기준 자료: Stanford CS336 Lecture 02
Resource Accounting (Systems)공식 강의 흐름을 기준으로 작성했습니다. 이전에 다룬 한국어 강의 PDF의 핵심 포인트도 함께 반영해, 단순 번역이 아니라 왜 이런 계산을 하는지까지 자연스럽게 설명하는 형태로 정리했습니다.
공식 강의 링크: CS336 Lecture 02 trace 강의 소스: lecture_02.py
0. 이번 강의의 위치: 왜 Resource Accounting인가
Lecture 01에서는 언어모델의 전체 흐름과 토크나이제이션을 다뤘습니다. Lecture 02의 주제는 Resource Accounting, 즉 모델 학습과 추론에 필요한 자원을 계산하는 방법입니다.
여기서 말하는 자원은 크게 두 가지입니다.
-
Memory: GPU 메모리를 얼마나 쓰는가? 예를 들어 파라미터, gradient, optimizer state, activation이 얼마나 많은 메모리를 차지하는가?
-
Compute: 연산량이 얼마나 되는가? 예를 들어 forward/backward pass에서 FLOPs가 얼마나 발생하는가?
이 강의의 핵심 질문은 다음과 같습니다.
고정된 compute와 memory가 있을 때, 어떤 크기의 모델을 얼마나 오래 학습할 수 있는가?
LLM을 다룰 때는 단순히 “모델을 크게 만들면 좋다”가 아니라, 주어진 GPU 수, GPU 메모리, GPU 연산 성능, 학습 토큰 수, batch size, optimizer 종류, precision 등을 모두 고려해야 합니다. 따라서 이 강의는 모델 구조 자체보다, 모델을 실제로 학습시키기 위해 필요한 계산 감각을 기르는 데 목적이 있습니다.
공식 강의에서는 이 목표를 세 가지로 정리합니다.
-
PyTorch tensor 연산의 기본 동작을 이해한다.
-
memory와 compute를 직접 세는 습관을 만든다.
-
실제 LLM 학습에서 자원이 어디에 쓰이는지 직관을 얻는다.
초반에는 Stanford 수업 운영 공지로 Slack 가입, Modal 등록, AI policy guide, cluster guide 안내가 나오고, Marin의 1e23 FLOPs 규모 run이 예측과 맞았다는 예시가 등장합니다. 이 예시는 LLM 학습에서 FLOPs 단위의 resource accounting이 단순한 이론이 아니라, 실제 대규모 학습 run을 예측하고 관리하는 데 쓰인다는 맥락을 보여줍니다.

1. Motivating Question 1: 70B 모델을 15T 토큰으로 학습하면 얼마나 걸릴까?
첫 번째 질문은 다음과 같습니다.
70B parameter 모델을 15T tokens로, 1024개의 H100에서 학습하면 시간이 얼마나 걸릴까?
이 질문은 LLM 학습 비용을 가장 거칠게 추정하는 대표적인 napkin math입니다. 강의에서는 training FLOPs를 다음 근사식으로 둡니다.
\text{training FLOPs} \approx 6 \times N_{params} \times N_{tokens}
여기서 6이 나오는 이유는 뒤에서 더 자세히 설명하지만, 요약하면 다음과 같습니다.
-
forward pass: 약
2 x tokens x parametersFLOPs -
backward pass: 약
4 x tokens x parametersFLOPs -
전체 training step: 약
6 x tokens x parametersFLOPs
따라서 70B 모델을 15T 토큰으로 학습할 때 필요한 총 FLOPs는 다음과 같습니다.
6 \times 70 \times 10^9 \times 15 \times 10^{12}
= 6.3 \times 10^{24}\ \text{FLOPs}
H100의 peak 성능은 강의에서 1979e12 FLOP/s로 잡지만, sparsity를 사용하지 않는 상황을 고려해 절반으로 봅니다.
\text{H100 FLOP/s} = \frac{1979 \times 10^{12}}{2}
= 9.895 \times 10^{14}\ \text{FLOP/s}
잠깐!! Sparsity를 사용하지 않는 상황??
H100 peak 성능에서 sparsity가 왜 나오냐?
NVIDIA GPU 스펙을 보면 Tensor Core 성능을 말할 때 종종 with sparsity 조건이 붙습니다.
예를 들어 H100 BF16/FP16 Tensor Core 성능이 1979 TFLOP/s처럼 제시될 때, 이 값은 보통 sparsity acceleration을 활용했을 때의 peak일 수 있습니다.
강의에서:
H100 peak = 1979e12 FLOP/s
without sparsity ≈ 1979e12 / 2
라고 하는 이유는, sparsity를 쓰면 이론적으로 dense 연산 대비 약 2배의 처리량을 낼 수 있기 때문입니다.
즉, 강의에서는 실제 일반적인 dense LLM 학습 상황을 가정하므로, sparsity boost를 제외하기 위해 절반으로 잡은것이다.
일반적인 Transformer weight는 대부분 dense입니다.
W_q, W_k, W_v, W_o
MLP up_proj, gate_proj, down_proj
이런 큰 weight matrix들은 대부분 0이 아닙니다.
물론 pruning을 통해 일부 weight를 0으로 만들 수는 있지만, 다음 문제가 생깁니다.
- 정확도 손실 가능성
- weight를 0으로 만들면 모델 표현력이 줄어들 수 있음.
- 특정 sparse pattern을 맞춰야 함
- hardware가 좋아하는 2:4 pattern에 맞추려면 단순히 작은 weight를 아무거나 제거하는 것보다 제약이 큼.
- 학습/추론 시스템 복잡도 증가
- sparse kernel, sparse format, pruning-aware training 등이 필요함.
- 항상 실제 속도 향상으로 이어지지 않음
- sparse representation을 관리하는 overhead가 생길 수 있음.
그래서 CS336 강의의 resource accounting에서는 보수적으로 dense 연산 기준으로 계산하기 위해 H100 peak 성능을 절반으로 잡는것입니다.
다시 돌아가서,
실제 학습에서는 GPU peak 성능을 100% 쓰지 못합니다. 강의에서는 MFU(Model FLOPs Utilization) 를 0.5로 가정합니다. 즉, H100이 이론적으로 낼 수 있는 성능의 절반 정도를 실제 유효 학습 연산에 쓴다고 보는 것입니다.
1024개 H100을 하루 동안 사용할 때 처리 가능한 FLOPs는 다음과 같습니다.
9.895 \times 10^{14}
\times 0.5
\times 1024
\times 3600
\times 24
\approx 4.38 \times 10^{22}\ \text{FLOPs/day}
따라서 전체 학습 시간은 다음처럼 계산됩니다.
\frac{6.3 \times 10^{24}}{4.38 \times 10^{22}}
\approx 144\ \text{days}
즉, 아주 거칠게 보면 70B 모델을 15T 토큰으로 1024개 H100에서 학습하는 데 약 144일이 걸립니다. 실제로는 data pipeline, checkpoint 저장, 통신 overhead, 장애 복구, validation, warmup, optimizer 설정, sequence length 등 여러 요소가 추가되므로 이 값은 정확한 일정표라기보다는 규모를 파악하기 위한 기준점입니다.
중요한 점은 이 계산이 매우 단순하지만, LLM 학습 규모를 판단할 때 강력한 1차 추정이 된다는 것입니다.
2. Motivating Question 2: 8개 H100에서 AdamW로 학습 가능한 최대 모델 크기는?
두 번째 질문은 memory 관점입니다.
8개의 H100에서 AdamW를 사용해 학습할 때, 가장 큰 모델은 몇 파라미터 정도까지 가능할까?
H100 한 장의 GPU 메모리를 80GB로 두면, 8개 H100의 총 메모리는 다음과 같습니다.
80 \times 10^9 \times 8 = 640 \times 10^9\ \text{bytes}
공식 CS336 강의에서는 mixed precision 학습을 전제로 대략 다음처럼 계산합니다.
-
parameters: 2 bytes/parameter, 예: bf16
-
gradients: 2 bytes/parameter, 예: bf16
-
optimizer states: 4 + 4 bytes/parameter, 예: Adam 계열의 fp32 first moment와 second moment
따라서 parameter 하나당 필요한 메모리는 다음과 같습니다.
2 + 2 + (4 + 4) = 12\ \text{bytes/parameter}
그러면 최대 parameter 수는 다음처럼 나옵니다.
\frac{640 \times 10^9}{12}
\approx 53.3 \times 10^9
즉, activations를 제외하면 이론적으로 약 53B parameter 정도가 상한입니다.
다만 이전 한국어 강의 PDF에서는 더 naive한 fp32 기준으로 다음과 같은 계산도 등장합니다.
4 + 4 + (4 + 4) = 16\ \text{bytes/parameter}
이 경우에는 다음과 같습니다.
\frac{640 \times 10^9}{16}
= 40 \times 10^9
즉, fp32로 parameters와 gradients까지 잡으면 약 40B parameter가 됩니다.
둘 중 무엇이 맞는가보다는, 어떤 precision 가정을 했는지가 중요합니다. 실제 LLM 학습에서는 mixed precision을 사용하므로 parameters와 activations는 bf16/fp16 계열로 두고, optimizer state는 안정성을 위해 fp32로 유지하는 경우가 많습니다. 하지만 이 계산은 activations를 제외한 upper bound입니다. 실제 학습에서는 batch size와 sequence length에 따라 activation memory가 크게 추가되므로, 이보다 더 작은 모델만 안정적으로 학습 가능할 수 있습니다.
