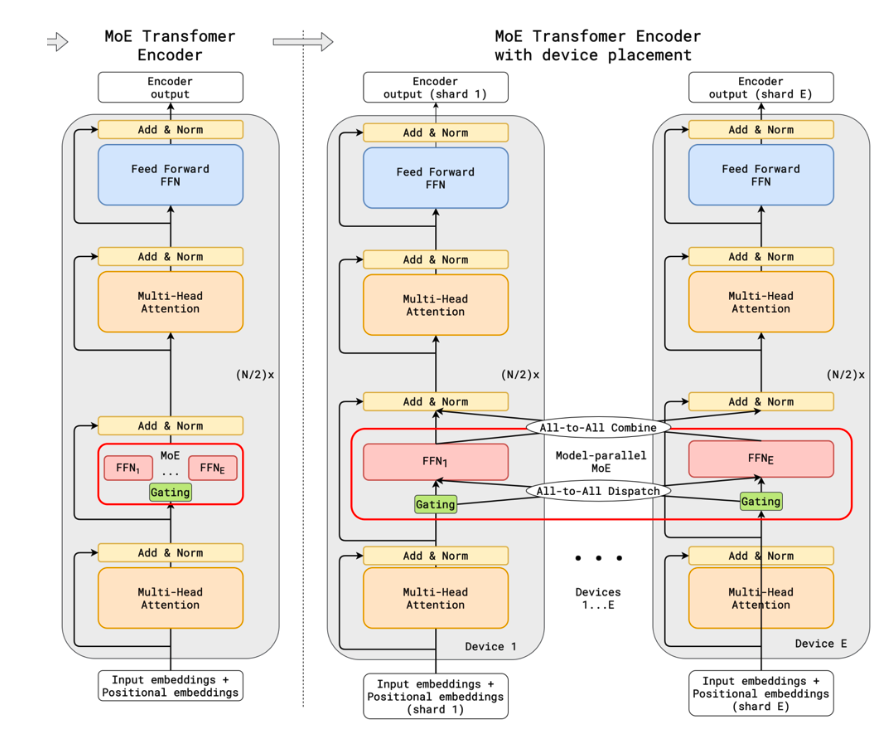
예를 들어 expert가 8개 있고 GPU가 4개 있다고 해보겠습니다.
GPU 1: Expert 1, Expert 2
GPU 2: Expert 3, Expert 4
GPU 3: Expert 5, Expert 6
GPU 4: Expert 7, Expert 8
그러면 token은 router가 선택한 expert가 있는 GPU로 이동하고, 해당 expert에서 계산된 뒤 다시 모입니다.
이때 중요한 통신 패턴이 바로 all-to-all communication입니다.
All-to-All은 각 GPU가 나머지 모든 GPU에게 데이터를 보냅니다. GPU 0 → GPU 0, GPU 1, GPU 2, GPU 3 GPU 1 → GPU 0, GPU 1, GPU 2, GPU 3 GPU 2 → GPU 0, GPU 1, GPU 2, GPU 3 GPU 3 → GPU 0, GPU 1, GPU 2, GPU 3
즉, 모든 GPU가 sender이면서 동시에 receiver입니다.
다시 돌아가서,
1. 각 GPU가 가진 token들을 expert별로 재분배합니다.
2. 각 expert가 자기에게 온 token들을 처리합니다.
3. 처리 결과를 다시 원래 token 순서에 맞게 모읍니다.
이 구조 덕분에 MoE는 여러 device를 활용해 큰 모델을 병렬화하기 좋습니다.
다만 장점만 있는 것은 아닙니다. expert를 여러 device에 나누면 GPU 간 token 이동이 필요하기 때문에 communication overhead가 커질 수 있습니다. 특히 multi-node 환경에서는 network bandwidth와 latency가 성능 병목이 될 수 있습니다.
핵심 메시지는 다음입니다.
MoE는 구조적으로 multi-device parallelism에 잘 맞지만, 실제 효율을 얻으려면 routing과 communication을 잘 최적화해야 합니다.
Page 20. Some MoE results - from the west
 Page 20은 서구권에서 나온 주요 MoE 모델 결과들을 보여주는 슬라이드입니다.
Page 20은 서구권에서 나온 주요 MoE 모델 결과들을 보여주는 슬라이드입니다.
슬라이드의 핵심 문장은 다음입니다.
MoEs are most of the highest-performance open models, and are quite quick
즉, 공개 모델 중 상위권 성능을 보이는 모델들 상당수가 MoE 구조를 채택하고 있으며, 속도 면에서도 매력적이라는 뜻입니다.
Page 21. Earlier MoE results from Chinese groups - Qwen
Page 21은 중국 LLM 그룹, 특히 Qwen 계열의 MoE 결과를 언급합니다.
슬라이드의 메시지는 다음입니다.
Chinese LLM companies are also doing quite a bit of MoE work on the smaller end
 즉, MoE가 초대형 frontier model에서만 쓰이는 것이 아니라, 비교적 작은 크기의 모델에서도 적극적으로 연구되고 있다는 뜻입니다.
즉, MoE가 초대형 frontier model에서만 쓰이는 것이 아니라, 비교적 작은 크기의 모델에서도 적극적으로 연구되고 있다는 뜻입니다.
Qwen 계열 모델들은 dense model뿐 아니라 MoE 변형도 공개해왔고, 특히 작은 모델 영역에서도 MoE를 통해 parameter capacity와 compute efficiency의 균형을 맞추려는 시도를 보여줍니다.
Page 22. Earlier MoE results from Chinese groups - DeepSeek
Page 22는 DeepSeek 계열의 MoE 결과를 다룹니다.
DeepSeek은 MoE 구조를 적극적으로 활용한 대표적인 그룹 중 하나입니다. 특히 DeepSeek-MoE와 DeepSeek-V2/V3 계열에서는 expert 구성, shared expert, fine-grained routing, load balancing 등 MoE의 중요한 설계 요소들이 많이 논의되었습니다.
슬라이드의 핵심 문장은 다음입니다.
There’s also some good recent ablation work on MoEs showing they’re generally good
여기서 ablation work란 모델의 구성요소를 하나씩 바꿔보면서 어떤 설계가 성능에 얼마나 영향을 주는지 분석하는 실험을 말합니다.
MoE에서 ablation이 중요한 이유는 다음과 같습니다.
expert 수를 몇 개로 할 것인가?
top-k에서 k를 몇으로 할 것인가?
shared expert를 둘 것인가?
fine-grained expert를 쓸 것인가?
router loss를 어떻게 줄 것인가?
load balancing은 어떻게 할 것인가?
이런 선택들이 모두 성능과 안정성에 영향을 주기 때문입니다.
DeepSeek 계열 연구는 MoE가 단지 “expert 여러 개를 두면 된다” 수준이 아니라, 세부 설계가 매우 중요하다는 점을 보여줍니다.
Page 23. Recent MoE results -DeepSeek v3
Page 23은 최근 MoE 모델의 대표 사례로 DeepSeek-V3를 언급합니다.
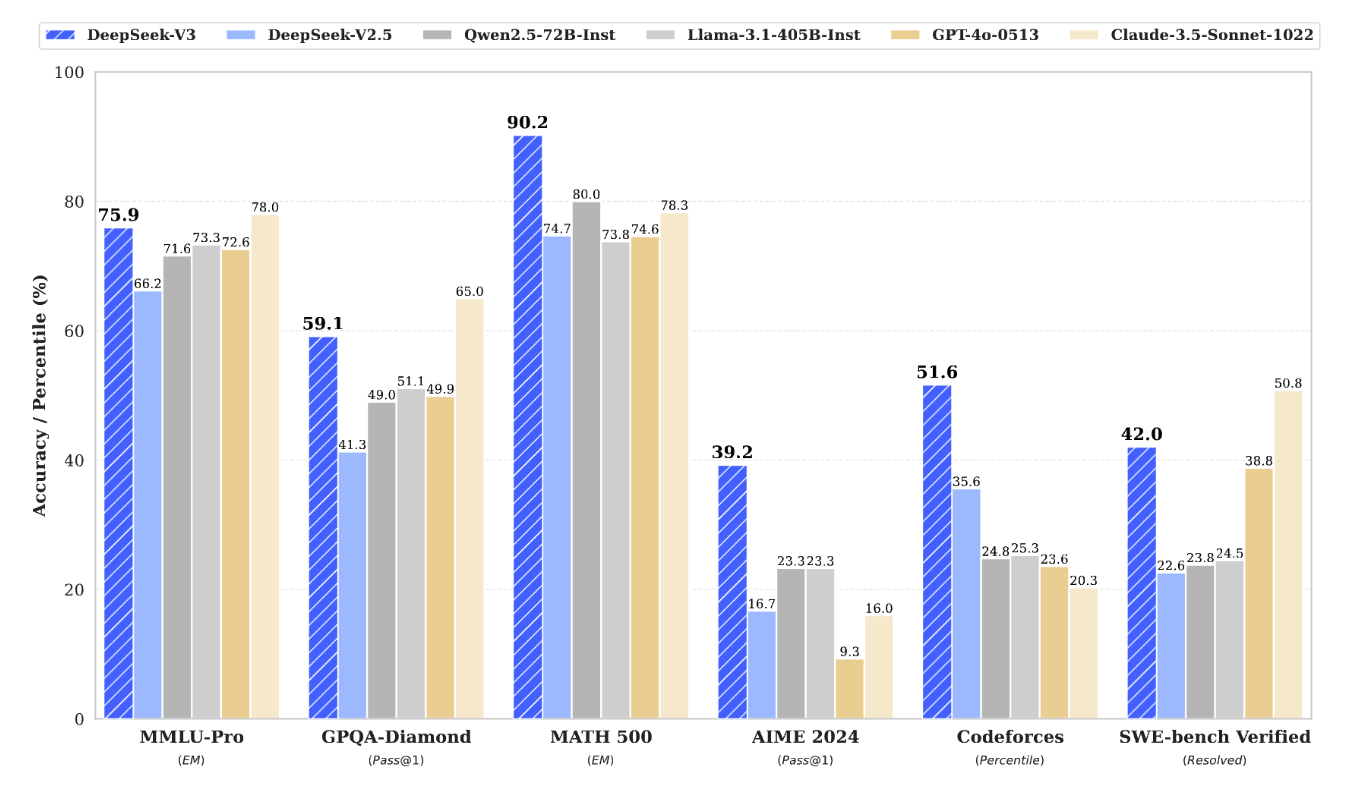
DeepSeek-V3는 MoE가 최신 고성능 LLM에서 얼마나 중요한 위치를 차지하는지를 보여주는 사례입니다. 이 페이지에서 봐야 할 것은 세부 benchmark 숫자보다, 다음 구조적 흐름입니다.
초기 MoE: compute-efficient scaling 아이디어
최근 MoE: 실제 고성능 LLM의 핵심 architecture
DeepSeek-V3 같은 모델은 큰 total parameter count를 가지면서도, token당 활성화되는 parameter는 제한하는 방식으로 효율을 확보합니다.
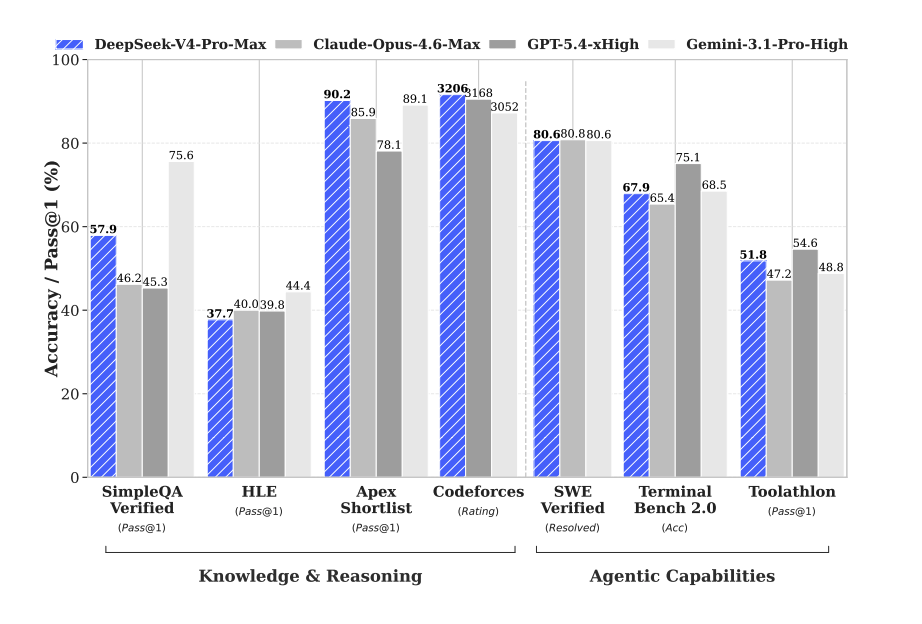
최근에는 DeepSeek V4도 나왔습니다.
Page 24. Why haven’t MoEs been more popular?
Page 24는 앞의 장점들과 반대로, 왜 MoE가 그동안 더 널리 쓰이지 않았는지를 설명합니다.
슬라이드는 크게 두 가지 이유를 듭니다.
-
Infrastructure is complex / advantages on multi node
-
Training objectives are somewhat heuristic and sometimes unstable
즉, MoE는 이론적으로 좋아 보이지만 실제로 학습하고 서빙하는 것이 어렵습니다.
1. Infrastructure가 복잡합니다.
MoE는 expert가 여러 개이기 때문에 token을 expert별로 보내야 합니다. 이 과정은 단순한 dense model forward보다 훨씬 복잡합니다.
일반 dense model에서는 모든 GPU가 같은 layer 계산을 비교적 정해진 방식으로 수행합니다. 하지만 MoE에서는 token마다 선택된 expert가 다를 수 있습니다.
예를 들어 batch 안에 token이 10,000개 있고 expert가 8개 있다고 해보겠습니다.
Expert 1로 가는 token: 1,200개
Expert 2로 가는 token: 900개
Expert 3로 가는 token: 2,300개
Expert 4로 가는 token: 400개
...