3. Tensor는 모든 것의 기본 단위다
Resource accounting을 하려면 먼저 tensor가 무엇을 담는지 알아야 합니다. 강의에서는 tensor가 다음을 저장하는 기본 자료구조라고 설명합니다.
-
data
-
parameters
-
gradients
-
optimizer state
-
activations
즉, LLM 학습 중 GPU 메모리를 차지하는 거의 모든 것은 tensor입니다.
예를 들어 PyTorch에서 다음은 rank 1 tensor, 즉 vector입니다.
x = torch.zeros(4)
다음은 rank 2 tensor, 즉 matrix입니다.
x = torch.zeros(4, 8)
다음은 rank 3 tensor입니다.
x = torch.zeros(4, 8, 2)
Transformer에서는 rank 4 tensor도 매우 자주 등장합니다. 예를 들어 attention에서 다음과 같은 형태를 생각할 수 있습니다.
B = 32 # batch size
S = 16 # sequence length
H = 16 # number of heads
D = 64 # hidden dimension per head
x = torch.zeros(B, S, H, D)
이 tensor의 shape은 [batch, sequence, heads, head_dim]입니다. LLM 구현에서 shape을 정확히 추적하는 것은 매우 중요합니다. 왜냐하면 memory는 tensor의 원소 개수에 dtype별 byte 수를 곱해서 결정되고, compute는 tensor shape에 따라 matmul의 FLOPs가 결정되기 때문입니다.
강의에서는 실제 모델 parameter tensor의 예시로 DeepSeek V3.2 논문과 DeepSeek V3.2 Hugging Face safetensors index를 바로 보여줍니다. 여기서 중요한 점은 모델이 추상적인 ‘70B’ 같은 숫자로만 존재하는 것이 아니라, 실제로는 수많은 tensor 파일과 각 tensor의 shape, dtype, shard 정보로 구성된다는 것입니다.
4. Tensor memory는 원소 수와 dtype이 결정한다
tensor의 memory 사용량은 매우 단순하게 계산할 수 있습니다.
\text{memory bytes} = \text{number of elements} \times \text{bytes per element}
예를 들어 다음 tensor는 4 x 8 = 32개의 원소를 가집니다.
x = torch.zeros(4, 8)
PyTorch의 기본 floating point dtype은 보통 float32입니다. float32는 원소 하나가 4 bytes이므로, 이 tensor의 memory는 다음과 같습니다.
4 \times 8 \times 4 = 128\ \text{bytes}
이 원리는 작은 tensor뿐 아니라 GPT-3의 feedforward layer 같은 큰 matrix에도 그대로 적용됩니다. 강의에서는 GPT-3의 feedforward layer에 있는 matrix 하나를 예로 들어, 12288 x 4와 12288 차원의 큰 matrix 하나가 약 2.3GB까지 갈 수 있음을 보여줍니다.
즉, LLM 학습에서 memory accounting은 어려운 마법이 아니라 다음 질문을 반복하는 것입니다.
이 tensor는 원소가 몇 개이고, 원소 하나는 몇 byte인가?
5. Floating point dtype: fp32, fp16, bf16, fp8, fp4
LLM 학습에서는 숫자를 어떤 precision으로 저장하느냐가 memory와 stability를 크게 좌우합니다.
5.1 fp32
fp32, 또는 float32, single precision은 전통적인 scientific computing에서 기본처럼 쓰이는 dtype입니다. 원소 하나가 32 bits, 즉 4 bytes입니다.

fp32는 비교적 안정적이지만, LLM 학습에서는 너무 많은 메모리를 사용합니다. 예를 들어 parameter가 70B이면 parameter만 fp32로 저장해도 다음과 같습니다.
70 \times 10^9 \times 4 = 280\ \text{GB}
parameter만 280GB이므로, gradients, optimizer states, activations까지 고려하면 단일 GPU는 물론이고 여러 GPU를 써도 부담이 큽니다.
5.2 fp16
fp16, 또는 float16, half precision은 원소 하나가 16 bits, 즉 2 bytes입니다. fp32 대비 memory를 절반으로 줄일 수 있습니다.
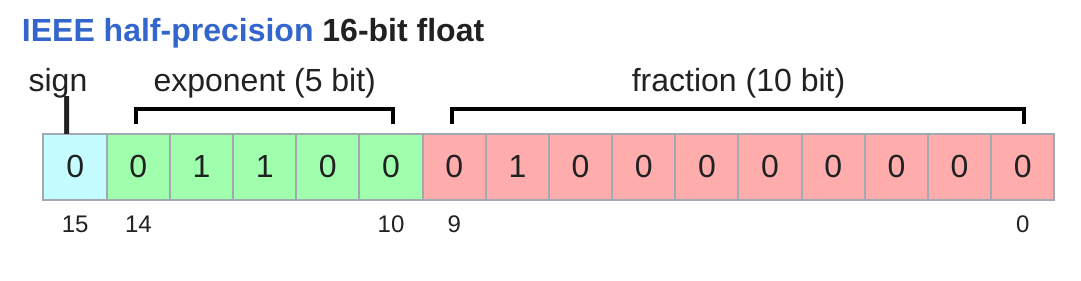
하지만 fp16의 문제는 dynamic range가 좁다는 점입니다. dynamic range는 표현할 수 있는 숫자의 범위입니다. 딥러닝 학습에서는 gradient가 아주 작아질 수도 있고, 일부 activation이나 loss scaling 과정에서 큰 값이 나올 수도 있습니다. fp16은 특히 작은 값을 표현하는 능력이 약해서 underflow가 발생할 수 있습니다.
강의 예시는 다음과 같습니다.
x = torch.tensor([1e-8], dtype=torch.float16)
이 값은 fp16에서 0으로 underflow될 수 있습니다. 만약 gradient가 이런 식으로 사라지면 학습이 불안정해질 수 있습니다.
5.3 bf16
bf16, 즉 bfloat16은 Google Brain이 개발한 16-bit floating point format입니다. 원소 하나는 fp16과 같이 2 bytes이지만, exponent에 더 많은 bit를 할당해서 fp32와 유사한 dynamic range를 가집니다.
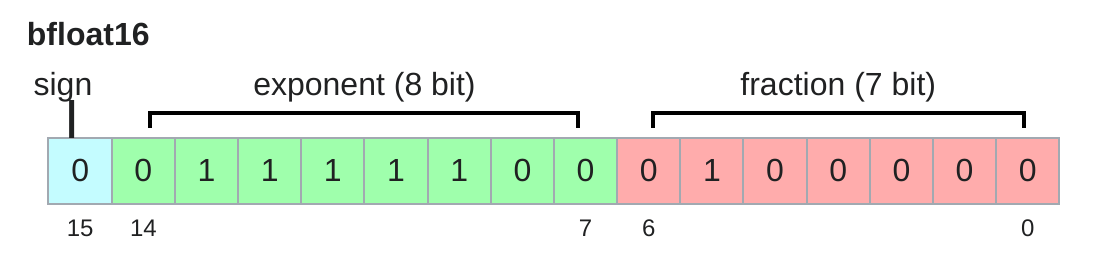
bf16의 장점은 다음과 같습니다.
-
memory는 fp16처럼 작다.
-
dynamic range는 fp32에 가깝다.
-
deep learning에서는 mantissa resolution이 조금 낮아도 학습이 잘 되는 경우가 많다.
즉, bf16은 LLM 학습에서 매우 실용적인 dtype입니다. fp16보다 underflow/overflow에 덜 취약하고, fp32보다 memory와 compute 측면에서 효율적입니다.
5.4 mixed precision training
fp32만 쓰면 안정적이지만 memory가 너무 크고, fp16/bf16만 쓰면 일부 연산에서 instability가 생길 수 있습니다. 그래서 사용하는 방법이 mixed precision training입니다.
강의에서는 mixed precision을 다음처럼 설명합니다.
-
parameters, activations, gradients는 bf16을 사용한다.
-
optimizer states는 fp32를 사용한다.
optimizer state를 fp32로 두는 이유는 optimizer가 여러 step에 걸쳐 gradient의 평균이나 제곱 평균을 누적하기 때문입니다. 이런 누적값은 작은 수치 오차가 쌓이면 학습 안정성에 영향을 줄 수 있으므로, fp32로 유지하는 것이 일반적입니다.
PyTorch에서는 AMP(Automatic Mixed Precision)를 통해 안전한 연산은 bf16/fp16으로 수행하고, 위험한 연산은 더 높은 precision으로 유지할 수 있습니다.
with torch.amp.autocast("cuda", dtype=torch.bfloat16):
x = torch.zeros(4, 8)
여기서 중요한 감각은 “dtype은 memory만 줄이는 옵션이 아니라, 학습 안정성과 hardware throughput까지 함께 바꾸는 선택”이라는 점입니다.
5.5 fp8
강의에서는 fp8도 소개합니다. fp8은 machine learning workload를 위해 표준화되었고, 강의는 NVIDIA의 FP8 primer를 연결한 뒤 H100이 두 가지 FP8 format을 지원한다고 설명합니다.
-
E4M3: range
[-448, 448] -
E5M2: range
[-57344, 57344]

강의의 추가 FP8 reference처럼, fp8은 memory와 bandwidth를 더 줄일 수 있지만, precision이 낮기 때문에 scale 관리, kernel 지원, hardware 지원이 중요합니다.
5.6 fp4 / NVFP4
강의에서는 NVIDIA가 2025년에 공개한 NVFP4도 언급하고, Nemotron 3 Super가 NVFP4를 활용했다는 예시를 붙입니다. 여기서 핵심은 “숫자 하나를 4 bits로 저장한다”가 아니라, 4-bit 값만으로는 너무 거칠기 때문에 scale factor와 함께 써야 한다는 점입니다.
FP4는 이름 그대로 원소 하나를 4 bits로 표현하려는 형식입니다. NVIDIA Blackwell 계열에서 이야기되는 FP4는 보통 E2M1 구조로 설명됩니다.
FP4 E2M1
sign : 1 bit
exponent : 2 bits
mantissa : 1 bit
4 bits로 만들 수 있는 bit pattern은 최대 16개뿐입니다. 그래서 FP4는 fp32나 bf16처럼 연속적인 실수를 촘촘하게 표현하지 못합니다. 강의에서 제시한 FP4 값의 예시는 다음과 같습니다.
-6, -4, -3, -2, -1.5, -1.0, -0.5, 0.0,
0.5, 1.0, 1.5, 2, 3, 4, 6
이 목록을 보면 FP4의 한계가 바로 보입니다. 예를 들어 원래 값이 1.2라면 FP4 후보에는 1.2가 없습니다. 그래서 1.0이나 1.5처럼 가까운 값으로 반올림해야 합니다. 원래 값이 5.0이라면 후보가 4 또는 6이므로 둘 중 하나로 근사됩니다.
원래 값 1.2 -> FP4 후보 1.0 또는 1.5
원래 값 5.0 -> FP4 후보 4 또는 6
원래 값 0.2 -> FP4 후보 0.0 또는 0.5
즉, FP4는 memory를 크게 줄이는 대신 숫자를 매우 거친 격자에 맞춰 저장합니다. 이때 생기는 오차를 quantization error라고 볼 수 있습니다.
FP4만으로는 큰 값과 작은 값을 동시에 잘 표현하기 어렵다
FP4 값 자체만 보면 표현 범위가 대략 -6에서 6 근처입니다. 그러면 12, 30, 0.03 같은 값은 FP4 값만으로는 잘 표현하기 어렵습니다. 그래서 FP4는 보통 scale factor와 함께 사용합니다.
핵심 식은 다음과 같습니다.
실제 값 ≈ FP4로 저장한 값 × scale
기호로 쓰면 다음과 같습니다.
x ≈ x_q × s
여기서 x는 원래 값, x_q는 FP4로 양자화된 값, s는 scale factor입니다.
예를 들어 scale = 2라고 하면, FP4 값 6은 실제로는 다음 값을 의미할 수 있습니다.
FP4 저장 값: 6
scale: 2
복원 값: 6 × 2 = 12
즉, FP4 자체는 6까지의 거친 값만 갖지만, scale을 곱하면 더 큰 dynamic range를 표현할 수 있습니다.
block scaling 예시
다음 값들을 FP4로 저장한다고 해보겠습니다.
원래 값:
[12, -6, 3, 1.2]
이 block에서 가장 큰 절댓값은 12입니다. FP4의 최대 후보를 6으로 보면, scale을 다음처럼 잡을 수 있습니다.
scale = 12 / 6 = 2
이제 원래 값을 scale로 나눕니다.
[12, -6, 3, 1.2] / 2
= [6, -3, 1.5, 0.6]
이 값들을 FP4 후보 중 가까운 값으로 반올림합니다.
[6, -3, 1.5, 0.6]
-> [6, -3, 1.5, 0.5]
저장되는 것은 원래 fp32 값이 아니라 다음 두 가지입니다.
FP4 값:
[6, -3, 1.5, 0.5]
scale:
2
나중에 다시 사용할 때는 scale을 곱해서 복원합니다.
[6, -3, 1.5, 0.5] × 2
= [12, -6, 3, 1]
원래 값은 [12, -6, 3, 1.2]였고, 복원 값은 [12, -6, 3, 1]입니다. 1.2가 1.0으로 바뀐 부분이 quantization error입니다. 하지만 전체적으로 보면 32-bit나 16-bit로 저장하던 값을 훨씬 적은 bit로 저장할 수 있습니다.
outlier가 있을 때 왜 block scaling이 중요한가
큰 tensor에는 큰 값과 작은 값이 섞여 있습니다. 예를 들어 다음 block을 보겠습니다.
[1, 1, 1, 1, 1, 1, 1, 60]
가장 큰 값은 60입니다. FP4 최대 후보를 6으로 보면 scale은 다음처럼 됩니다.
scale = 60 / 6 = 10
그러면 작은 값 1은 scale로 나누었을 때 0.1이 됩니다.
1 / 10 = 0.1
그런데 FP4 후보에는 0.1이 없습니다. 가장 가까운 값이 0.0이 되면, 복원 후에는 다음처럼 됩니다.
0.0 × 10 = 0
즉, 원래는 중요한 작은 값이었는데 outlier 60 때문에 0처럼 사라질 수 있습니다.
원래:
[1, 1, 1, 1, 1, 1, 1, 60]
복원 예시:
[0, 0, 0, 0, 0, 0, 0, 60]
이것이 low-bit quantization에서 outlier가 위험한 이유입니다. 하나의 큰 값 때문에 같은 block 안의 작은 값들이 망가질 수 있습니다.
그래서 block을 작게 나누면 유리합니다. 예를 들어 같은 값을 두 block으로 나누면 다음과 같습니다.
Block A:
[1, 1, 1, 1]
Block B:
[1, 1, 1, 60]
Block A에는 큰 outlier가 없으므로 scale을 작게 잡을 수 있고, 1들을 더 잘 보존할 수 있습니다. Block B만 outlier의 영향을 받습니다. 즉, block size가 작을수록 outlier가 망치는 범위가 줄어듭니다.
NVFP4는 “FP4 값 + 16개 단위 FP8 scale + tensor 단위 FP32 scale” 구조에 가깝다
NVFP4는 단순히 모든 값을 FP4 하나로 저장하는 방식이 아닙니다. NVIDIA 설명에 따르면 NVFP4는 다음과 같은 구조를 갖습니다.
NVFP4
각 원소 값:
FP4 E2M1
micro-block scale:
16개 값마다 1개의 FP8 E4M3 scale
tensor-level scale:
tensor 단위 FP32 scale
즉, 16개 값이 하나의 작은 block을 이루고, 그 16개 값은 하나의 FP8 scale을 공유합니다. 복원할 때는 대략 다음처럼 해석할 수 있습니다.
x ≈ x_q × s
여기서 x_q는 FP4 값이고, s는 해당 16-value micro-block의 scale입니다. 여기에 tensor-level FP32 scale이 한 번 더 들어가 전체 tensor의 범위를 조정합니다.
이 구조가 중요한 이유는 FP4의 값 후보가 너무 적기 때문입니다. FP4 자체는 거친 눈금자에 가깝습니다. 하지만 block마다 scale을 다르게 잡으면, 같은 FP4 후보라도 실제로 표현하는 값의 범위가 달라집니다.
예를 들어 FP4 후보가 다음과 같다고 하겠습니다.
0, 0.5, 1, 1.5, 2, 3, 4, 6
scale이 10이면 실제 표현 값은 다음처럼 커집니다.
0, 5, 10, 15, 20, 30, 40, 60
scale이 0.1이면 실제 표현 값은 다음처럼 작아집니다.
0, 0.05, 0.1, 0.15, 0.2, 0.3, 0.4, 0.6
즉, FP4 값 후보는 적지만, scale을 잘 잡으면 다양한 범위의 숫자를 표현할 수 있습니다.
MXFP4와 NVFP4의 차이
NVIDIA 자료에서는 Blackwell 계열의 4-bit floating-point 형식으로 FP4, MXFP4, NVFP4를 비교합니다. 강의 맥락에서 중요한 차이는 scale의 block size와 scale precision입니다.
| 구분 | MXFP4 | NVFP4 |
|---|---|---|
| 값 자체 | FP4 E2M1 | FP4 E2M1 |
| scale 공유 단위 | 32 values | 16 values |
| scale 형식 | power-of-two scale | FP8 E4M3 scale |
| scale 정밀도 | 더 거칠다 | 더 세밀하다 |
| 장점 | 단순하고 빠르다 | quantization error를 더 줄이기 쉽다 |
| 핵심 직관 | 큰 block에 거친 scale | 작은 block에 더 세밀한 scale |
MXFP4는 32개 값이 하나의 scale을 공유합니다. 반면 NVFP4는 16개 값마다 scale을 둡니다. 따라서 NVFP4는 local dynamic range에 더 잘 맞출 수 있습니다. 또한 NVFP4의 scale은 FP8 E4M3이므로, power-of-two scale보다 더 세밀한 fractional scale을 고를 수 있습니다.
예를 들어 어떤 block에 가장 적절한 scale이 3.2라고 해보겠습니다.
power-of-two scale만 가능:
1, 2, 4, 8, ...