이렇게 token 분포가 불균형할 수 있습니다. 그러면 어떤 expert가 있는 GPU는 바쁘고, 어떤 expert가 있는 GPU는 놀게 됩니다.
또한 expert가 여러 GPU나 node에 흩어져 있으면 token을 보내고 다시 모으는 communication이 필요합니다.
Dispatch: token을 expert가 있는 device로 보냄
Expert computation: 각 expert가 자기 token 처리
Combine: 결과를 다시 원래 순서대로 모음
이 과정은 all-to-all communication을 요구하는 경우가 많습니다. 그래서 MoE의 장점은 multi-node, large-scale training에서 크게 나타나지만, 그만큼 infrastructure 구현 난이도도 높습니다.
2. Training objective가 heuristic하고 불안정할 수 있습니다.
MoE의 또 다른 문제는 router 학습입니다.
router는 token마다 어떤 expert를 사용할지 선택합니다. 보통 top-k routing을 쓰는데, top-k 선택은 discrete decision입니다.
router score 계산 -> 상위 k개 expert 선택 -> 선택된 expert만 사용
문제는 이 선택 과정이 완전히 매끄러운 differentiable operation이 아니라는 점입니다. 그래서 router와 expert를 안정적으로 학습시키기 위해 여러 보조 loss를 사용합니다.
대표적인 것이 load balancing loss입니다.
load balancing loss의 목적은 특정 expert만 너무 많이 선택되는 것을 막는 것입니다.
MoE에서 자주 발생할 수 있는 문제는 expert collapse입니다.
초기 학습에서 특정 expert가 조금 더 잘함
router가 그 expert를 더 많이 선택함
그 expert가 더 많은 gradient를 받음
더 좋아짐
다른 expert는 덜 선택되어 학습이 부족해짐
결국 일부 expert만 계속 사용됨
이런 현상을 rich-get-richer dynamics라고 볼 수 있습니다.
그래서 실제 MoE 학습에서는 다음과 같은 heuristic이 자주 들어갑니다.
-
load balancing loss
-
router z-loss
-
expert capacity 제한
-
token dropping 또는 padding
-
auxiliary loss weight 조정
-
routing noise 또는 jitter
Page 25. What MoEs generally look like
Page 25는 MoE가 Transformer 안에서 보통 어디에 들어가는지를 보여줍니다.
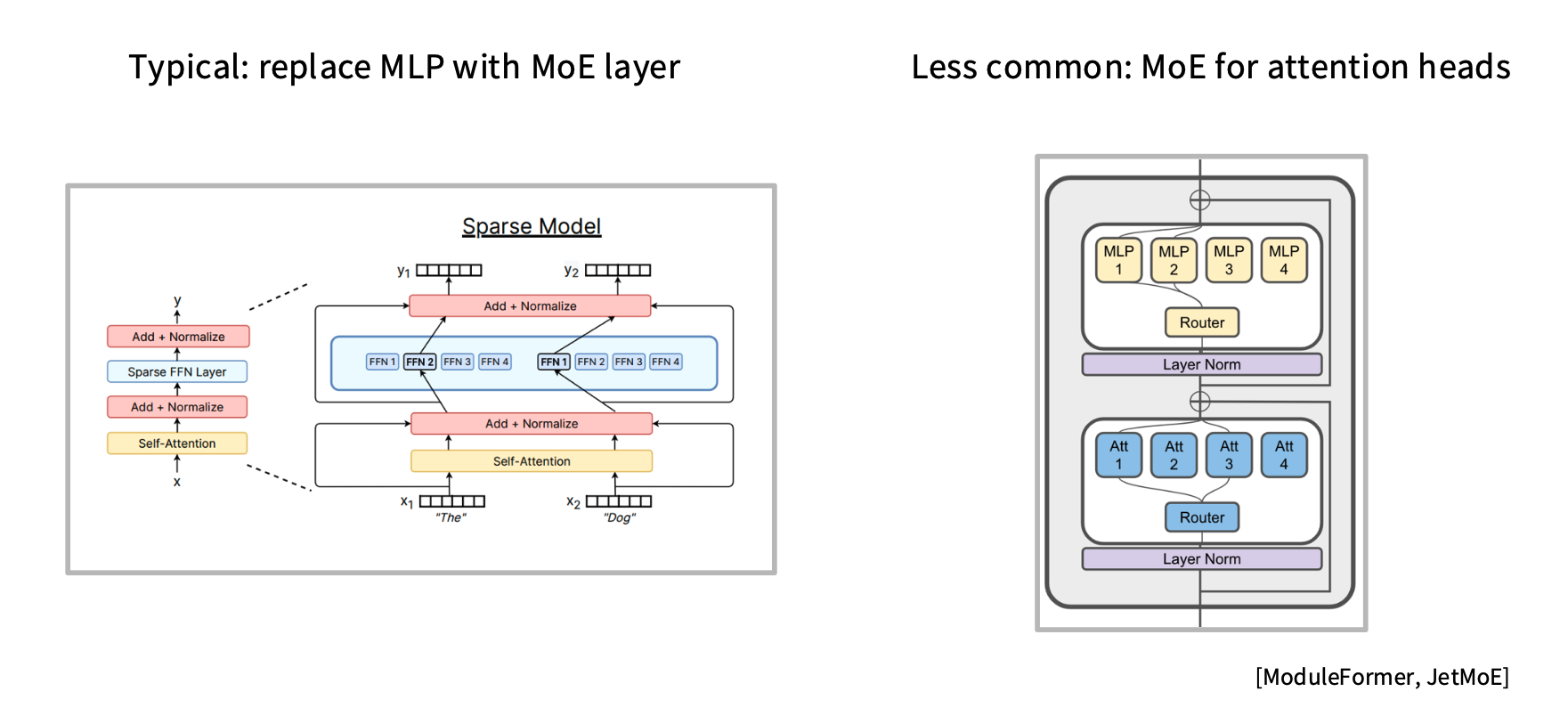
슬라이드의 핵심은 다음입니다.
Typical: replace MLP with MoE layer
Less common: MoE for attention heads
즉, 대부분의 MoE 모델은 attention block을 expert로 바꾸기보다는, MLP/FFN block을 MoE로 바꿉니다.
Transformer에서 FFN/MLP는 파라미터가 많이 들어가는 부분입니다. 일반적으로 MLP는 attention보다 파라미터 수가 큰 경우가 많습니다. 따라서 MLP를 expert 여러 개로 쪼개면 total parameter capacity를 크게 늘리기 좋습니다.
또한 MLP는 token-wise로 독립적으로 적용됩니다. 즉, attention처럼 token 간 상호작용을 직접 계산하는 구조가 아니라, 각 token representation에 대해 같은 feed-forward transformation을 적용하는 구조입니다.
이 특성 때문에 token별로 expert를 선택하는 MoE 구조와 잘 맞습니다.
Page 26. Moe - What varies?
Page 26은 MoE 구조에서 어떤 요소들이 달라질 수 있는지를 정리합니다.
슬라이드에는 세 가지가 나옵니다.
1. Routing function
2. Expert sizes
3. Training objectives
즉, MoE라고 해서 모두 같은 구조는 아닙니다. “여러 expert 중 일부만 선택해서 쓴다”는 큰 아이디어는 같지만, 세부 설계는 모델마다 달라집니다.
1. Routing function
가장 중요한 차이는 routing function입니다.
MoE에서는 각 token이 모든 expert를 통과하지 않습니다. 대신 router가 각 token에 대해 expert 점수를 계산하고, 그중 일부 expert만 선택합니다.
예를 들어 expert가 8개 있고, top-2 routing을 사용한다면 각 token은 8개 expert 중 점수가 가장 높은 2개 expert만 사용합니다.
Token hidden state
↓
Router가 expert별 score 계산
↓
상위 k개 expert 선택
↓
선택된 expert만 실행
여기서 “어떤 기준으로 expert를 고를 것인가?”가 바로 routing function의 문제입니다.
2. Expert sizes
두 번째는 expert의 크기입니다.
초기 MoE에서는 expert 하나가 일반적인 dense FFN과 비슷한 크기를 갖는 경우가 많았습니다. 하지만 최근에는 expert 하나를 더 작게 만들고, expert 개수를 훨씬 많이 두는 방식도 사용됩니다.
이것을 뒤에서 fine-grained expert라고 설명합니다.
예를 들어 두 구조를 비교해보면 다음과 같습니다.
구조 A: expert 8개, 각 expert가 큼
구조 B: expert 64개, 각 expert가 작음
구조 B에서는 expert 하나의 크기는 작지만 선택지가 많기 때문에, token마다 더 세밀한 specialization이 가능해질 수 있습니다.
3. Training objectives
세 번째는 학습 목적입니다.
MoE는 단순히 language modeling loss만으로 학습하기 어렵습니다. 이유는 router가 특정 expert에 token을 몰아줄 수 있기 때문입니다.
예를 들어 expert가 8개 있는데 router가 계속 expert 1번과 2번만 사용한다면, 나머지 expert는 거의 학습되지 않습니다. 그러면 MoE의 장점인 “여러 expert의 전문화”가 제대로 일어나지 않습니다.
그래서 MoE에서는 보통 다음과 같은 보조 목적이 들어갑니다.
- expert 사용량을 균등하게 만들기 위한 load balancing loss
- router score가 너무 한쪽으로 쏠리지 않게 하는 regularization
- expert capacity를 넘는 token을 처리하기 위한 capacity 관련 규칙
Page 26의 핵심은 다음입니다.
MoE의 핵심 설계 변수는 router가 expert를 고르는 방식, expert 하나의 크기, 그리고 router와 expert를 안정적으로 학습시키기 위한 objective입니다.
Page 27. Routing function - overview
Router란?
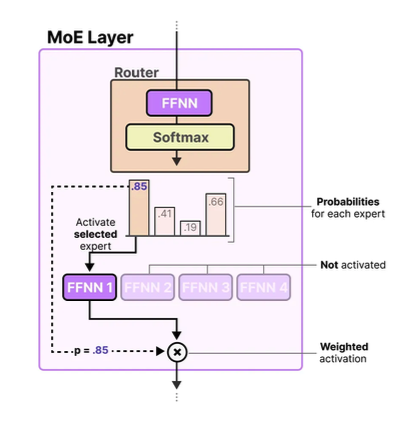
- Router is used to choose the expert based on an input
- It outputs probabilities which it uses to select the best matching expert
- Router is also a FFN
Page 27은 MoE routing function의 큰 유형을 보여줍니다.
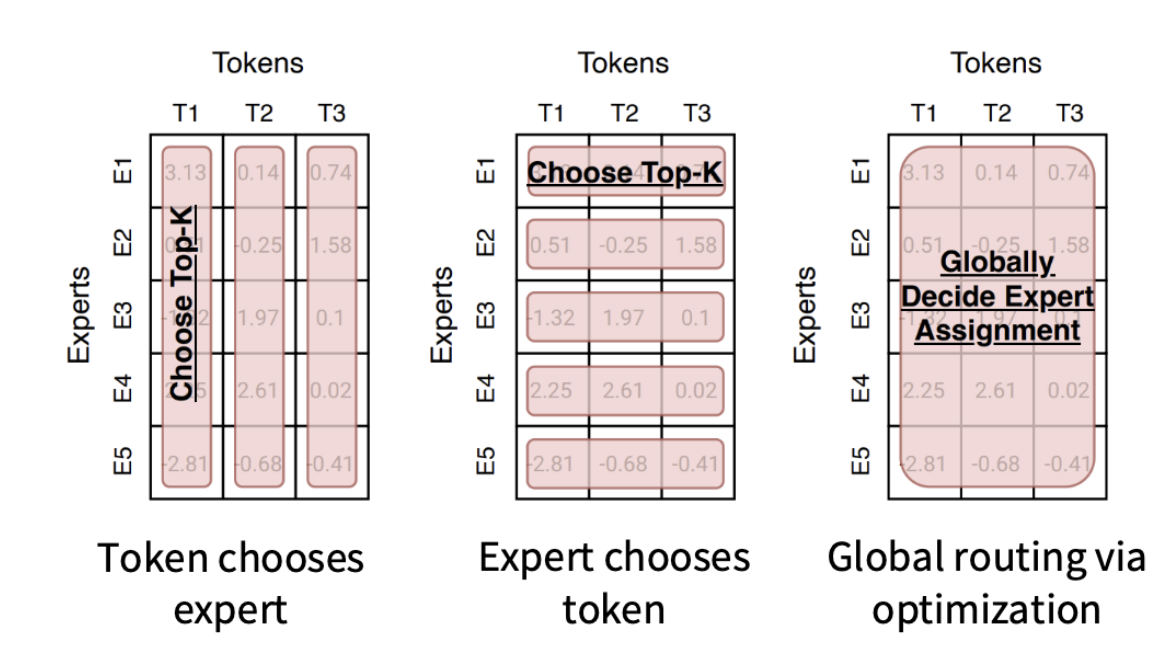
슬라이드의 핵심 문장은 다음입니다.
Many of the routing algorithms boil down to ‘choose top k’
즉, routing 알고리즘에는 여러 종류가 있지만, 많은 경우 결국 “점수가 높은 top-k를 고른다”는 문제로 정리됩니다.
슬라이드에서는 routing 방식을 세 가지로 나눕니다.
1. Token chooses expert
2. Expert chooses token
3. Global routing via optimization
1. Token chooses expert
가장 일반적인 방식입니다.
각 token이 자기에게 맞는 expert를 선택합니다.
예를 들어 token이 하나 들어오면 router가 expert 1번부터 expert 8번까지 점수를 계산합니다.
Token A에 대한 expert score
Expert 1: 0.10
Expert 2: 0.72
Expert 3: 0.05
Expert 4: 0.61
Expert 5: 0.20
Expert 6: 0.01
Expert 7: 0.12
Expert 8: 0.09
만약 top-2 routing이라면 Token A는 Expert 2와 Expert 4로 보내집니다.
Token A → Expert 2, Expert 4
이 방식이 token-choice top-k routing입니다.
장점은 단순하고 병렬화가 쉽다는 점입니다. 각 token이 독립적으로 expert를 고르기 때문에 GPU/TPU에서 구현하기 쉽고, 대규모 LLM 학습에 적합합니다.
2. Expert chooses token
두 번째는 expert가 token을 선택하는 방식입니다.
이번에는 관점이 반대입니다. token이 expert를 고르는 것이 아니라, expert가 “내가 처리할 token은 무엇인가?”를 고릅니다.
예를 들어 Expert 1이 전체 token 중 자신에게 가장 잘 맞는 token 몇 개를 선택합니다.
Expert 1 → Token 3, Token 9, Token 12 선택
Expert 2 → Token 1, Token 4, Token 7 선택
이 방식은 expert별 load를 조절하기 좋을 수 있습니다. 왜냐하면 expert가 처리할 token 수를 직접 제한할 수 있기 때문입니다.
하지만 실제 대규모 학습에서는 token-choice 방식보다 구현이 복잡하고, 일반적인 LLM MoE에서는 덜 널리 쓰입니다.
3. Global routing via optimization
세 번째는 전체 token과 전체 expert의 배정을 한 번에 최적화 문제로 푸는 방식입니다.
즉, 각 token이 독립적으로 고르는 것이 아니라 다음과 같은 전체 배정 문제를 풉니다.
“전체 token을 expert들에게 배정하되, 점수는 최대화하고 expert load는 균형 있게 유지하자.”
이 방식은 이론적으로는 깔끔합니다. 하지만 매 layer, 매 batch마다 이런 최적화 문제를 풀어야 한다면 비용이 큽니다.
그래서 실제 대규모 LLM에서는 대부분 더 단순한 top-k routing을 사용합니다.
Page 27의 핵심은 다음입니다.
Routing은 여러 방식으로 정의할 수 있지만, 실제로는 대부분 token별 expert score를 계산하고 top-k expert를 선택하는 방식으로 수렴합니다.
Page 29. Common routing variants in detail
Page 29는 대표적인 routing variant를 조금 더 구체적으로 비교합니다.
슬라이드에서는 크게 두 가지를 보여줍니다.
1. Top-k routing
2. Hash routing
1. Top-k routing
Top-k routing은 현재 대부분의 MoE에서 사용되는 방식입니다.
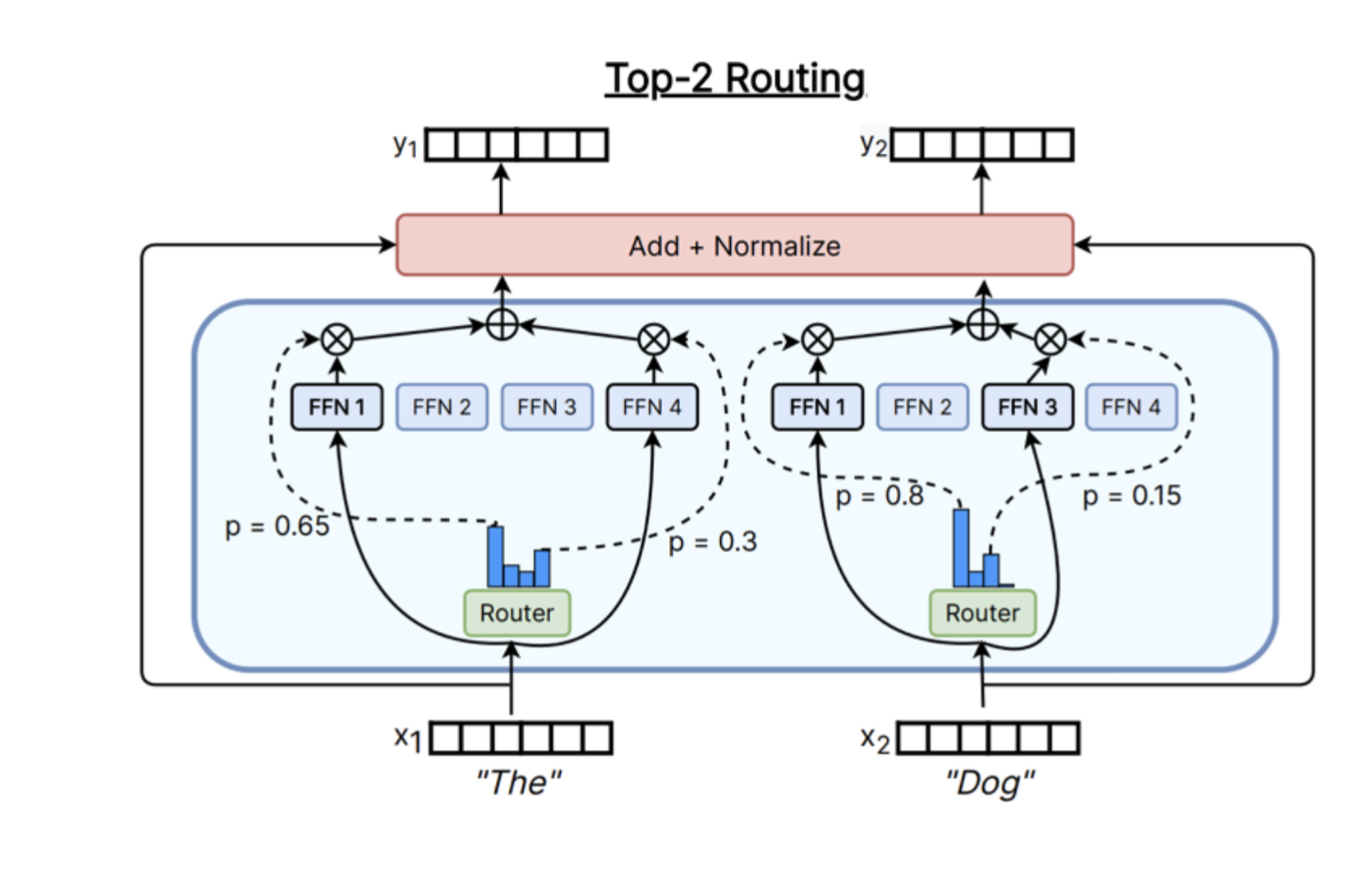
각 token에 대해 router가 expert 점수를 계산하고, 그중 가장 높은 $k$개 expert를 선택합니다.
Expert score = [0.10, 0.72, 0.05, 0.61]
k = 2라면:
선택 expert = Expert 2, Expert 4
슬라이드에는 여러 모델의 예시가 나옵니다.
| 모델 | Routing 설정 |
|---|---|
| Switch Transformer | $k=1$ |
| GShard | $k=2$ |
| Grok | $k=2$ |
| Mixtral | $k=2$ |
| Qwen | $k=4$ |
| DBRX | $k=4$ |
| DeepSeek | $k=7$ |
여기서 $k$는 token 하나가 몇 개의 expert를 사용할지를 의미합니다.
-
$k=1$: token 하나가 expert 하나만 사용합니다.
-
$k=2$: token 하나가 expert 두 개를 사용합니다.
-
$k=4$: token 하나가 expert 네 개를 사용합니다.
$k$가 커지면 token이 더 많은 expert를 활용할 수 있어 표현력은 좋아질 수 있습니다. 하지만 그만큼 active computation이 늘어납니다.
예를 들어 expert가 8개인 모델에서 $k=2$라면, token 하나는 8개 expert 중 2개만 사용합니다.
이것이 MoE의 sparse activation입니다.
2. Hash routing
Hash routing은 router가 학습해서 expert를 고르는 것이 아니라, hash function을 사용해 token을 expert에 배정하는 방식입니다.
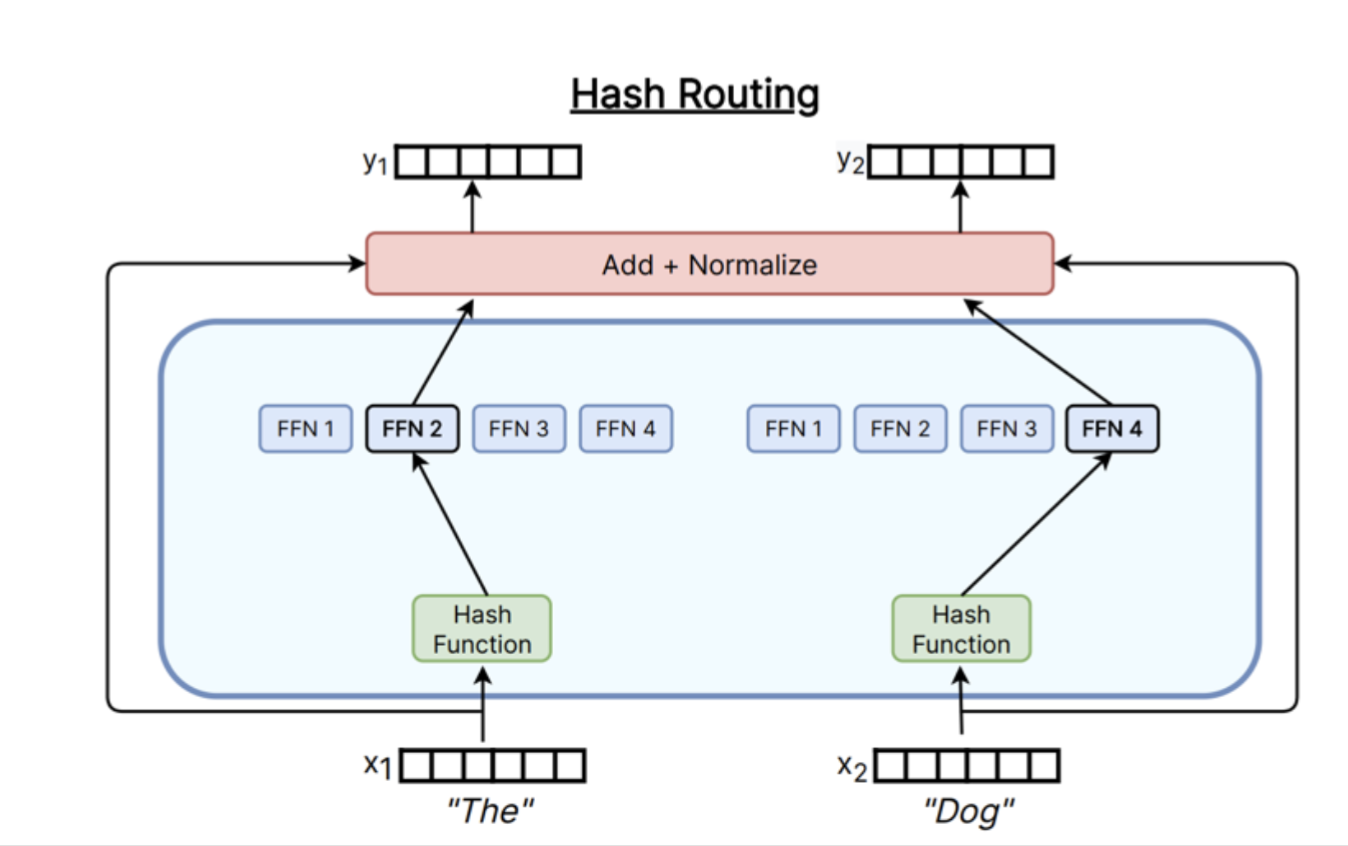
예를 들어 token id나 token representation에 hash function을 적용해 expert 번호를 정합니다.
hash(token) mod num_experts = expert id
이 방식은 단순하고 baseline으로 쓰기 좋습니다. 하지만 token의 의미나 문맥에 따라 expert를 유연하게 선택하는 능력은 제한적입니다.
따라서 hash routing은 “학습 가능한 router가 정말 필요한가?”를 확인하기 위한 common baseline으로 볼 수 있습니다.
Page 29의 핵심은 다음입니다.
실전 MoE의 중심은 top-k routing이고, hash routing은 단순 baseline으로 자주 비교됩니다.
Page 30. Other routing methods
Page 30은 top-k routing 이외의 routing 방법을 소개합니다.
슬라이드에서는 두 가지가 나옵니다.
1. RL to learn routes
2. Solve a matching problem
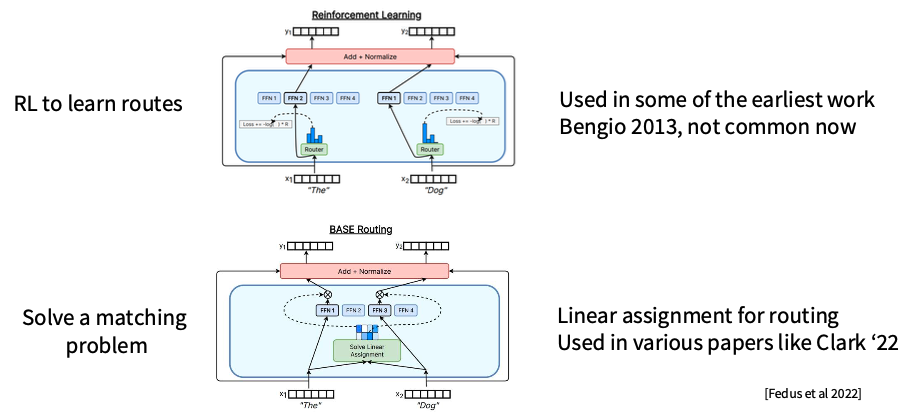
1. RL to learn routes
첫 번째는 reinforcement learning, 즉 강화학습으로 route를 학습하는 방법입니다.
MoE routing은 본질적으로 discrete decision입니다.
Token을 Expert 1로 보낼 것인가?
Expert 2로 보낼 것인가?
Expert 3으로 보낼 것인가?
이런 선택은 argmax나 top-k 같은 discrete operation을 포함하므로, 일반적인 gradient descent로 직접 학습하기 어렵습니다.
그래서 초기 연구에서는 router의 선택을 action으로 보고, 좋은 expert를 선택하면 reward를 주는 식의 RL 접근을 사용하기도 했습니다.
하지만 현재 대규모 LLM MoE에서는 흔하지 않습니다.
이유는 다음과 같습니다.