3.2에 가까운 값:
4
scale을 4로 잡으면 실제 값 분포보다 scale이 커질 수 있고, 작은 값 표현이 나빠질 수 있습니다. 반면 E4M3 scale은 3.2 근처의 fractional scale을 더 잘 표현할 수 있으므로 전체 block의 quantization error를 줄이는 데 유리합니다.
memory 관점에서 보는 NVFP4
fp16은 원소 하나에 16 bits를 씁니다.
fp16: 16 bits / value
FP4는 원소 하나가 4 bits입니다.
FP4: 4 bits / value
단순히 값만 보면 4배 작아집니다.
16 bits / 4 bits = 4
하지만 NVFP4는 scale도 저장해야 합니다. 16개 값마다 FP8 scale 하나를 저장한다고 보면 scale overhead는 다음과 같습니다.
FP8 scale overhead:
8 bits / 16 values = 0.5 bits / value
따라서 대략적인 저장 비용은 다음과 같습니다.
NVFP4 approximate storage:
4 bits / value + 0.5 bits / value + tensor-level FP32 scale overhead
≈ 4.5 bits / value + small overhead
그래도 fp16의 16 bits에 비하면 훨씬 작습니다. 이 차이는 특히 inference에서 중요합니다. LLM decoding은 model weight와 KV cache를 계속 읽는 memory-bound 성격이 강하기 때문에, weight나 activation을 더 작은 dtype으로 저장하면 memory bandwidth 압박을 줄이고 throughput을 높일 수 있습니다.
이 강의에서 FP4/NVFP4를 이해해야 하는 이유
Resource accounting 관점에서 FP4/NVFP4는 단순한 dtype 소개가 아닙니다. dtype은 다음 세 가지를 동시에 바꿉니다.
-
memory footprint
-
memory bandwidth pressure
-
numerical stability and accuracy
fp32는 안정적이지만 너무 큽니다. bf16은 학습 안정성과 효율 사이의 좋은 절충안입니다. fp8과 fp4는 더 공격적으로 memory와 bandwidth를 줄이지만, scale factor와 hardware/kernel 지원이 없으면 정확도가 크게 깨질 수 있습니다.
따라서 FP4/NVFP4를 볼 때는 “4 bits라서 4배 절약된다”에서 끝내면 안 됩니다. 실제 핵심은 다음입니다.
low-bit value + scale design + hardware support + kernel implementation
한 줄로 정리하면, FP4는 4-bit짜리 매우 거친 floating-point 표현이고, NVFP4는 이 FP4 값을 16개 단위 FP8 scale과 tensor-level FP32 scale로 보정해서 memory는 크게 줄이면서 quantization error를 줄이려는 NVIDIA Blackwell의 저정밀 포맷입니다.
6. Tensor를 GPU에 올린다는 것
PyTorch tensor는 기본적으로 CPU memory에 생성됩니다.
x = torch.zeros(32, 32)
이 상태에서 x.device는 cpu입니다. GPU의 대규모 병렬성을 사용하려면 tensor를 GPU memory로 옮겨야 합니다.
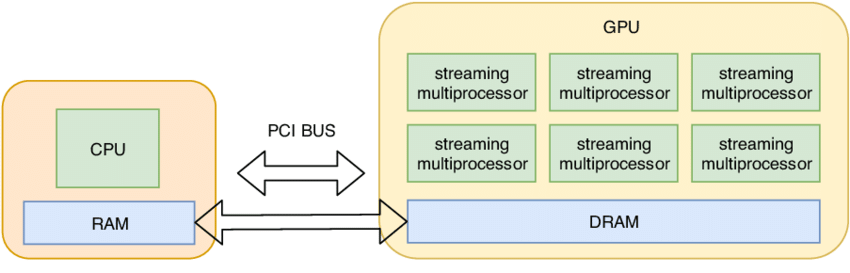
예를 들어 다음처럼 할 수 있습니다.
device = "cuda:0"
x = x.to(device)
또는 처음부터 GPU에 생성할 수도 있습니다.
x = torch.zeros(32, 32, device="cuda:0")
이 부분이 중요한 이유는 compute만 빠르다고 전체가 빨라지는 것이 아니기 때문입니다. GPU 연산은 빠르지만, CPU memory와 GPU memory 사이의 이동이나 GPU HBM에서 accelerator로 데이터를 읽고 쓰는 과정도 시간이 걸립니다. 뒤에서 나오는 memory-bound, compute-bound 개념이 바로 이 문제와 연결됩니다.
7. Einops: tensor dimension을 이름으로 관리하기
Transformer 구현에서는 tensor shape이 복잡합니다. batch, sequence, head, hidden dimension이 계속 섞이고, transpose나 reshape을 자주 사용합니다. 이때 단순히 -1, -2 같은 index로 dimension을 조작하면 실수하기 쉽습니다.
강의에서는 이를 보여주기 위해 다음 PyTorch 코드를 예로 듭니다.
x = torch.ones(2, 2, 3) # batch seq hidden
y = torch.ones(2, 2, 3) # batch seq hidden
z = x @ y.transpose(-2, -1) # batch seq seq
이 코드는 작동하지만, -2, -1이 정확히 어떤 dimension인지 매번 머릿속으로 추적해야 합니다. 모델이 커지고 tensor rank가 커질수록 이런 방식은 버그를 만들기 쉽습니다.
그래서 강의에서는 dimension에 이름을 붙여 tensor를 다루는 einops를 소개합니다.
7.1 einsum
einsum은 dimension 이름을 명시해서 matrix multiplication을 표현하는 방식입니다.
기존 방식은 다음과 같습니다.
x = torch.ones(3, 4) # seq1 hidden
y = torch.ones(4, 3) # hidden seq2
z = x @ y # seq1 seq2
einops 방식은 다음처럼 쓸 수 있습니다.
z = einsum(x, y, "seq1 hidden, hidden seq2 -> seq1 seq2")
이 표현은 어떤 dimension이 곱해지고, 어떤 dimension이 결과로 남는지 명시적으로 보여줍니다. hidden은 입력 양쪽에 있지만 output에 없으므로 sum over되는 dimension입니다.
batch가 있는 attention score 계산도 다음처럼 자연스럽게 쓸 수 있습니다.
z = einsum(
x, y,
"batch seq1 hidden, batch seq2 hidden -> batch seq1 seq2"
)
또는 broadcasting을 위해 ...를 사용할 수도 있습니다.
z = einsum(x, y, "... seq1 hidden, ... seq2 hidden -> ... seq1 seq2")
7.2 reduce
reduce는 특정 dimension을 sum, mean, max, min 등으로 줄일 때 사용합니다.
x = torch.ones(2, 3, 4) # batch seq hidden
기존 방식은 다음과 같습니다.
y = x.sum(dim=-1)
einops 방식은 다음과 같습니다.
y = reduce(x, "... hidden -> ...", "sum")
여기서는 hidden dimension을 sum으로 줄이고, 나머지 dimension은 그대로 둡니다.
7.3 rearrange
rearrange는 tensor의 축 순서를 바꾸거나, 여러 축을 하나로 합치거나, 하나의 축을 여러 축으로 나눌 때 사용합니다. PyTorch의 reshape, view, permute, transpose를 조합해서 할 수 있는 일을 하나의 패턴 문자열로 명시한다고 보면 됩니다.
핵심 문법은 다음 형태입니다.
rearrange(x, "입력 축 패턴 -> 출력 축 패턴", 축_크기_힌트)
왼쪽은 현재 tensor를 어떻게 해석할지, 오른쪽은 그 tensor를 어떤 축 구조로 다시 배치할지를 의미합니다. 중요한 점은 rearrange가 단순히 모양만 바꾸는 함수가 아니라, shape의 의미를 코드에 직접 기록하는 방식이라는 것입니다. 그래서 resource accounting을 할 때도 이 축이 batch인지, 이 축이 sequence인지, 이 축이 head인지, 이 축이 head dimension인지를 훨씬 명확하게 추적할 수 있습니다.
가장 단순한 예시는 축 순서를 바꾸는 것입니다.
from einops import rearrange
import torch
x = torch.randn(2, 3, 4) # batch seq hidden
# PyTorch 방식
y = x.permute(0, 2, 1) # batch hidden seq
# einops 방식
y = rearrange(x, "batch seq hidden -> batch hidden seq")
두 코드는 같은 일을 하지만, einops 방식은 0, 2, 1 같은 index가 아니라 batch, seq, hidden이라는 이름으로 축의 의미를 보여줍니다. Transformer 코드에서는 tensor rank가 커질수록 -1, -2, 1, 2 같은 index 기반 조작이 매우 헷갈리기 때문에, 이런 명시성이 중요합니다.
rearrange의 두 번째 핵심 기능은 flatten, 즉 여러 축을 하나로 합치는 것입니다.
x = torch.randn(2, 3, 4) # batch seq hidden
# batch와 seq를 하나의 token 축으로 합침
y = rearrange(x, "batch seq hidden -> (batch seq) hidden")
print(y.shape) # torch.Size([6, 4])
여기서 (batch seq)처럼 괄호로 묶으면 두 축을 하나의 축으로 합칩니다. 기존 tensor는 2 x 3 x 4였고, batch seq가 합쳐져 6 x 4가 됩니다. 학습 코드에서 모든 token을 한 번에 linear layer에 넣거나 loss를 계산할 때 이런 형태가 자주 나옵니다.