-
RL은 학습이 불안정할 수 있습니다.
-
대규모 언어모델 학습에 추가적인 복잡도를 크게 증가시킵니다.
-
top-k routing과 load balancing loss만으로도 충분히 좋은 성능을 얻는 경우가 많습니다.
슬라이드에서도 “Bengio 2013, not common now”라고 설명합니다.
2. Solve a matching problem
두 번째는 routing을 matching problem으로 푸는 방식입니다.
이는 전체 token과 expert 사이의 배정을 최적화 문제로 보는 접근입니다.
예를 들어 batch 안에 token이 100개 있고 expert가 4개 있다고 합시다. 그러면 다음과 같은 제약을 두고 배정할 수 있습니다.
목표: token-expert score의 총합을 최대화
제약: expert마다 처리하는 token 수가 너무 불균형하면 안 됨
이 문제는 linear assignment 또는 matching 문제로 풀 수 있습니다.
장점은 load balancing을 자연스럽게 반영할 수 있다는 점입니다. 하지만 단점은 계산과 구현이 복잡하다는 점입니다.
대규모 Transformer 학습에서는 매 layer, 매 batch, 매 step마다 routing을 해야 합니다. 따라서 routing 자체가 너무 비싸면 MoE의 효율성 이점이 줄어듭니다.
Page 31. Top-K routing in detail
Page 31은 top-k routing이 실제로 어떻게 계산되는지를 수식으로 보여줍니다.
이 페이지는 MoE routing을 이해하는 데 매우 중요합니다.
슬라이드의 핵심 수식은 다음과 같습니다.
h_t^l = \sum_{i=1}^{N} \left(g_{i,t}\mathrm{FFN}_i(u_t^l)\right) + u_t^l
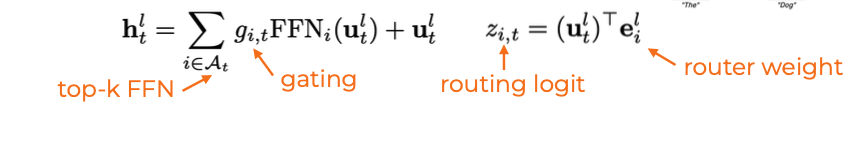
여기서 각 기호는 다음을 의미합니다.
| 기호 | 의미 |
|---|---|
| $t$ | token 위치 |
| $l$ | layer 번호 |
| $u_t^l$ | layer $l$에서 MoE FFN에 들어가는 token hidden state |
| $\mathrm{FFN}_i$ | $i$번째 expert FFN |
| $N$ | 전체 expert 개수 |
| $g_{i,t}$ | token $t$가 expert $i$를 얼마나 사용할지 나타내는 gate 값 |
| $h_t^l$ | MoE block을 통과한 후의 출력 hidden state |
이 식은 말로 풀면 다음과 같습니다.
token $t$를 여러 expert FFN에 넣고, 선택된 expert 출력만 gate weight로 가중합한 뒤, residual connection으로 원래 입력 $u_t^l$를 더합니다.
1. 왜 모든 expert 합처럼 보이는가?
수식에는 $\sum_{i=1}^{N}$이 있으므로 모든 expert를 다 쓰는 것처럼 보일 수 있습니다.
하지만 실제로는 그렇지 않습니다. 핵심은 $g_{i,t}$입니다.
Top-k routing에서는 선택되지 않은 expert의 gate 값이 0이 됩니다.
예를 들어 expert가 4개이고 top-2 routing이라고 합시다.
Expert score
E1: 0.10
E2: 0.70
E3: 0.05
E4: 0.60
Top-2 expert는 E2와 E4입니다. 그러면 gate는 다음처럼 됩니다.
g_1,t = 0
g_2,t = 0.70
g_3,t = 0
g_4,t = 0.60
따라서 실제 출력은 다음과 같습니다.
h_t^l = 0.70\mathrm{FFN}_2(u_t^l) + 0.60\mathrm{FFN}_4(u_t^l) + u_t^l
즉, 수식은 전체 expert에 대한 합으로 쓰지만, gate가 0인 expert는 계산에서 빠집니다.
2. gate 값 $g_{i,t}$는 어떻게 정해지는가?
슬라이드에서는 다음과 같이 정의합니다.
g_{i,t} =
\begin{cases}
s_{i,t}, & s_{i,t} \in \mathrm{TopK}(\{s_{j,t} \mid 1 \le j \le N\}, K) \\
0, & \mathrm{otherwise}
\end{cases}
이 식의 의미는 다음과 같습니다.
-
먼저 token $t$에 대해 모든 expert score $s_{1,t}, s_{2,t}, \ldots, s_{N,t}$를 계산합니다.
-
그중 상위 $K$개 score에 해당하는 expert만 선택합니다.
-
선택된 expert의 gate 값은 해당 score $s_{i,t}$가 됩니다.
-
선택되지 않은 expert의 gate 값은 0이 됩니다.
예를 들어 $N=5$, $K=2$라고 하겠습니다.
s_1,t = 0.12
s_2,t = 0.81
s_3,t = 0.43
s_4,t = 0.05
s_5,t = 0.67
상위 2개는 $s_{2,t}=0.81$, $s_{5,t}=0.67$입니다.
따라서:
g_1,t = 0
g_2,t = 0.81
g_3,t = 0
g_4,t = 0
g_5,t = 0.67
이렇게 gate vector가 sparse해집니다.
3. score $s_{i,t}$는 어떻게 계산되는가?
슬라이드에서는 score를 다음처럼 씁니다.
s_{i,t} = \mathrm{Softmax}_i\left((u_t^l)^T e_i^l\right)
여기서 $e_i^l$는 layer $l$에서 $i$번째 expert를 나타내는 embedding 또는 routing weight라고 볼 수 있습니다.
즉, router는 token hidden state $u_t^l$와 expert embedding $e_i^l$의 dot product를 계산합니다.
(u_t^l)^T e_i^l
이 값이 크다는 것은 token hidden state가 expert $i$의 방향과 잘 맞는다는 뜻입니다.
직관적으로는 다음과 같습니다.
현재 token 표현 u_t^l
↓
각 expert embedding e_i^l와 dot product
↓
expert별 적합도 score 계산
↓
softmax로 확률처럼 변환
↓
top-k expert 선택
4. 간단한 숫자 예시
expert가 4개 있다고 하겠습니다.
Expert 1 score: 1.2
Expert 2 score: 3.4
Expert 3 score: 0.7
Expert 4 score: 2.8
softmax를 거치면 대략 다음과 같은 확률이 될 수 있습니다.
Expert 1: 0.07
Expert 2: 0.60
Expert 3: 0.04
Expert 4: 0.29
만약 $K=2$라면 Expert 2와 Expert 4가 선택됩니다.
출력은 다음처럼 됩니다.
h_t^l = 0.60\mathrm{FFN}_2(u_t^l) + 0.29\mathrm{FFN}_4(u_t^l) + u_t^l
이것이 top-k routing의 핵심입니다.
5. softmax를 언제 적용하는가?
슬라이드 오른쪽에는 다음 설명이 있습니다.
Mixtral, DBRX, DeepSeek v3 softmaxes after the TopK
즉, 모델마다 softmax 적용 순서가 다를 수 있습니다.
방식 A. 먼저(Pre) softmax, 그다음 top-k
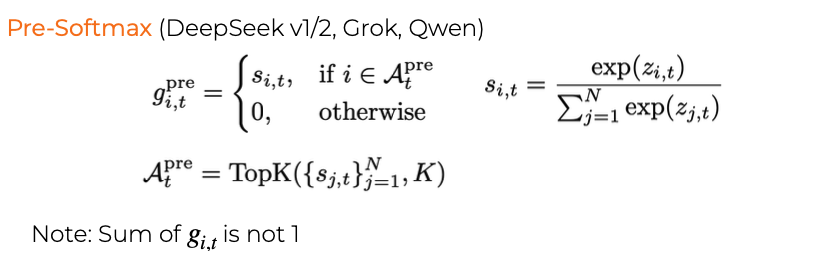
raw scores → softmax → top-k 선택 → 나머지 0
이 방식에서는 전체 expert에 대해 확률을 먼저 만든 뒤 top-k를 고릅니다.
방식 B. 먼저 top-k, 그다음 선택된 expert 안에서 softmax

raw scores → top-k 선택 → 선택된 expert끼리만 softmax
Mixtral, DBRX, DeepSeek v3는 이쪽 방식에 가깝다고 슬라이드에서 설명합니다.
이 방식의 직관은 다음과 같습니다.
어차피 선택되지 않은 expert는 사용하지 않을 것이므로, 선택된 top-k expert 사이에서만 gate weight를 정규화하자.
Page 32. Recent variations from DeepSeek and other Chinese LMs
Page 32는 최근 DeepSeek, Qwen 계열 등에서 보이는 MoE 설계 변형을 설명합니다.
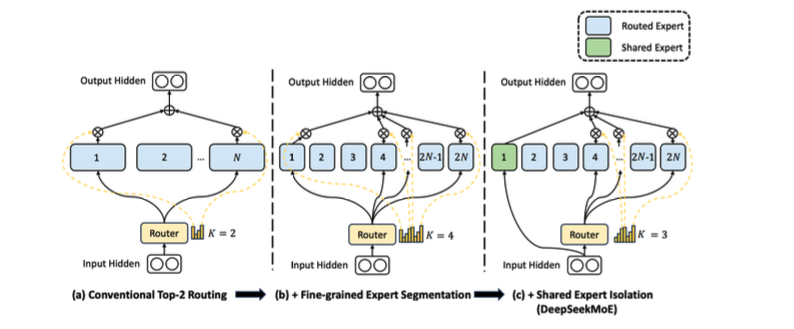
슬라이드의 핵심 문장은 다음입니다.
Smaller, larger number of experts + a few shared experts that are always on.
즉, 최근 MoE는 다음 두 방향으로 가는 경우가 많습니다.
1. expert를 더 작게 만든다.
2. expert 개수를 더 많이 둔다.
3. 일부 shared expert는 항상 켠다.
1. Conventional top-2 routing
기본 top-2 routing에서는 token 하나가 여러 expert 중 2개를 선택합니다.
Token → Router → Expert 1, Expert 4 선택
이때 선택된 expert만 활성화되고 나머지 expert는 사용되지 않습니다.
2. Fine-grained expert segmentation
최근 변형 중 하나는 expert를 더 작게 쪼개는 것입니다.
예를 들어 기존에는 큰 expert 8개를 두었다면, 이를 더 작은 expert 32개 또는 64개로 나누는 식입니다.
기존:
큰 expert 8개
변형:
작은 expert 32개
이렇게 하면 token이 선택할 수 있는 expert 후보가 많아집니다. expert 하나는 작지만, 더 세밀한 전문화가 가능해질 수 있습니다.
슬라이드에서는 이를 fine-grained expert segmentation으로 보여줍니다.
3. Shared expert isolation
또 다른 변형은 shared expert를 두는 것입니다.
shared expert는 router가 선택하지 않아도 항상 사용되는 expert입니다.
Token → Shared expert는 항상 통과
Token → Routed expert는 router가 선택
왜 shared expert가 필요할까요?
모든 token에 공통적으로 필요한 기본적인 언어 처리 능력이나 일반 지식이 있을 수 있습니다. 이런 공통 기능까지 routed expert들이 매번 나누어 맡으면, expert specialization이 불안정해질 수 있습니다.
그래서 shared expert를 두면 다음과 같은 역할 분리가 가능합니다.
Shared expert:
모든 token에 필요한 공통 처리 담당
Routed experts:
token별로 다른 전문 처리 담당
DeepSeekMoE 같은 구조는 shared expert와 routed expert를 분리해서, 공통 능력과 전문 능력을 함께 가져가려는 방향으로 볼 수 있습니다.
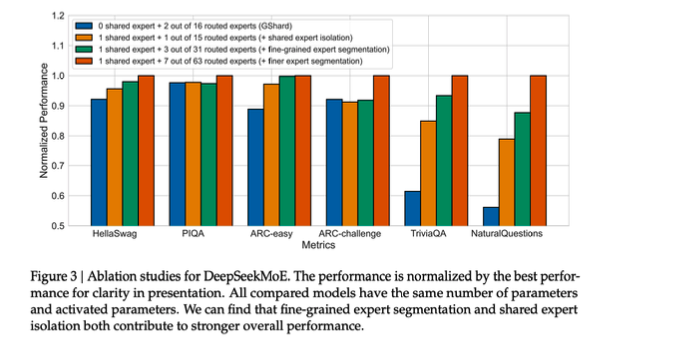
Page 32의 핵심은 다음입니다.
최근 MoE는 expert를 더 작게 쪼개 선택지를 늘리고, shared expert를 항상 켜서 공통 능력을 보존하는 방향으로 발전하고 있습니다.
Page 34. Ablations from OlMoE
Page 34는 OlMoE의 ablation 결과를 보여줍니다.
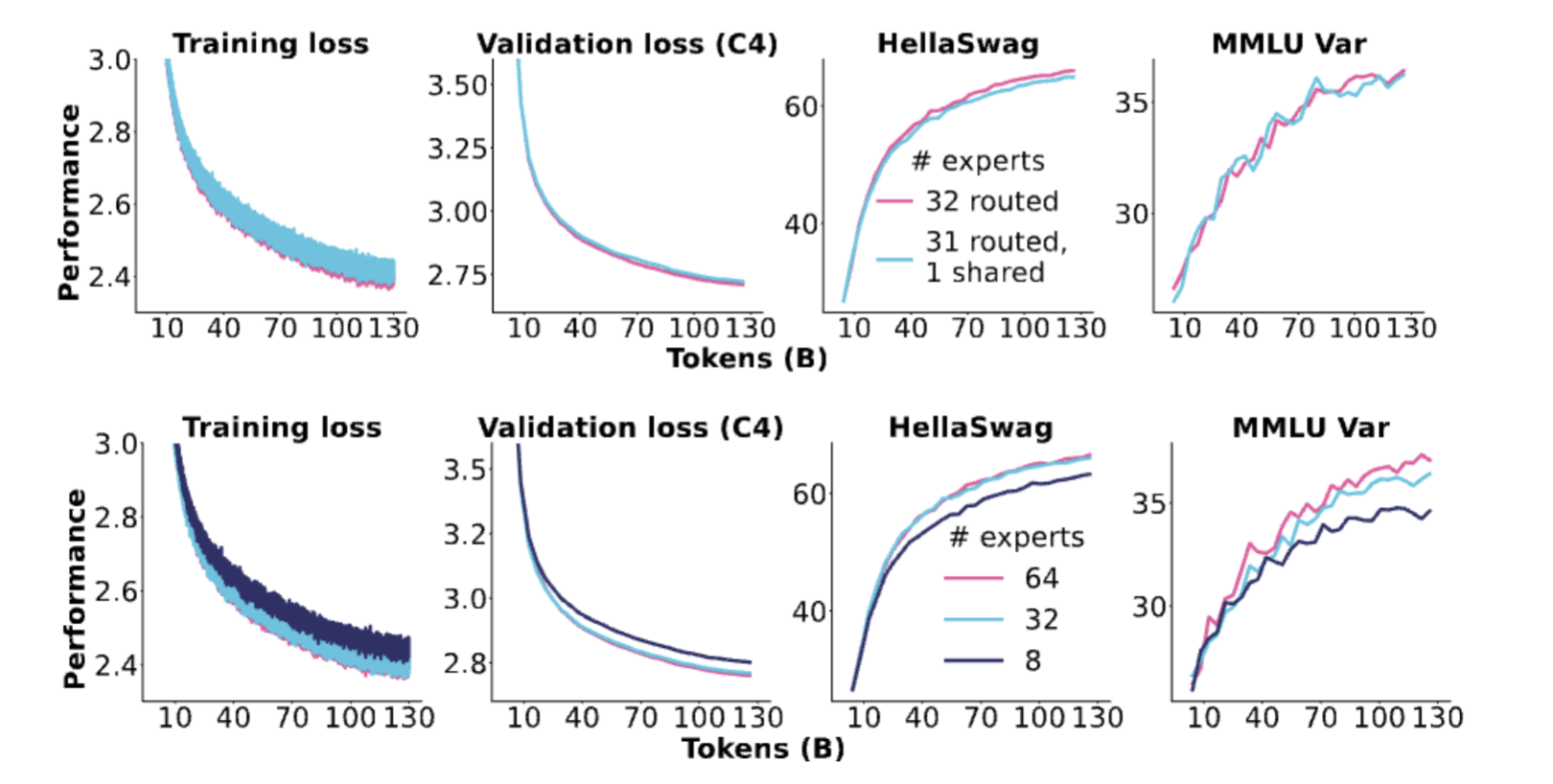
슬라이드의 핵심 문장은 다음입니다.
Gains from fine-grained exports, none from shared experts.
즉, OlMoE에서는 다음과 같은 결과가 강조됩니다.
-
fine-grained expert는 성능 향상에 도움이 됨
-
shared expert는 뚜렷한 이득이 없었음
이 결과는 Page 33의 DeepSeek 결과와 약간 다릅니다.
1. Fine-grained experts는 왜 도움이 되었는가?
Fine-grained expert는 expert 하나를 더 작게 만들고, expert 수를 더 많이 두는 방식입니다.
이 방식의 장점은 선택지가 많아진다는 것입니다.
큰 expert 8개
→ 선택지는 적음
작은 expert 64개
→ 선택지가 많음
선택지가 많으면 router가 token별로 더 세밀하게 expert를 배정할 수 있습니다.
예를 들어 수학 관련 token, 코드 관련 token, 일반 설명 token, 특정 문법 패턴 token이 있을 때, 작은 expert가 많으면 각각의 패턴에 더 특화된 expert가 생길 가능성이 있습니다.
2. Shared experts는 왜 항상 도움이 되지 않을 수 있는가?
shared expert는 모든 token이 항상 사용하는 expert입니다. 직관적으로는 좋아 보입니다. 모든 token에 필요한 공통 기능을 맡길 수 있기 때문입니다.
하지만 항상 이득이 되는 것은 아닙니다.
가능한 이유는 다음과 같습니다.
이유 1. shared expert가 capacity를 차지할 수 있습니다.
shared expert도 파라미터와 계산량을 사용합니다. 만약 shared expert가 충분한 추가 이득을 주지 못한다면, 그 자원을 routed expert에 쓰는 편이 나을 수 있습니다.
이유 2. routed expert의 specialization을 방해할 수 있습니다.
shared expert가 항상 켜지면, 모델이 공통 처리를 shared expert에 너무 의존할 수 있습니다. 그러면 routed expert들이 충분히 특화되지 않을 가능성도 있습니다.
이유 3. 학습 설정에 따라 효과가 달라질 수 있습니다.
shared expert의 효과는 모델 크기, 데이터 규모, router objective, expert 크기 등에 따라 달라질 수 있습니다.
따라서 DeepSeek에서는 shared expert가 도움이 되었지만, OlMoE에서는 뚜렷한 이득이 없었다고 볼 수 있습니다.
Page 35.
Expert routing setups for recent MoEs
Page 35는 최근 MoE 모델들의 routing setup을 표로 비교합니다.
표의 열은 다음을 의미합니다.
| 열 | 의미 |
|---|---|
| Model | MoE 모델 이름 |
| Routed | router가 선택할 수 있는 routed expert 수 |
| Active | token 하나가 실제로 사용하는 routed expert 수 |
| Shared | 항상 켜지는 shared expert 수 |
| Fine-grained ratio | expert 하나의 상대적 크기 또는 세분화 정도 |
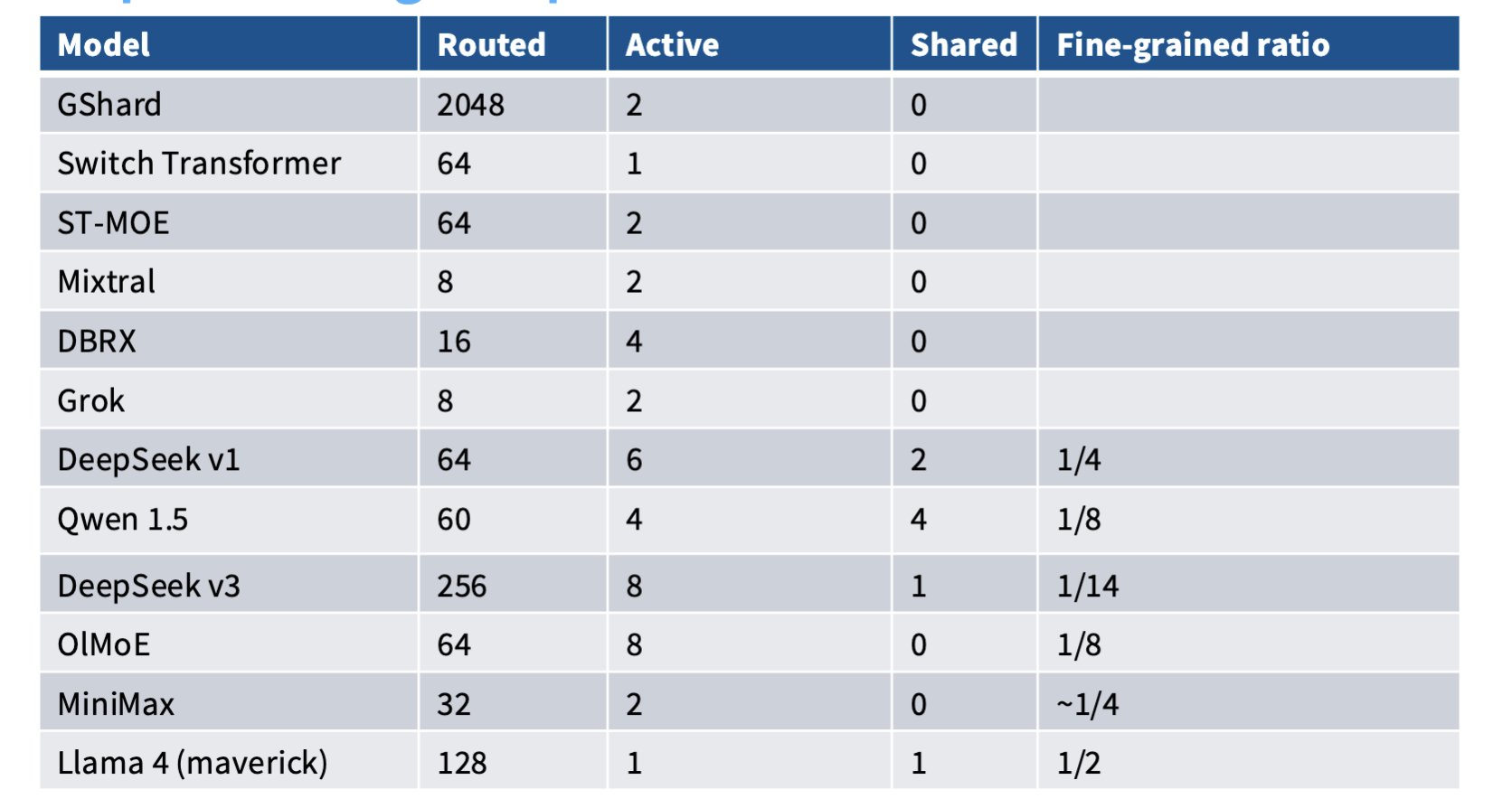
최근 MoE 모델들은 routed expert 수, active expert 수, shared expert 수, expert 세분화 비율을 다르게 조합하면서 capacity와 compute 사이의 균형을 맞추고 있습니다.
Page 36. How do we train MoEs?
Mixture-of-Experts(MoE)는 여러 개의 FFN expert를 두고, 각 token마다 일부 expert만 선택해 계산하는 sparse model 구조입니다. 전체 파라미터 수는 크게 늘릴 수 있지만, token당 활성화되는 파라미터 수는 제한할 수 있다는 점이 핵심입니다.
MoE 학습에서 가장 어려운 부분은 routing입니다. Router는 각 token을 어떤 expert로 보낼지 결정합니다. 보통 top-k expert를 선택하는데, 이 선택은 이산적인 결정이므로 일반적인 gradient descent로 직접 최적화하기 어렵습니다.
핵심 문제는 다음과 같습니다.
- token마다 적절한 expert를 선택해야 합니다.
- 특정 expert에 token이 몰리면 load imbalance가 생깁니다.
- 어떤 expert는 과도하게 학습되고, 어떤 expert는 거의 학습되지 않을 수 있습니다.
- expert가 여러 GPU에 분산되어 있으면 load imbalance가 곧 system bottleneck으로 이어집니다.
top-krouting은 discrete operation이므로 학습 안정성이 떨어질 수 있습니다.
따라서 MoE 학습에서는 routing 안정화와 load balancing이 매우 중요합니다.
Page 37. RL for MoEs
Page37은 MoE의 routing 문제를 강화학습으로 풀 수 있는지를 설명합니다.
앞선 Page 36에서 본 핵심 문제는 sparse gating decision이 미분 가능하지 않다는 점이었습니다. token이 어떤 expert로 갈지 선택하는 과정은 top-k 선택이기 때문에, 일반적인 gradient descent로 직접 최적화하기 어렵습니다.
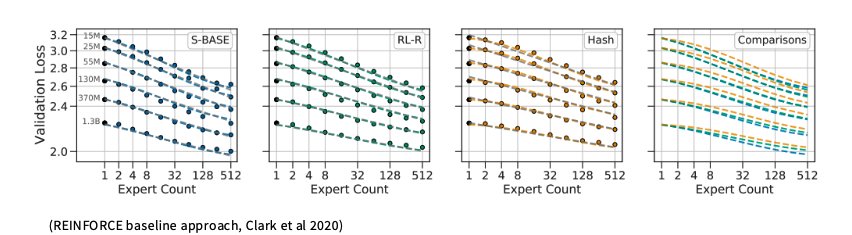
이 문제를 가장 정석적으로 보면, router는 하나의 policy처럼 볼 수 있습니다.
입력 token x
→ router가 expert 선택 확률을 만듦
→ expert 선택 = action
→ 선택 결과에 따른 loss 또는 reward를 보고 policy를 업데이트
이 관점에서는 REINFORCE 같은 강화학습 방법을 사용할 수 있습니다. 실제로 슬라이드에서도 RL via REINFORCE가 작동한다고 말합니다.
하지만 중요한 결론은 다음입니다.
RL은 이론적으로는 sparse routing을 다루는 자연스러운 방법이지만, 실제로는 gradient variance와 구현 복잡도가 커서 널리 쓰이지 않습니다.
REINFORCE는 discrete action에 대해 gradient를 추정할 수 있다는 장점이 있습니다. 그러나 추정 분산이 큽니다. 즉, 같은 입력과 비슷한 routing decision에서도 학습 신호가 불안정하게 튈 수 있습니다.
MoE 학습에서는 이미 다음 문제가 있습니다.
- expert 선택이 불안정함
- 특정 expert에 token이 몰릴 수 있음
- expert별 학습량이 달라질 수 있음
- 여러 GPU에 expert가 분산되면 communication cost가 커짐
여기에 RL 기반 학습의 gradient variance까지 더해지면 학습 안정성이 더 나빠질 수 있습니다.
따라서 Page 37의 핵심은 다음입니다.
MoE routing을 RL로 푸는 것은 개념적으로는 맞는 접근이지만, 실제 대규모 MoE에서는 더 단순하고 안정적인 stochastic approximation이나 load balancing loss가 더 자주 사용됩니다.
Page 38. Stochastic approximations
Page 38은 MoE routing을 학습하기 위한 두 번째 접근인 stochastic approximation을 설명합니다.
 Shazeer et al. 2017의 방식에서는 routing decision을 완전히 deterministic하게 만들지 않고, router score에 Gaussian noise를 추가합니다.
Shazeer et al. 2017의 방식에서는 routing decision을 완전히 deterministic하게 만들지 않고, router score에 Gaussian noise를 추가합니다.