반대로 하나의 축을 여러 축으로 나누는 것도 가능합니다. 이때는 나눌 축의 크기를 알 수 있도록 일부 축 크기를 인자로 넘겨야 합니다.
x = torch.randn(6, 4) # tokens hidden
# tokens = batch * seq 라고 해석하고 다시 분리
x = rearrange(x, "(batch seq) hidden -> batch seq hidden", batch=2, seq=3)
print(x.shape) # torch.Size([2, 3, 4])
여기서는 tokens=6인 축을 (batch seq)로 해석합니다. batch=2, seq=3을 주었기 때문에 einops는 6 = 2 * 3으로 나눌 수 있음을 알고, 결과 shape을 [2, 3, 4]로 복원합니다.
강의에서 특히 중요한 예시는 multi-head attention입니다. Transformer에서는 hidden dimension이 보통 num_heads * head_dim으로 구성됩니다. 예를 들어 hidden size가 8이고 head 수가 2라면, 각 head의 dimension은 4입니다.
x = torch.ones(3, 8) # seq total_hidden
여기서 8은 사실 다음처럼 해석할 수 있습니다.
8 = heads * hidden1 = 2 * 4
따라서 flatten되어 있던 hidden dimension을 head dimension으로 다시 나누려면 다음처럼 씁니다.
x = rearrange(x, "seq (heads hidden1) -> seq heads hidden1", heads=2)
print(x.shape) # torch.Size([3, 2, 4])
패턴을 천천히 읽으면 다음과 같습니다.
입력: seq (heads hidden1)
seq 축은 그대로 두고,
마지막 축 total_hidden을 heads와 hidden1의 곱으로 해석한다.
출력: seq heads hidden1
쪼갠 heads와 hidden1을 별도 축으로 드러낸다.
이렇게 축을 분리하면 head별로 독립적인 연산을 표현하기 쉬워집니다. 예를 들어 각 head의 hidden dimension에 대해 같은 linear transformation을 적용한다고 하면 다음처럼 쓸 수 있습니다.
w = torch.randn(4, 5) # hidden1 hidden2
x = einsum(
x, w,
"seq heads hidden1, hidden1 hidden2 -> seq heads hidden2"
)
print(x.shape) # torch.Size([3, 2, 5])
이제 각 head는 hidden1=4에서 hidden2=5로 변환되었습니다. 마지막으로 head 축과 hidden 축을 다시 합치면 일반적인 [seq, total_hidden] 형태로 돌아갑니다.
x = rearrange(x, "seq heads hidden2 -> seq (heads hidden2)")
print(x.shape) # torch.Size([3, 10])
이 과정을 전체적으로 보면 다음과 같습니다.
[seq, total_hidden]
= [3, 8]
rearrange로 head 분리
→ [seq, heads, hidden1]
= [3, 2, 4]
head별 transformation
→ [seq, heads, hidden2]
= [3, 2, 5]
rearrange로 다시 합치기
→ [seq, heads * hidden2]
= [3, 10]
실제 Transformer 구현에서는 batch 축까지 포함되므로 더 자주 다음 형태가 등장합니다.
x = torch.randn(2, 3, 8) # batch seq total_hidden
x = rearrange(
x,
"batch seq (heads head_dim) -> batch heads seq head_dim",
heads=2,
)
print(x.shape) # torch.Size([2, 2, 3, 4])
여기서 출력 순서를 batch heads seq head_dim으로 바꾸는 이유는 attention score를 계산할 때 head별로 sequence 간 dot product를 만들기 좋기 때문입니다. 예를 들어 query와 key가 다음 shape을 가진다고 합시다.
q = torch.randn(2, 2, 3, 4) # batch heads seq_q head_dim
k = torch.randn(2, 2, 5, 4) # batch heads seq_k head_dim
attention score는 각 batch, 각 head에 대해 query token과 key token의 dot product입니다.
scores = einsum(
q, k,
"batch heads seq_q head_dim, batch heads seq_k head_dim -> batch heads seq_q seq_k"
)
print(scores.shape) # torch.Size([2, 2, 3, 5])
즉, rearrange로 hidden 축을 heads와 head_dim으로 쪼개두면, attention의 의미가 그대로 코드에 드러납니다.
batch: 몇 번째 sample인가
heads: 몇 번째 attention head인가
seq_q: query token 위치
seq_k: key token 위치
head_dim: dot product를 수행하는 feature dimension
또 하나 자주 쓰는 문법은 ...입니다. ...는 앞쪽에 어떤 축이 오든 그대로 유지하겠다는 뜻입니다. 강의 예시의 다음 코드는 seq만 있을 때도, batch seq가 있을 때도, 더 많은 prefix 축이 있을 때도 사용할 수 있습니다.
x = rearrange(x, "... (heads hidden1) -> ... heads hidden1", heads=2)
예를 들어 입력이 [seq, total_hidden]이면 결과는 [seq, heads, hidden1]이 되고, 입력이 [batch, seq, total_hidden]이면 결과는 [batch, seq, heads, hidden1]이 됩니다. 즉, ...는 공통 패턴을 재사용하게 해주는 문법입니다.
다만 rearrange를 사용할 때 주의할 점도 있습니다. 축을 나눌 때는 원래 축 크기가 새 축들의 곱과 정확히 맞아야 합니다.
x = torch.randn(3, 10) # seq total_hidden
# heads=3이면 10을 3 * hidden1로 나눌 수 없으므로 에러가 납니다.
x = rearrange(x, "seq (heads hidden1) -> seq heads hidden1", heads=3)
또한 rearrange는 가능한 경우 view/transpose처럼 저렴하게 동작할 수 있지만, 메모리 layout이 맞지 않으면 내부적으로 contiguous copy가 필요할 수 있습니다. 따라서 resource accounting 관점에서는 shape 변화 자체뿐 아니라, 실제 구현에서 copy가 발생하는지 여부도 성능에 영향을 줄 수 있습니다. 다만 강의의 핵심은 이 저수준 구현 세부사항보다, 복잡한 tensor shape을 명시적으로 추적하는 습관을 갖는 것입니다.
정리하면 rearrange는 다음 세 가지를 자연어에 가깝게 표현하는 도구입니다.
1. 축 순서 변경: batch seq hidden -> batch hidden seq
2. 축 합치기: batch seq hidden -> (batch seq) hidden
3. 축 나누기: seq (heads head_dim) -> seq heads head_dim
Transformer 구현에서 multi-head attention, MLP projection, logits/loss 계산, batch-token flattening은 모두 이런 shape 변환을 자주 포함합니다. 따라서 einops는 단순히 코드 스타일을 예쁘게 만드는 라이브러리가 아니라, tensor shape을 잘못 해석해서 생기는 버그를 줄이고, memory/compute accounting을 더 정확하게 만드는 도구입니다.
8. FLOP과 FLOP/s: 연산량과 연산 속도는 다르다
이제 compute accounting으로 넘어갑니다.
강의에서는 먼저 헷갈리기 쉬운 두 용어를 구분합니다.
-
FLOPs: floating-point operations. 수행한 연산의 총량입니다.
-
FLOP/s 또는 FLOPS: floating-point operations per second. hardware 또는 실제 연산이 초당 처리하는 속도입니다.
예를 들어 덧셈 x + y 하나, 곱셈 x * y 하나를 각각 하나의 floating-point operation으로 봅니다.
LLM 학습 규모를 이해하려면 FLOPs 감각이 필요합니다. 강의에서는 다음 예시를 듭니다.
-
GPT-3 학습은 약
3.14e23 FLOPs가 들었다고 알려져 있습니다. 강의는 이 지점에서 GPT-3 FLOPs 설명 자료를 연결합니다. -
GPT-4 학습은 약
2e25 FLOPs가 들었을 것으로 추정된다는 자료가 있습니다. 강의는 GPT-4 FLOPs 추정 글을 연결합니다. -
H100은 Tensor Core GPU datasheet 기준으로 sparsity를 포함하면
1979 teraFLOP/speak 성능을 가질 수 있고, sparsity를 사용하지 않으면 대략 그 절반을 가정합니다.
예를 들어 8개의 H100을 2주 동안 사용한다면, 이상적인 peak 기준으로 가능한 연산량은 다음처럼 계산할 수 있습니다.
8 \times 2 \times (3600 \times 24 \times 7) \times \frac{1979 \times 10^{12}}{2}
이런 계산은 “이 실험이 현실적으로 가능한가?”를 빠르게 판단하는 데 사용됩니다.
9. Linear layer의 FLOPs 계산
가장 중요한 기본 연산은 matrix multiplication입니다. 강의에서는 다음 linear layer를 예로 듭니다.
N = 16384
D_in = 32768
D_out = 8192
x = torch.ones(N, D_in, device=device)
w = torch.randn(D_in, D_out, device=device)
y = x @ w
shape으로 보면 다음과 같습니다.
X \in \mathbb{R}^{N \times D_{in}},\quad
W \in \mathbb{R}^{D_{in} \times D_{out}},\quad
Y \in \mathbb{R}^{N \times D_{out}}
각 output element y[i, k]는 다음처럼 계산됩니다.
y[i,k] = \sum_j x[i,j] w[j,k]
하나의 y[i,k]를 만들기 위해 D_in개의 multiplication과 거의 D_in개의 addition이 필요합니다. 따라서 대략 2 x D_in FLOPs가 필요합니다.