흐름을 단순화하면 다음과 같습니다.
입력 x
→ router score 계산
→ score에 Gaussian noise 추가
→ noisy score 기준으로 top-k expert 선택
→ 선택된 expert에 대해서만 softmax 수행
여기서 중요한 점은 noise가 단순한 랜덤성이 아니라, routing exploration을 돕는 역할을 한다는 것입니다.
만약 항상 같은 score로 top-k를 선택하면, 초기 학습에서 조금 높은 점수를 받은 expert가 계속 선택될 수 있습니다. 그러면 특정 expert만 계속 학습되고, 다른 expert는 거의 사용되지 않을 수 있습니다.
하지만 score에 noise를 추가하면 비슷한 점수를 가진 expert들이 번갈아 선택될 수 있습니다. 이로 인해 expert들이 조금 더 다양한 token을 보게 되고, 특정 expert에만 routing이 고정되는 현상을 완화할 수 있습니다.
슬라이드의 두 가지 포인트는 다음입니다.
-
stochastic routing은 expert를 더 robust하게 만들 수 있습니다.
-
softmax를 사용하기 때문에 모델은 단순히 하나의 expert만 고르는 것이 아니라, top-k expert들의 상대적 순위를 학습하게 됩니다.
즉, stochastic approximation은 discrete top-k routing의 문제를 완전히 없애지는 않지만, 학습 초기에 routing이 너무 brittle해지는 문제를 줄이는 practical한 방법입니다.
Page 39. Stochastic approximations
Page 39는 Fedus et al. 2022, 즉 Switch Transformer에서 사용한 stochastic jitter를 보여줍니다.
슬라이드의 코드 흐름은 다음과 같습니다.
if is_training:
# Add noise for exploration across experts.
router_logits += mtf.random_uniform(
shape=router_logits.shape,
minval=1-eps,
maxval=1+eps,
)
# Convert input to softmax operation from bfloat16 to float32 for stability.
router_logits = mtf.to_float32(router_logits)
# Probabilities for each token of what expert it should be sent to.
router_probs = mtf.softmax(router_logits, axis=-1)
이 방식의 핵심은 training 중 router logit에 작은 random perturbation을 주는 것입니다.
직관은 Page 38과 같습니다.
routing score가 너무 고정됨
→ 일부 expert만 계속 선택됨
→ expert specialization이 불안정해짐
→ score에 jitter를 추가해서 exploration을 유도
stochastic jitter는 expert들이 너무 일찍 고정되는 것을 막고, 더 다양한 token을 보게 하는 역할을 합니다. 슬라이드에서는 이를 “less brittle experts”를 만들기 위한 방법이라고 설명합니다.
아래 표는 baseline, input jitter, dropout을 비교합니다.
| Method | Fraction Stable | Quality ↑ |
|---|---|---|
| Baseline | 4/6 | -1.755 ± 0.02 |
| Input jitter $(10^{-2})$ | 3/3 | -1.777 ± 0.03 |
| Dropout (0.1) | 3/3 | -1.822 ± 0.11 |
여기서 중요한 점은 stochastic jitter가 안정성에는 도움을 줄 수 있지만, 항상 명확한 성능 향상을 보장하는 것은 아니라는 점입니다. 실제로 슬라이드에서도 이 방식은 이후 Zoph et al. 2022에서는 제거되었다고 설명합니다.
따라서 Page 39의 핵심은 다음입니다.
stochastic noise는 routing exploration을 도와 expert collapse를 완화할 수 있지만, 성능과 안정성 측면에서 항상 결정적인 해법은 아닙니다.
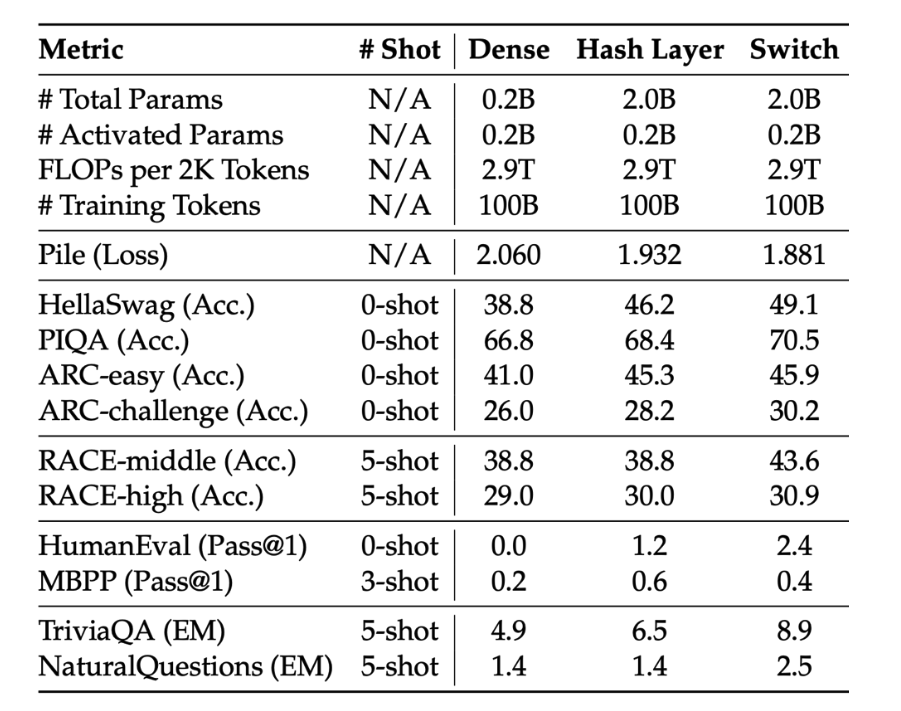
Page 40. Heuristic balancing losses
Page 40은 MoE 학습에서 가장 널리 쓰이는 접근인 heuristic load balancing loss를 설명합니다.
MoE에서는 token마다 일부 expert만 선택합니다. 이때 특정 expert에 token이 몰리면 문제가 생깁니다.
Expert 1: token 80% 처리
Expert 2: token 15% 처리
Expert 3: token 5% 처리
Expert 4: token 0% 처리
이런 상황에서는 두 가지 문제가 생깁니다.
-
자주 선택되는 expert는 과부하가 걸립니다.
-
거의 선택되지 않는 expert는 충분히 학습되지 않습니다.
특히 expert가 여러 GPU에 분산되어 있는 경우, 한 expert 또는 한 device에 token이 몰리면 전체 training throughput이 느려질 수 있습니다. 따라서 systems efficiency를 위해서는 expert를 가능한 한 균등하게 사용하는 것이 중요합니다.
Switch Transformer에서는 auxiliary loss를 추가해 expert 사용량을 균등하게 만들려고 합니다.
수식은 다음과 같습니다.
loss = \alpha \cdot N \cdot \sum_{i=1}^{N} f_i \cdot P_i
여기서 $f_i$는 실제로 expert $i$로 dispatch된 token의 비율입니다.
f_i = \frac{1}{T}\sum_{x \in \mathcal{B}} \mathbf{1}\{\arg\max p(x)=i\}
그리고 $P_i$는 router가 expert $i$에 할당한 평균 probability입니다.
P_i = \frac{1}{T}\sum_{x \in \mathcal{B}} p_i(x)
즉, 이 loss는 다음 두 값을 함께 봅니다.
f_i: 실제로 expert i가 얼마나 자주 선택되었는가?
P_i: router가 expert i에 평균적으로 얼마나 높은 확률을 주었는가?
어떤 expert가 너무 자주 선택되면 $f_i$가 커집니다. 이때 해당 expert에 대한 router probability $P_i$까지 크면 auxiliary loss가 커집니다.
따라서 모델은 자주 선택되는 expert의 probability를 낮추는 방향으로 학습됩니다.
슬라이드 하단의 문장은 이 점을 설명합니다.
더 자주 사용되는 expert일수록 더 강하게 downweighting됩니다.
정리하면 Page 40의 핵심은 다음입니다.
MoE에서는 성능뿐 아니라 system efficiency를 위해 expert를 고르게 사용하는 것이 중요하며, 이를 위해 실제 expert 사용 비율과 router probability를 함께 제어하는 auxiliary balancing loss를 사용합니다.
Page 43. What happens when removing load balancing losses?
Page 43은 load balancing loss를 제거했을 때 어떤 일이 생기는지를 보여줍니다.
슬라이드의 위쪽 그래프는 load balancing loss를 사용한 경우와 사용하지 않은 경우를 비교합니다.
- LBL: Load Balancing Loss 사용
- No LBL: Load Balancing Loss 미사용
핵심 관찰은 다음입니다.
-
Load balancing loss를 사용하면 validation loss가 더 안정적으로 낮아집니다.
-
Load balancing loss를 제거하면 expert 사용이 한쪽으로 치우칠 수 있습니다.
-
expert assignment가 불균형해지면 일부 expert는 과도하게 사용되고, 일부 expert는 거의 사용되지 않습니다.
아래 그래프는 이 현상을 더 직접적으로 보여줍니다.
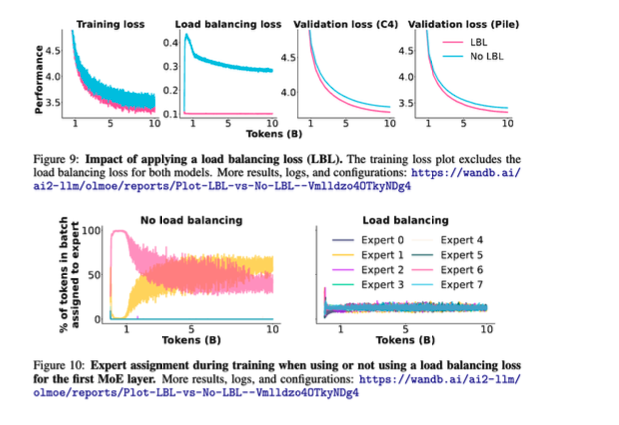
따라서 Page 43의 핵심은 다음입니다.
load balancing을 제거하면 expert 사용이 불균형해지고, 일부 expert만 학습되는 collapse가 발생할 수 있기 때문에, MoE 학습에서는 balancing mechanism이 필수적입니다.
Page 44 ~ 47. Training MoEs - the systems side
이 페이지부터는 MoE를 실제로 학습할 때의 시스템 관점을 다룹니다. 앞에서는 MoE의 핵심 아이디어가 “모든 토큰이 모든 FFN을 쓰지 않고, 일부 expert만 선택적으로 사용한다”는 것이었습니다. 이제 중요한 질문은 다음과 같습니다.
- MoE는 왜 대규모 분산 학습에 잘 맞는가?
- Expert를 여러 GPU에 어떻게 배치할 수 있는가?
- Routing 때문에 어떤 통신 비용과 병렬화 문제가 생기는가?
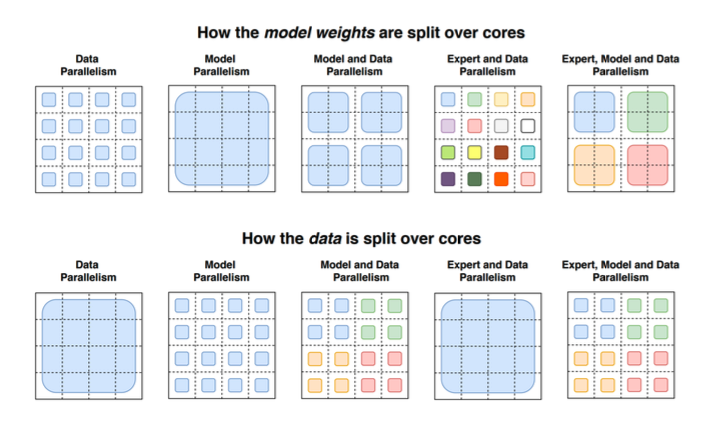
MoE는 구조적으로 병렬화하기 좋습니다. Transformer block 안의 attention은 모든 토큰이 공유하는 연산이지만, MoE의 FFN expert들은 서로 독립적인 MLP입니다. 따라서 expert들을 여러 device에 나누어 배치할 수 있습니다.
예를 들어 expert가 8개 있고 GPU가 여러 개라면, 각 GPU가 일부 expert를 담당하게 만들 수 있습니다. 토큰은 router에 의해 특정 expert로 보내지고, 해당 expert가 있는 GPU에서 FFN 계산을 수행합니다. 이런 방식은 expert parallelism이라고 볼 수 있습니다.
핵심은 MoE가 단순히 모델을 크게 만드는 기법이 아니라, 파라미터를 분산 배치하기 쉬운 구조라는 점입니다. Dense FFN 하나를 여러 GPU에 쪼개는 것보다, expert 단위로 나누는 것이 더 자연스럽습니다.
다만 이 장점에는 비용이 있습니다. 토큰이 어떤 expert로 갈지 동적으로 결정되기 때문에, 토큰을 expert가 있는 장치로 보내고 다시 모아야 합니다. 즉, MoE에서는 계산량은 줄어들 수 있지만, routing과 all-to-all communication 비용이 새 병목이 됩니다.
MoE 학습에서 생기는 대표적인 시스템 문제를 보여줍니다. MoE는 expert를 분산시킬 수 있어 병렬화에 유리하지만, 토큰을 expert로 보내는 과정 때문에 통신이 복잡해집니다.
MoE 학습에는 여러 병렬화 축이 함께 사용됩니다.
- Data parallelism: 서로 다른 GPU가 서로 다른 batch를 처리합니다.
- Tensor/model parallelism: 하나의 layer나 행렬 연산을 여러 GPU에 나눕니다.
- Expert parallelism: expert 자체를 여러 GPU에 나눠 배치합니다.
MoE에서 특히 중요한 것은 expert parallelism입니다. 각 expert는 독립적인 FFN이므로 GPU별로 expert를 나눠 가질 수 있습니다. 하지만 토큰은 batch 안에서 router에 의해 각기 다른 expert로 보내집니다. 따라서 어떤 GPU에서 생성된 토큰이 다른 GPU에 있는 expert로 이동해야 할 수 있습니다.
이때 필요한 통신 패턴이 all-to-all communication입니다. 각 GPU는 자신이 가진 토큰 중 일부를 다른 GPU의 expert로 보내고, expert 계산 후 다시 결과를 받아와야 합니다.
문제는 이 과정이 단순하지 않다는 점입니다. 토큰마다 선택되는 expert가 다르고, expert별 토큰 수가 매번 달라질 수 있기 때문입니다. 그래서 효율적인 MoE 학습을 위해서는 다음이 중요합니다.
- expert별 토큰 분포를 최대한 균형 있게 유지하기
- capacity 초과로 인한 token dropping 줄이기
- sparse expert 계산을 효율적인 GPU kernel로 구현하기
- all-to-all 통신 비용을 줄이기
이 맥락에서 MegaBlocks 같은 시스템은 MoE의 sparse computation을 더 효율적으로 처리하기 위해 제안되었습니다. 단순히 expert별로 토큰을 모아서 작은 행렬곱을 여러 번 하는 방식은 GPU 효율이 낮을 수 있습니다. MegaBlocks는 sparse block 구조를 활용해 MoE FFN 계산을 더 큰 연산 단위로 묶어 처리하려는 접근입니다.
정리하면, MoE의 난점은 모델링보다 시스템 구현에 가깝습니다. 이론적으로는 일부 expert만 쓰면 계산량이 줄어들지만, 실제로는 routing, dispatch, gather, load balancing, sparse kernel이 모두 잘 맞아야 효율이 납니다.
Page 48. Issues with MoEs - stability
이 페이지는 MoE training stability 문제를 다룹니다. 특히 router logit이 너무 커지는 문제와 이를 완화하기 위한 z-loss가 핵심입니다.
MoE router는 각 토큰이 어떤 expert로 갈지 결정합니다. 보통 hidden state를 입력으로 받아 expert별 score 또는 logit을 만들고, 그 값에 softmax를 적용해 routing probability를 계산합니다.
문제는 router logit의 scale이 너무 커질 수 있다는 점입니다. logit이 커지면 softmax가 매우 뾰족해지고, 일부 expert에 토큰이 과도하게 몰릴 수 있습니다. 그러면 load balancing이 무너지고, 특정 expert는 과부하가 걸리며, 다른 expert는 거의 사용되지 않는 상황이 생깁니다.
이를 완화하기 위해 Switch Transformer와 이후 MoE 계열에서는 router z-loss를 사용했습니다. 대표적인 형태는 다음과 같습니다.
L_z = \frac{1}{B} \sum_{i=1}^{B} \left( \log \sum_j \exp(x_j^{(i)}) \right)^2
여기서 $x_j^{(i)}$는 $i$번째 token에 대한 $j$번째 expert의 router logit입니다.
이 loss는 router logit의 log-sum-exp 값이 지나치게 커지지 않도록 제약합니다.
직관적으로 보면 z-loss는 router에게 다음과 같이 말하는 역할을 합니다.
expert를 고르는 것은 좋지만, logit scale을 너무 크게 만들지는 마라.
또한 MoE에서는 router 계산을 FP32로 유지하는 경우도 많습니다.
router는 작은 수치 차이로 expert 선택이 바뀌는 민감한 부분이기 때문에, 낮은 precision에서 불안정해질 수 있습니다.
정리하면 이 페이지의 핵심은 다음입니다.
-
MoE router는 학습 중 불안정해지기 쉽다.
-
router logit이 커지면 softmax가 과도하게 sharp해진다.
-
이로 인해 expert collapse나 load imbalance가 발생할 수 있다.
-
z-loss는 router logit scale을 제어해 학습을 안정화한다.
Page 49. Z-loss stability for the router
이 페이지는 z-loss를 제거했을 때 어떤 문제가 생기는지를 보여줍니다.
그림의 요지는 z-loss가 단순한 보조항이 아니라, 대규모 MoE 학습 안정성에 중요한 역할을 한다는 것입니다.
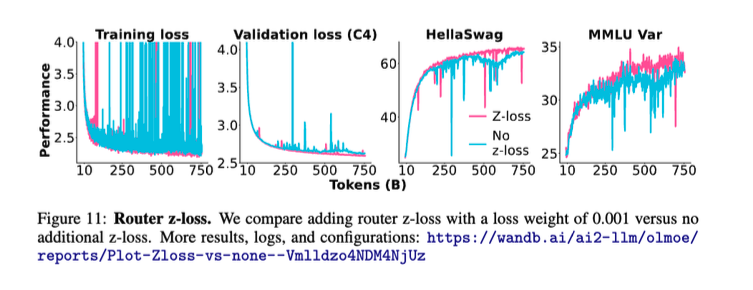
z-loss가 없으면 router logit scale이 커질 수 있고, routing distribution이 불안정해집니다.
그 결과 training loss가 갑자기 튀거나, 특정 expert가 과도하게 선택되는 현상이 나타날 수 있습니다.
MoE에서 routing이 불안정해지면 영향이 전체 모델로 전파됩니다.
왜냐하면 expert 선택은 단순한 regularization이 아니라 실제 forward path를 결정하기 때문입니다.
토큰이 어떤 expert를 거치는지가 바뀌면 FFN 계산 자체가 달라지고, expert별 gradient도 달라집니다.
이때 생기는 문제는 다음과 같습니다.
-
특정 expert에 토큰이 몰림
-
일부 expert는 거의 학습되지 않음
-
capacity overflow와 token dropping 증가
-
gradient variance 증가
-
loss spike 또는 training divergence 발생
따라서 MoE 학습에서는 일반적인 language modeling loss만으로는 충분하지 않습니다.
Router와 expert 사용 분포를 안정화하기 위한 보조 목적함수가 필요합니다.
이 페이지는 MoE에서 auxiliary loss가 “성능을 조금 올리기 위한 추가 장치”가 아니라, 학습을 가능하게 만드는 안정화 장치에 가깝다는 점을 강조합니다.
Page 50. Issues with MoEs - fine-tuning
이 페이지는 MoE를 fine-tuning할 때의 문제를 설명합니다.
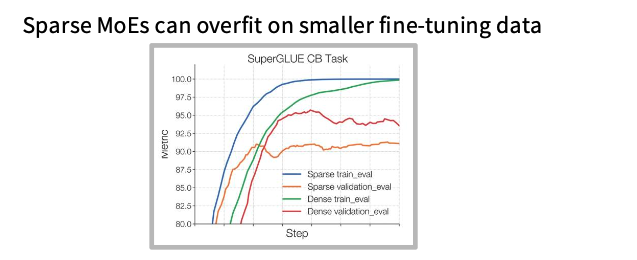
핵심은 MoE가 pretraining에서는 강력하지만, fine-tuning에서는 overfitting이나 instability가 발생하기 쉽다는 점입니다.
Zoph et al.의 결과에 따르면, MoE 모델을 그대로 fine-tuning하면 dense model보다 더 쉽게 과적합될 수 있습니다.
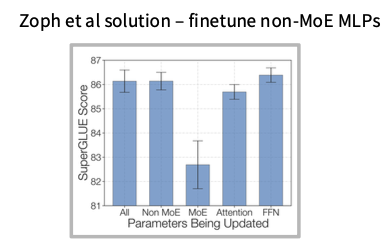
MoE는 전체 파라미터 수가 크고 expert별 specialization이 있기 때문에, 작은 fine-tuning 데이터에 민감하게 반응할 수 있습니다.
그래서 한 가지 방법은 fine-tuning할 때 MoE layer 전체를 업데이트하지 않고, 일부 non-MoE MLP 또는 dense component만 fine-tuning하는 것입니다.
즉, pretraining에서 얻은 expert 구조는 유지하고, task adaptation은 더 제한된 부분에서 수행하는 접근입니다.
슬라이드에서는 DeepSeek 계열의 해결 방식도 언급됩니다.

DeepSeek은 instruction tuning 단계에서 매우 많은 데이터를 사용했습니다.
예를 들어 약 1.4M SFT 데이터처럼 큰 규모의 instruction data를 사용하면, MoE의 큰 capacity가 작은 데이터에 과적합되는 문제를 어느 정도 완화할 수 있습니다.
정리하면 MoE fine-tuning에는 두 가지 방향이 있습니다.
- 첫째, 업데이트 범위를 줄이는 방법입니다.
expert 전체를 건드리지 않고 일부 모듈만 fine-tuning하여 안정성을 확보합니다.
- 둘째, fine-tuning 데이터 규모를 키우는 방법입니다.
MoE의 큰 capacity가 일반화될 수 있을 만큼 다양한 instruction data를 제공합니다.
이 관점은 LoRA나 instruction tuning을 할 때도 중요합니다.
MoE 모델은 dense model과 같은 방식으로 작은 데이터에 강하게 fine-tuning하면 성능이 좋아지기보다 오히려 expert specialization을 망가뜨릴 수 있습니다.
Page 51. Other training methods - upcycling
이 페이지는 Upcycling을 설명합니다.
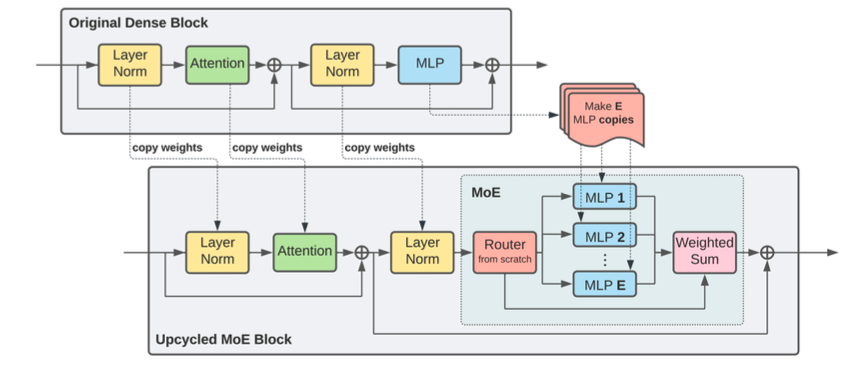
Upcycling은 이미 학습된 dense model을 MoE 모델의 초기값으로 재사용하는 방법입니다.
일반적으로 대규모 MoE를 처음부터 학습하려면 매우 많은 비용이 듭니다.
Dense model 하나를 pretrain하는 것도 비싼데, MoE는 전체 파라미터 수가 더 크기 때문에 scratch training 비용이 더 커집니다.
Upcycling의 아이디어는 간단합니다.
이미 학습된 dense Transformer가 있다면, 그 안의 FFN을 여러 expert의 초기값으로 복사하거나 변형해서 MoE로 확장하는 것입니다.
개념적으로는 다음과 같습니다.
Pretrained dense model
→ FFN weights를 여러 expert로 복사
→ router/gating module 추가
→ MoE model로 계속 학습
이 방식의 장점은 다음과 같습니다.
-
dense model이 이미 배운 representation을 재사용할 수 있음
-
MoE를 scratch에서 학습하는 것보다 비용이 줄어듦
-
초기 training instability를 줄일 수 있음
-
기존 dense checkpoint를 더 큰 sparse model로 확장할 수 있음
단, expert를 모두 같은 FFN에서 복사하면 처음에는 expert들이 거의 동일한 기능을 합니다.
따라서 이후 학습 과정에서 expert들이 서로 다른 역할로 분화되도록 routing과 load balancing이 잘 작동해야 합니다.
Upcycling은 MoE를 현실적으로 확장하기 위한 중요한 전략입니다.
이미 강한 dense base model이 있을 때, 이를 MoE로 바꾸어 더 큰 parameter capacity를 확보할 수 있기 때문입니다.
Page 52. Upcycling example - MiniCPM
이 페이지는 MiniCPM-MoE의 사례를 보여줍니다.
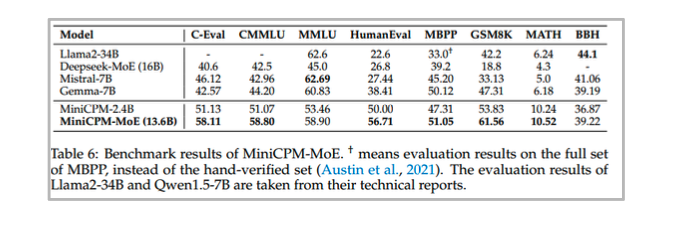
MiniCPM은 dense model을 기반으로 MoE 모델을 구성한 대표적인 upcycling 사례입니다.
- Base model: MiniCPM-2B
- MoE model: MiniCPM-MoE
- Experts: 8 experts
- Routing: top-k = 2
- Active parameters: 약 4B 수준
- Training tokens: 약 520B tokens
여기서 중요한 점은 전체 expert 수는 늘어나지만, 각 token이 사용하는 expert는 top-2로 제한된다는 것입니다.
따라서 전체 파라미터 수는 커지지만, token당 계산량은 제한됩니다.
MiniCPM-MoE는 dense MiniCPM-2B보다 더 큰 capacity를 갖습니다.
하지만 매 token마다 모든 expert를 쓰지 않기 때문에 active parameter 수는 상대적으로 작게 유지됩니다.
이 사례는 MoE의 장점을 잘 보여줍니다.
-
전체 parameter capacity는 증가한다.
-
token당 계산량은 dense 대형 모델보다 낮게 유지된다.
-
dense checkpoint를 기반으로 확장할 수 있다.
-
추가 pretraining을 통해 expert specialization을 유도할 수 있다.
즉, MoE는 “같은 계산량으로 더 많은 파라미터를 보유하는 방법”에 가깝습니다.
모든 파라미터를 매번 쓰는 것이 아니라, 필요한 expert subset만 사용하기 때문입니다.
Page 53. Upcycling example – Qwen MoE
이어서 Qwen-MoE의 upcycling 사례도 존재합니다.
Qwen-MoE는 Qwen 1.8B dense model을 기반으로 MoE 구조를 만든 사례로 소개됩니다.