출력 원소는 N x D_out개이므로 전체 FLOPs는 다음과 같습니다.
2 \times N \times D_{in} \times D_{out}
강의 예시 값으로 계산하면 다음과 같습니다.
2 \times 16384 \times 32768 \times 8192
= 8.796 \times 10^{12}\ \text{FLOPs}
즉, linear layer 하나의 forward만으로도 수조 단위 FLOPs가 나올 수 있습니다.
일반화하면 dense linear layer의 forward FLOPs는 다음처럼 생각할 수 있습니다.
2 \times \text{number of data points or tokens} \times \text{number of parameters}
Transformer에서도 attention과 FFN이 더 복잡하긴 하지만, 짧은 context length에서는 이 근사가 꽤 유용합니다.
10. Elementwise operation과 matmul의 차이
elementwise operation은 matrix의 각 원소에 독립적으로 적용되는 연산입니다. 예를 들어 m x n matrix 두 개를 더하면 원소별 덧셈이므로 약 mn FLOPs입니다.
반면 matrix multiplication은 훨씬 큽니다. 예를 들어 m x n matrix와 n x p matrix를 곱하면 대략 다음 FLOPs가 필요합니다.
2mnp
딥러닝 모델의 대부분 비용은 matmul에서 발생합니다. 특히 Transformer의 FFN, attention projection, output projection 등은 모두 큰 matrix multiplication으로 구성됩니다.
이 직관이 중요합니다.
LLM 학습의 compute 대부분은 거대한 matrix multiplication에서 나온다.
반대로 LayerNorm, activation function, dropout, residual addition 같은 elementwise 또는 reduction 기반 연산은 FLOPs 관점에서는 작아 보일 수 있습니다. 하지만 뒤에서 보듯이 이런 연산은 memory-bound일 수 있어서 wall-clock time에는 생각보다 영향을 줄 수 있습니다.
11. 실제 속도와 MFU(Model FLOPs Utilization)
이론적인 FLOPs를 계산했다고 해서 실제 시간이 바로 나오는 것은 아닙니다. 실제 실행 시간을 측정해야 합니다.
강의에서는 matrix multiplication을 benchmark해서 wall-clock time을 측정하고, 실제 FLOP/s를 다음처럼 계산합니다.
\text{actual FLOP/s}
= \frac{\text{actual number of FLOPs}}{\text{actual time}}
GPU spec sheet에는 dtype별 peak FLOP/s가 나옵니다. 예를 들어 H100 spec은 fp32, fp16, bf16, fp8 등 dtype에 따라 peak 성능이 크게 다릅니다.
MFU는 다음처럼 정의됩니다.
\text{MFU} = \frac{\text{actual FLOP/s}}{\text{promised FLOP/s}}
MFU가 1이면 GPU peak 성능을 완벽하게 쓰고 있다는 뜻이지만, 실제로는 거의 불가능합니다. communication overhead, memory access, kernel launch overhead, non-matmul operations, parallelism inefficiency 등 여러 요인이 있습니다.
강의에서는 MFU가 0.5 이상이면 꽤 좋은 편이라고 설명합니다.
다만 MFU가 높다는 것은 “연산을 잘 쓰고 있다”는 의미이지, 전체 시스템이 완벽하다는 뜻은 아닙니다. 예를 들어 data loading이 느리거나 distributed communication이 병목이면 전체 학습 throughput은 여전히 낮을 수 있습니다.
12. Arithmetic intensity: memory-bound와 compute-bound를 가르는 기준
MFU가 왜 1에 가까워지기 어려운지 이해하려면, GPU에서 하나의 연산이 실행될 때 계산 시간과 메모리 이동 시간이 따로 존재한다는 점을 봐야 합니다.
강의에서는 computation을 다음 세 단계로 단순화합니다.
-
input tensor를 HBM/GPU memory에서 accelerator 연산 유닛으로 가져온다.
-
accelerator에서 실제 계산을 수행한다.
-
output tensor를 다시 GPU memory에 저장한다.
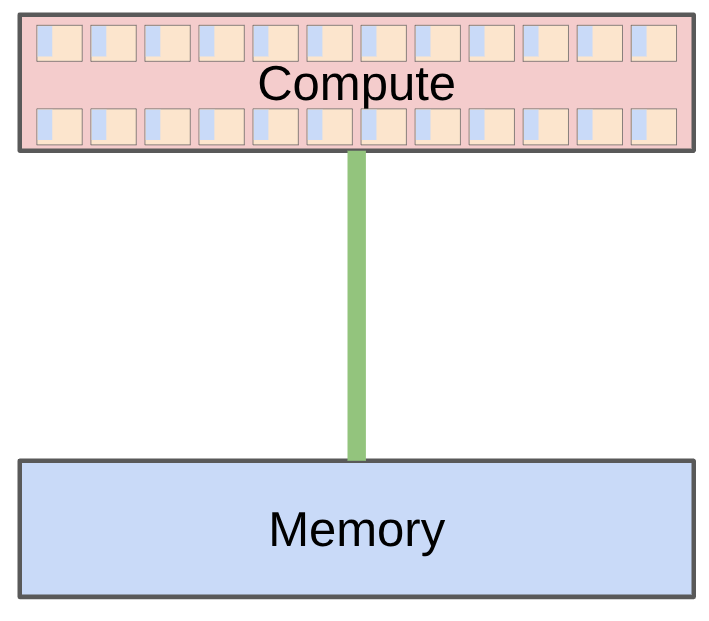 이때 어떤 연산이 느린 이유는 둘 중 하나입니다.
이때 어떤 연산이 느린 이유는 둘 중 하나입니다.
-
compute-bound: 계산 자체가 많아서 accelerator의 FLOP/s가 병목이다.
-
memory-bound: 계산은 가벼운데, 데이터를 읽고 쓰는 memory bandwidth가 병목이다.
강의에서는 H100을 예시로 다음 값을 사용합니다.
h100_flop_per_sec = 1979e12 / 2
h100_bytes_per_sec = 3.35e12
1979e12 / 2는 H100의 peak FLOP/s에서 sparsity 효과를 제외해 대략 절반으로 잡은 값입니다. 3.35e12는 H100 HBM memory bandwidth를 bytes/s 단위로 둔 값입니다.
여기서 중요한 값이 accelerator intensity입니다.
h100_accelerator_intensity = h100_flop_per_sec / h100_bytes_per_sec
수치로 계산하면 대략 다음과 같습니다.
h100_accelerator_intensity
= (1979e12 / 2) / 3.35e12
≈ 295 FLOPs/byte
이 값은 H100이 자신의 compute 성능을 꽉 채우려면 메모리에서 1 byte를 가져올 때마다 약 295번의 floating-point 연산을 해야 한다는 뜻입니다.
즉, H100은 계산 능력이 매우 강하기 때문에, byte당 연산량이 낮은 workload에서는 계산 유닛이 충분히 바쁘게 일하지 못합니다. 데이터를 읽고 쓰는 속도가 계산 속도를 따라가지 못하기 때문입니다.
반대로 workload마다 다음 값을 계산할 수 있습니다.
arithmetic_intensity = flops / bytes
이 값은 해당 연산이 메모리에서 1 byte를 이동할 때 실제로 몇 FLOPs를 수행하는가를 나타냅니다.
비교 기준은 다음과 같습니다.
arithmetic intensity < accelerator intensity → memory-bound
arithmetic intensity > accelerator intensity → compute-bound
직관적으로 말하면, workload가 byte당 일을 너무 적게 하면 memory-bound가 됩니다. 반대로 한 번 가져온 데이터를 많이 재사용하면서 계산을 많이 하면 compute-bound에 가까워집니다.
13. 예시 1: ReLU는 왜 memory-bound인가?
강의의 첫 번째 예시는 ReLU입니다.
def arithmetic_intensity_relu():
n = 1024 * 1024
x = torch.ones(n, dtype=torch.bfloat16, device=cuda_if_available())
y = torch.relu(x)
bytes = (2 * n) + (2 * n) # Read x, write y (bf16 is 2 bytes/float)
flops = n # n comparisons
communication_time = bytes / h100_bytes_per_sec
computation_time = flops / h100_flop_per_sec
# Assume we can overlap communication and computation perfectly.
total_time = max(communication_time, computation_time)
이 코드는 ReLU 하나가 GPU에서 실행될 때 메모리 이동량과 계산량을 분리해서 보는 예시입니다.
먼저 입력 tensor는 다음과 같습니다.
n = 1024 * 1024
x = torch.ones(n, dtype=torch.bfloat16, device=cuda_if_available())
즉, 원소가 약 100만 개인 vector입니다. dtype은 bfloat16이므로 원소 하나는 2 bytes입니다.
ReLU는 다음 연산입니다.
y = torch.relu(x)
수식으로 쓰면 각 원소마다 다음을 계산합니다.
y_i = max(x_i, 0)
원소 하나를 처리할 때 해야 하는 일은 매우 단순합니다. x_i가 0보다 큰지 비교하고, 크면 그대로 두고, 작으면 0으로 바꾸면 됩니다. 그래서 강의에서는 원소 하나당 대략 1 FLOP, 전체적으로 n FLOPs로 둡니다.
flops = n
그런데 memory 관점에서는 적어도 두 가지 이동이 필요합니다.
bytes = (2 * n) + (2 * n)
이 식의 의미는 다음과 같습니다.