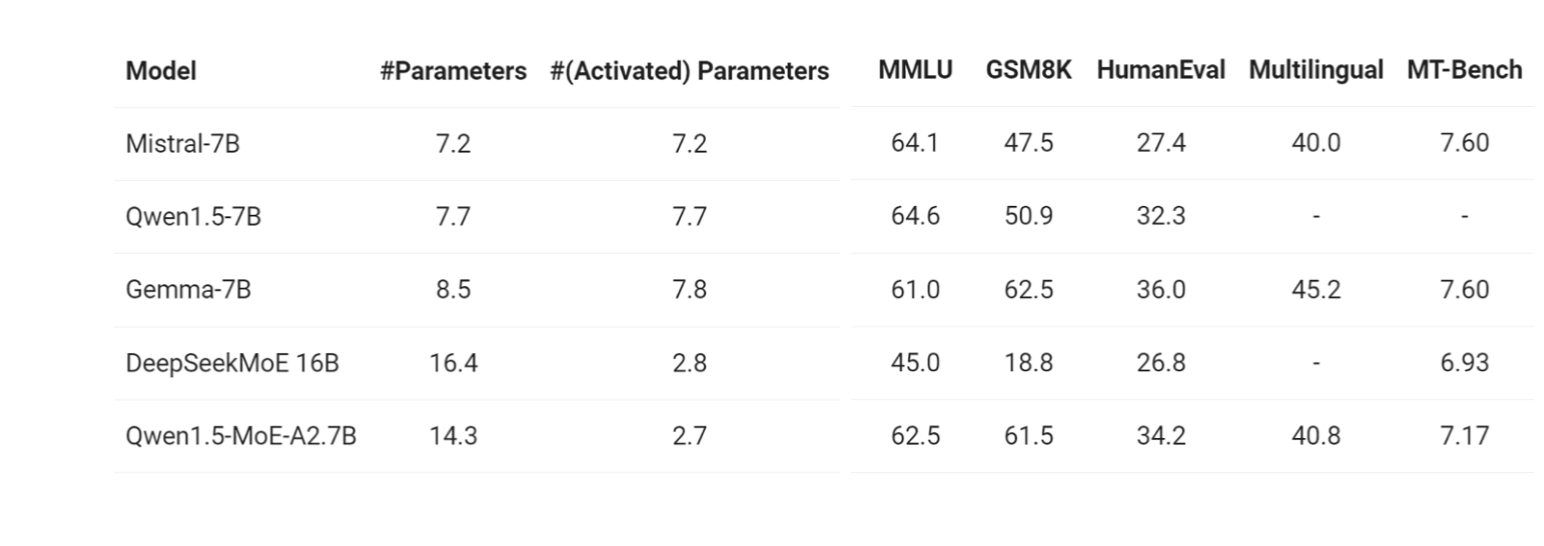 슬라이드에 따르면 Qwen-MoE의 핵심 설정은 다음과 같습니다.
슬라이드에 따르면 Qwen-MoE의 핵심 설정은 다음과 같습니다.
- Base model: Qwen 1.8B
- Experts: 60 experts
- Shared experts: 4 experts
- Routing: top-k = 4
여기서 shared expert는 모든 토큰이 공통적으로 사용하는 expert에 가깝습니다.
반면 routed expert는 router가 token별로 선택하는 expert입니다.
Shared expert를 두는 이유는 모든 토큰에 필요한 일반적인 지식을 안정적으로 처리하기 위해서입니다.
모든 것을 router 선택에 맡기면 expert specialization은 가능하지만, 공통적인 language modeling 능력이나 일반 지식이 분산되어 불안정해질 수 있습니다.
Shared expert는 이런 공통 기반을 담당합니다.
반대로 routed expert들은 token이나 domain, linguistic pattern에 따라 더 specialized된 계산을 담당할 수 있습니다.
Qwen-MoE는 upcycling이 실제로 성공적으로 사용될 수 있음을 보여주는 사례로 언급됩니다.
Dense Qwen checkpoint에서 출발하여 MoE로 확장하고, 이후 추가 학습을 통해 sparse expert structure를 학습시키는 방식입니다.
정리하면 이 페이지의 핵심은 다음입니다.
-
Qwen-MoE는 dense Qwen 1.8B를 MoE로 확장한 사례다.
-
많은 routed expert와 일부 shared expert를 함께 사용한다.
-
top-k routing으로 token당 사용하는 expert 수를 제한한다.
-
upcycling이 단순 아이디어가 아니라 실제 대규모 모델 설계에 사용되었다.
Page 54 ~ Page 56. DeepSeek MoE 사례
54~56page는 DeepSeek의 MoE 사례를 보여줍니다. 자세한 내용은 생략하겠습니다.
Page 57. Bonus: What else do you need to make DeepSeek MoE v3?
이 페이지부터는 DeepSeek 계열의 또 다른 핵심 기술인 MLA, Multi-head Latent Attention을 설명합니다.
MLA의 목적은 attention에서 큰 비중을 차지하는 KV cache 비용을 줄이는 것입니다.
일반적인 multi-head attention에서는 각 token마다 query, key, value를 만듭니다.
Autoregressive decoding에서는 이전 token들의 key와 value를 계속 저장해야 합니다.
이 저장 공간을 KV cache라고 합니다.
문제는 context length가 길어질수록 KV cache가 커진다는 점입니다.
긴 context를 다루거나 batch size를 키우려면 KV cache 메모리가 inference 병목이 됩니다.
MLA의 핵심 아이디어는 key와 value를 직접 큰 차원으로 저장하지 않고, 더 작은 latent vector로 압축해서 저장하는 것입니다.
개념적으로는 다음과 같습니다.
c_t^{KV} = h_t W^{DKV}
여기서 $h_t$는 token $t$의 hidden state이고, $c_t^{KV}$는 압축된 latent representation입니다.
그다음 key와 value는 이 latent에서 다시 up-projection하여 만듭니다.
k_t = c_t^{KV} W^{UK}, \qquad v_t = c_t^{KV} W^{UV}
즉, cache에는 큰 key/value 전체를 저장하는 대신 더 작은 latent를 저장합니다.
필요할 때 latent에서 key/value를 복원하거나 attention 계산에 활용합니다.
이 구조는 low-rank projection처럼 볼 수 있습니다.
KV 정보를 작은 bottleneck representation으로 압축하고, attention 계산 시 다시 필요한 형태로 변환하는 방식입니다.
정리하면 MLA는 다음 문제를 해결하려는 기술입니다.
-
긴 context에서 KV cache 메모리가 너무 커진다.
-
MHA는 head별 K/V를 많이 저장해야 한다.
-
GQA/MQA는 KV cache를 줄이지만 표현력이 줄어들 수 있다.
-
MLA는 latent cache를 통해 메모리 절감과 표현력 사이의 절충을 노린다.
Page 58. What else do you need to make DeepSeek MoE v3?
이 페이지는 MLA의 장점과 RoPE와의 충돌 문제를 설명합니다.
MLA는 KV cache를 압축할 수 있지만, positional encoding, 특히 RoPE와 결합할 때 주의가 필요합니다.
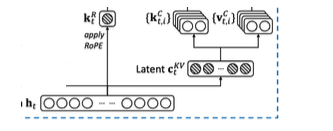
MLA의 이점은 명확합니다.
key와 value 전체를 cache하지 않고 latent representation을 cache하면 메모리를 크게 줄일 수 있습니다.
또한 token마다 저장해야 하는 activation 크기가 줄어들기 때문에 long-context inference에서 유리합니다.
하지만 문제가 있습니다.
RoPE는 query와 key에 위치 정보를 회전 변환 형태로 주입합니다.
일반적인 attention에서는 각 position의 key가 이미 RoPE가 적용된 상태로 cache됩니다.
그런데 MLA에서는 key를 직접 cache하지 않고 latent를 cache합니다.
이 경우 position-dependent한 RoPE를 언제, 어디에 적용할 것인지가 어려워집니다.
왜냐하면 latent cache는 여러 head와 key/value 정보를 압축한 representation입니다.
여기에 RoPE를 그대로 적용하면, 나중에 key로 복원했을 때 head별 positional structure가 제대로 유지되지 않을 수 있습니다.
DeepSeek 계열에서는 이를 해결하기 위해 key를 두 부분으로 나눕니다.
개념적으로는 다음과 같습니다.
key = compressed/latent part + RoPE-aware positional part
즉, 대부분의 KV 정보는 latent로 압축하지만, RoPE가 필요한 positional component는 별도로 유지합니다.
이렇게 하면 KV cache 절감 효과를 유지하면서도, RoPE 기반 위치 정보를 attention 계산에 반영할 수 있습니다.
정리하면 MLA는 단순한 KV 압축 기법이 아닙니다.
Attention의 표현력, cache 효율, positional encoding을 동시에 맞춰야 하는 구조적 설계입니다.
Page 59. What else do you need to make DeepSeek MoE v3? (MTP)
이 페이지는 DeepSeek에서 사용된 MTP, Multi-Token Prediction을 설명합니다.
MTP는 모델이 다음 token 하나만 예측하는 것이 아니라, 여러 future token을 함께 예측하도록 학습하는 방식입니다.
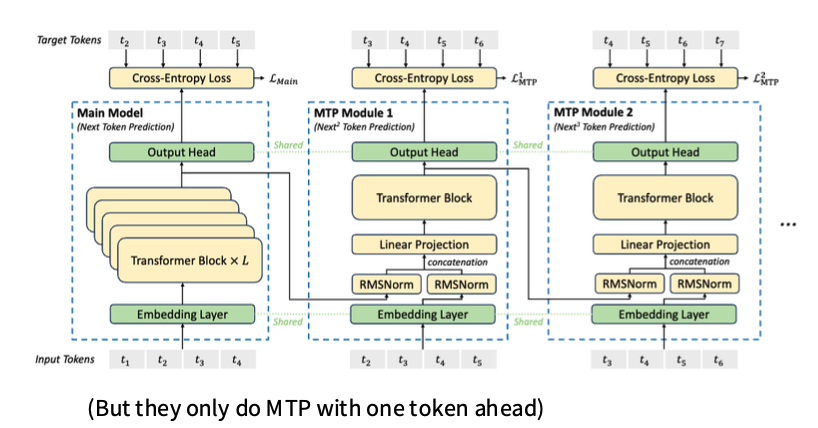
일반적인 autoregressive language model의 학습 목표는 다음 token prediction입니다.
즉, 현재까지의 prefix가 주어졌을 때 바로 다음 token $x_{t+1}$을 예측합니다.
MTP는 여기서 한 단계 더 나아갑니다.
현재 hidden state를 바탕으로 $x_{t+1}$뿐 아니라 $x_{t+2}$, $x_{t+3}$처럼 여러 step ahead token을 예측하게 합니다.
개념적으로는 다음과 같습니다.
기본 LM objective:
predict x_{t+1}
Multi-token prediction:
predict x_{t+1}, x_{t+2}, ..., x_{t+k}
이 방식은 모델이 더 먼 미래의 token까지 고려하도록 유도합니다.
단기적인 next-token pattern만 맞추는 것이 아니라, 이후 전개될 sequence 구조를 더 잘 학습할 수 있습니다.
DeepSeek에서는 MTP를 위해 작은 추가 module을 붙이는 방식이 사용됩니다.
슬라이드에서는 EAGLE과 유사하게, lightweight module이 future token prediction을 담당하는 구조가 언급됩니다.
다만 DeepSeek v3에서는 실제로 하나의 MTP module만 사용하여 한 token ahead를 추가로 예측하는 형태로 정리됩니다.
MTP의 장점은 두 가지로 볼 수 있습니다.
-
첫째, 학습 신호가 풍부해집니다.
각 position에서 바로 다음 token뿐 아니라 더 뒤의 token을 예측하므로, representation이 더 긴 범위의 정보를 담도록 압력을 받습니다.
-
둘째, inference 가속과 연결될 수 있습니다.
여러 token을 미리 예측하는 능력은 speculative decoding이나 draft model 방식과도 관련이 있습니다. 물론 MTP 자체가 곧바로 빠른 decoding을 보장하는 것은 아니지만, future token prediction 능력을 학습시키는 기반이 됩니다.
MoE Summary
마지막 페이지는 이번 강의의 전체 흐름을 요약합니다.
핵심 주제는 attention 대체 구조와 MoE입니다.
이번 강의의 첫 번째 큰 축은 attention 비용을 줄이는 방법이었습니다.
표준 self-attention은 sequence length $n$에 대해 $O(n^2)$ 비용을 갖습니다.
context length가 길어질수록 이 비용은 급격히 커집니다.
따라서 다양한 attention 대체 구조가 등장했습니다.
대표적인 방향은 다음과 같습니다.
-
sparse attention
-
sliding window attention
-
linear attention
-
state space model
-
hybrid architecture
-
KV cache compression
-
latent attention
이들은 모두 긴 context에서 attention의 계산량 또는 메모리 비용을 줄이기 위한 시도입니다.
두 번째 큰 축은 MoE입니다.
MoE는 모델의 전체 파라미터 수를 크게 늘리면서도, token당 active parameter 수는 제한하는 구조입니다.
각 token은 router에 의해 일부 expert만 사용합니다.
MoE의 장점은 다음과 같습니다.
-
더 큰 parameter capacity 확보
-
token당 계산량 제한
-
expert specialization 가능
-
expert parallelism을 통한 분산 학습 가능
하지만 MoE는 다음 문제를 동반합니다.
-
routing instability
-
load balancing 문제
-
token dropping
-
batch-level stochasticity
-
all-to-all communication 비용
-
fine-tuning 시 overfitting 가능성
-
system-level implementation complexity
마지막으로 DeepSeek 계열의 발전은 최근 LLM architecture가 단일 아이디어로 구성되지 않는다는 점을 보여줍니다.
DeepSeek은 MoE, MLA, MTP 같은 여러 구조적 개선을 결합합니다.
정리하면 이번 강의의 핵심 메시지는 다음입니다.
LLM scaling은 단순히 dense Transformer를 더 크게 만드는 방향만으로 진행되지 않는다. 긴 context를 위한 attention 효율화와, 큰 parameter capacity를 위한 sparse expert routing이 함께 중요해지고 있다.
References
https://github.com/stanford-cs336/lectures/blob/main/lecture_04.pdf
Comments