-
2 * n: bf16 입력x를 읽는 비용 -
2 * n: bf16 출력y를 쓰는 비용
따라서 총 memory traffic은 4n bytes입니다.
Read x : 2n bytes
Write y: 2n bytes
Total : 4n bytes
이제 ReLU workload의 arithmetic intensity를 계산하면 다음과 같습니다.
arithmetic_intensity = flops / bytes
arithmetic_intensity
= n FLOPs / 4n bytes
= 1/4 FLOPs/byte
= 0.25 FLOPs/byte
이 값은 매우 낮습니다. H100의 accelerator intensity가 약 295 FLOPs/byte였으므로, ReLU는 H100이 compute 성능을 제대로 활용하기에 byte당 연산량이 압도적으로 부족합니다.
ReLU arithmetic intensity: 0.25 FLOPs/byte
H100 accelerator intensity: 약 295 FLOPs/byte
0.25 < 295
→ memory-bound
강의 코드에서는 이를 두 가지 방식으로 확인합니다.
첫 번째 방식은 시간을 직접 비교하는 방식입니다.
communication_time = bytes / h100_bytes_per_sec
computation_time = flops / h100_flop_per_sec
-
communication_time: x를 읽고 y를 쓰는 데 걸리는 시간 -
computation_time: ReLU 비교 연산을 수행하는 데 걸리는 시간
강의에서는 communication과 computation이 완벽히 overlap될 수 있다고 가정합니다.
total_time = max(communication_time, computation_time)
이 가정은 가장 낙관적인 경우입니다. 데이터 이동과 계산을 동시에 할 수 있다면 전체 시간은 둘의 합이 아니라 더 큰 쪽으로 결정됩니다.
그런데 ReLU에서는 communication_time > computation_time입니다. 즉, 계산은 이미 끝났는데 데이터 읽기/쓰기가 끝나지 않은 상태입니다.
communication_time > computation_time
→ memory-bound
두 번째 방식은 arithmetic intensity를 비교하는 방식입니다.
h100_accelerator_intensity = h100_flop_per_sec / h100_bytes_per_sec
arithmetic_intensity = flops / bytes
판단 기준은 다음입니다.
arithmetic_intensity < h100_accelerator_intensity
→ memory-bound
arithmetic_intensity > h100_accelerator_intensity
→ compute-bound
ReLU는 다음 관계를 만족합니다.
assert arithmetic_intensity < h100_accelerator_intensity
그래서 ReLU는 memory-bound입니다.
이 예시가 중요한 이유는 ReLU처럼 매우 간단한 elementwise operation은 FLOPs만 보면 거의 공짜처럼 보이지만, 실제 GPU에서는 반드시 tensor를 읽고 다시 써야 하기 때문입니다. 즉, 연산량이 작다고 항상 빠른 것이 아니라, 연산량이 너무 작아서 오히려 memory bandwidth가 지배적인 병목이 될 수 있습니다.
이 흐름에서 강의는 다음 질문으로 넘어갑니다.
Can we increase arithmetic intensity?
이 질문의 의미는 단순합니다. GPU를 더 잘 활용하려면, memory에서 한 번 가져온 데이터로 더 많은 계산을 해야 합니다. 예를 들어 matmul은 같은 weight와 activation 값을 여러 번 재사용하기 때문에 arithmetic intensity가 높고, ReLU 같은 isolated elementwise operation보다 GPU compute를 훨씬 잘 활용할 수 있습니다.
따라서 resource accounting 관점에서 중요한 결론은 다음입니다.
FLOPs가 작다 → 무조건 좋다
가 아니라,
메모리 이동량 대비 FLOPs가 충분히 큰가?
를 함께 봐야 한다는 것입니다. 이것이 arithmetic intensity의 핵심입니다.
14. 예시 2: GELU도 여전히 memory-bound다
GELU는 ReLU보다 계산이 복잡합니다. 일반적으로 tanh 근사 등을 사용하며, 강의에서는 원소 하나당 약 20 FLOPs 정도로 둡니다.
bf16 tensor 기준으로 memory transfer는 ReLU와 동일하게 4n bytes입니다.
FLOPs는 20n입니다.
따라서 arithmetic intensity는 다음입니다.
\frac{20n}{4n} = 5\ \text{FLOPs/byte}
ReLU의 0.25 FLOPs/byte보다는 훨씬 높지만, H100 기준 약 295 FLOPs/byte에는 한참 못 미칩니다. 따라서 GELU도 isolated operation으로 보면 memory-bound입니다.
여기서 흥미로운 점은, ReLU가 GELU보다 FLOPs는 적지만 실제로 항상 훨씬 빠르다고 말하기 어렵다는 것입니다. 둘 다 memory-bound이면 계산량보다 memory read/write가 병목이기 때문입니다.
15. 예시 3: dot product와 matrix-vector product도 memory-bound다
길이 n인 vector 두 개의 dot product를 생각해 봅시다.
y = x @ w
bf16 기준으로 x 읽기 2n, w 읽기 2n, output 쓰기 약 2 bytes가 필요합니다.
FLOPs는 multiplication n개와 addition n-1개이므로 대략 2n입니다.
arithmetic intensity는 대략 다음입니다.
\frac{2n}{4n} \approx \frac{1}{2}\ \text{FLOPs/byte}
따라서 dot product도 memory-bound입니다.
matrix-vector product도 비슷합니다. n x n matrix와 길이 n vector를 곱하면 FLOPs는 대략 2n^2입니다. 하지만 matrix w를 읽는 데만 2n^2 bytes가 필요합니다. 그래서 arithmetic intensity가 대략 1 근처에 머뭅니다.
이 부분은 LLM inference와 직접 연결됩니다. 특히 decoding 단계에서는 한 번에 새 token 하나를 생성하므로, 큰 batch가 아니면 많은 연산이 matrix-vector에 가까워집니다. 그래서 decoding은 compute보다 parameter/KV cache를 읽는 memory bandwidth가 병목이 되기 쉽습니다.
16. 예시 4: matrix multiplication은 compute-bound가 될 수 있다
이제 n x n matrix 두 개를 곱한다고 합시다.
y = x @ w
bf16 기준 memory transfer는 대략 다음입니다.
-
x읽기:2n^2 -
w읽기:2n^2 -
y쓰기:2n^2
총 bytes는 다음입니다.
6n^2\ \text{bytes}
FLOPs는 n^2개의 output 각각에 대해 길이 n dot product를 수행하므로 다음입니다.
n^2(2n - 1) \approx 2n^3
따라서 arithmetic intensity는 다음과 같이 근사됩니다.
\frac{2n^3}{6n^2} = \frac{n}{3}
n = 1024이면 arithmetic intensity는 약 341 FLOPs/byte입니다. 이는 H100의 accelerator intensity 약 295보다 큽니다. 따라서 큰 matrix multiplication은 compute-bound가 됩니다.
이것이 LLM training에서 중요한 이유는, Transformer 학습의 주요 연산이 큰 matrix multiplication이기 때문입니다. 큰 matmul이 충분히 많으면 GPU의 compute unit을 잘 활용할 수 있습니다.
반면 inference의 decoding처럼 batch가 작거나 token을 하나씩 처리하는 경우에는 matrix-vector 성격이 강해져 memory-bound가 되기 쉽습니다.
17. Roofline plot: arithmetic intensity와 성능을 함께 보는 그림
Roofline plot은 arithmetic intensity와 실제 성능의 관계를 시각화하는 도구입니다.
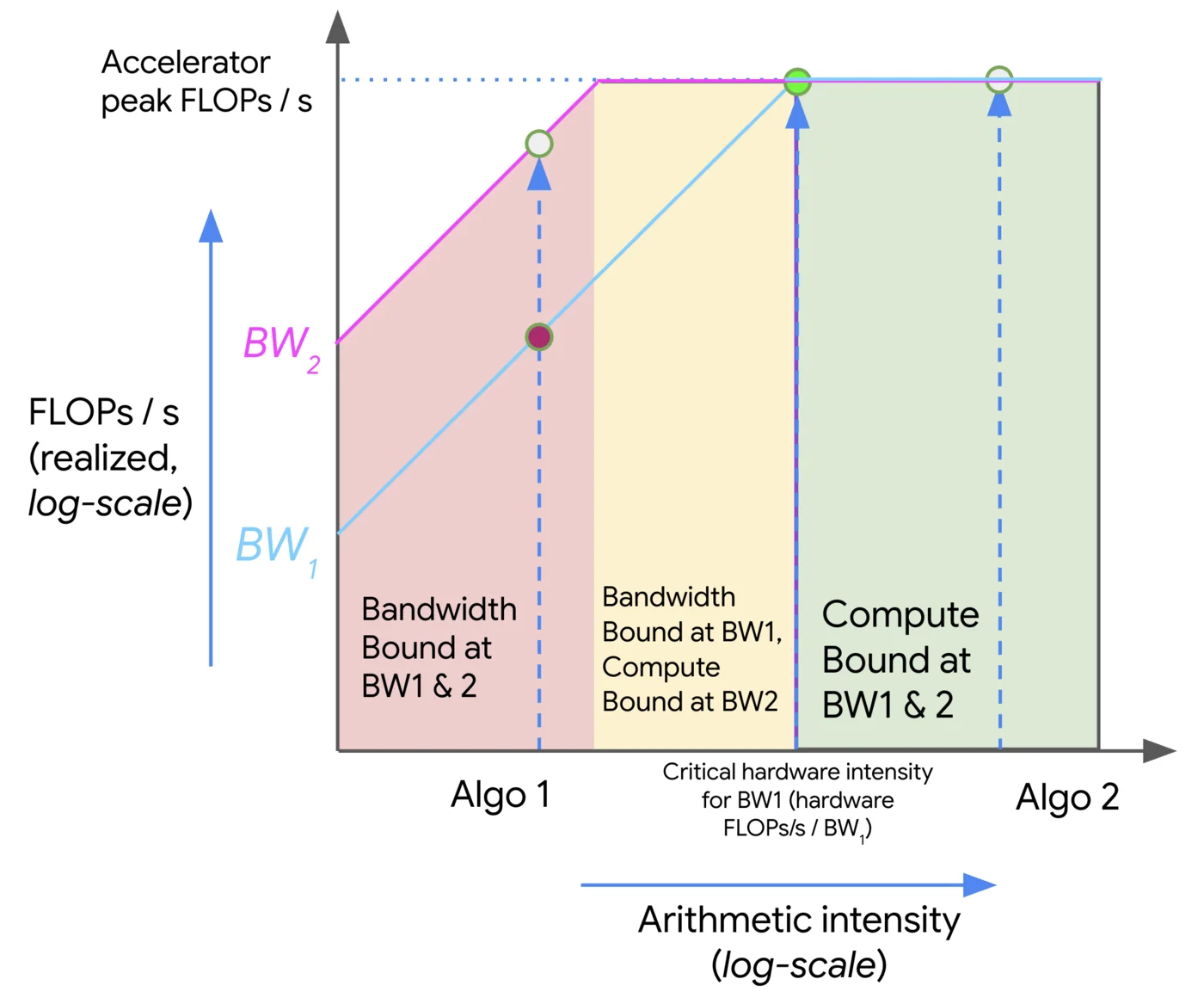
강의는 여기서 JAX Scaling Book의 roofline 설명을 참고 링크로 붙입니다. roofline plot에서 x축은 arithmetic intensity입니다. y축은 달성 가능한 FLOP/s입니다. 그래프의 꺾이는 지점은 memory-bound에서 compute-bound로 넘어가는 transition point입니다.
-
왼쪽 영역: arithmetic intensity가 낮아 memory bandwidth가 성능을 제한합니다.
-
오른쪽 영역: arithmetic intensity가 충분히 높아 compute peak가 성능을 제한합니다.
강의에서는 이를 MFU와 연결해 다음과 같은 직관을 제시합니다.
\text{MFU} \approx \min\left(1,\frac{\text{arithmetic intensity}}{\text{accelerator intensity}}\right)
물론 실제 시스템에서는 kernel overhead, communication, scheduling overhead, cache behavior 등이 있어 더 복잡하지만, 이 식은 왜 어떤 연산은 GPU를 잘 쓰고 어떤 연산은 못 쓰는지 이해하는 데 유용합니다.
18. Deep network 예시: parameter 수 세기
이제 training의 memory와 compute를 세기 위해 간단한 deep network를 봅니다.
강의의 Block은 다음과 같은 구조입니다.
class Block(nn.Module):
def __init__(self, dim):
self.weight = nn.Parameter(torch.randn(dim, dim) / math.sqrt(dim))
def forward(self, x):
x = x @ self.weight
x = F.relu(x)
return x
즉, 하나의 block은 linear transformation 하나와 ReLU activation 하나로 이루어져 있습니다.
이를 L개 쌓으면 DeepNetwork가 됩니다.

각 layer의 weight shape이 D x D이면 layer 하나의 parameter 수는 다음입니다.
D^2
layer가 L개이면 전체 parameter 수는 다음입니다.
D^2L
이 단순한 MLP 예시는 뒤에서 gradients, optimizer states, activation memory를 세기 위한 기준 모델로 사용됩니다.
19. Gradient basics: backward pass에서 무엇을 계산하는가
forward pass는 입력을 받아 loss를 계산하는 과정입니다. backward pass는 loss를 줄이기 위해 각 parameter를 어떻게 바꿔야 하는지 gradient를 계산하는 과정입니다.
강의에서는 간단한 예시를 듭니다.
x = torch.tensor([1., 2, 3])
w = torch.tensor([1., 1, 1], requires_grad=True)
pred_y = x @ w
loss = 0.5 * (pred_y - 5).pow(2)
loss.backward()
여기서 pred_y는 다음입니다.
pred_y = 1 \times 1 + 2 \times 1 + 3 \times 1 = 6
loss는 다음입니다.
L = \frac{1}{2}(6 - 5)^2 = \frac{1}{2}
gradient는 chain rule로 계산됩니다.
\frac{\partial L}{\partial w}
= (pred_y - 5) \frac{\partial pred_y}{\partial w}
pred_y = x @ w이므로 w에 대한 미분은 x입니다. 그리고 pred_y - 5 = 1이므로 결과는 다음입니다.
w.grad = [1,2,3]
PyTorch의 autograd는 이 과정을 자동으로 수행합니다. 하지만 resource accounting을 하려면 autograd가 내부적으로 어떤 계산을 수행하는지 알아야 합니다.
20. Backward pass FLOPs: 왜 forward의 2배인가
강의에서는 2-layer linear network를 통해 backward FLOPs를 셉니다.
h1 = x @ w1
h2 = h1 @ w2
loss = (h2.mean() - 0) ** 2
loss.backward()
여기서 두 번째 layer에 집중합니다.
h_2 = h_1 W_2
shape은 다음과 같습니다.
h_1 \in \mathbb{R}^{B \times D},\quad
W_2 \in \mathbb{R}^{D \times D},\quad
h_2 \in \mathbb{R}^{B \times D}
forward pass FLOPs는 다음입니다.
2 \times B \times D \times D
backward에서는 두 가지 gradient를 계산해야 합니다.
-
h1.grad, 즉 loss를h1에 대해 미분한 값 -
w2.grad, 즉 loss를W2에 대해 미분한 값
먼저 h1.grad는 다음과 같습니다.
\frac{\partial L}{\partial h_1}
= \frac{\partial L}{\partial h_2} W_2^T
이는 matrix multiplication 하나입니다. FLOPs는 forward와 같은 규모인 다음입니다.
2 \times B \times D \times D
다음으로 w2.grad는 다음과 같습니다.
\frac{\partial L}{\partial W_2}
= h_1^T \frac{\partial L}{\partial h_2}
이것도 matrix multiplication 하나입니다. FLOPs는 역시 다음입니다.
2 \times B \times D \times D
따라서 backward pass 전체 FLOPs는 다음입니다.
(2BDD) + (2BDD) = 4BDD
forward가 2BDD였으므로, backward는 forward의 약 2배입니다.
정리하면 하나의 dense layer에 대해 다음 근사가 성립합니다.
-
forward pass:
2 x data x params -
backward pass:
4 x data x params -
total:
6 x data x params
이것이 앞에서 70B 모델 학습 FLOPs를 계산할 때 사용한 6 x parameters x tokens의 근거입니다.
21. Transformer에도 6 x tokens x params가 유용한 이유
강의에서는 이 계산이 MLP에 대해 유도된 것이지만, short context length의 Transformer에도 꽤 좋은 근사라고 설명합니다.
Transformer는 attention, feedforward, normalization, activation 등으로 구성되어 있어 정확한 FLOPs 계산은 더 복잡합니다. 하지만 큰 dense matmul이 compute 대부분을 차지하기 때문에, 전체 pretraining FLOPs를 빠르게 추정할 때는 다음 식이 널리 사용됩니다.
\text{training FLOPs} \approx 6 \times N_{tokens} \times N_{params}
단, context length가 길어지면 attention의 sequence length 제곱 항이 커질 수 있습니다. 따라서 long-context 모델에서는 이 단순 근사가 부족할 수 있습니다. 그럼에도 일반적인 LLM pretraining 규모를 빠르게 잡는 데는 매우 유용합니다.
22. Optimizer state: AdaGrad, RMSProp, Adam, AdamW
이제 optimizer가 memory를 얼마나 차지하는지 봅니다.
강의에서는 AdaGrad를 직접 구현하면서 optimizer state를 설명합니다.
-
Momentum: gradient의 exponential average를 사용합니다.
-
AdaGrad: gradient 제곱의 누적합으로 learning rate를 조정합니다.
-
RMSProp: AdaGrad처럼 gradient 제곱을 쓰되, exponential average를 사용합니다.
-
Adam: RMSProp의 second moment와 momentum의 first moment를 함께 사용합니다.
AdaGrad update는 대략 다음 형태입니다.
g_2 \leftarrow g_2 + g^2
p \leftarrow p - \eta \frac{g}{\sqrt{g_2 + \epsilon}}
여기서 g2가 optimizer state입니다. 즉, parameter 자체 외에도 optimizer가 학습을 위해 추가 tensor를 들고 있어야 합니다.
Adam 계열은 보통 다음 두 가지 state를 가집니다.
-
first moment: gradient 평균, momentum에 해당
-
second moment: gradient 제곱 평균, RMSProp 계열에 해당
따라서 Adam은 parameter 하나당 optimizer state가 보통 두 개 필요합니다. 안정성을 위해 이 state들은 fp32로 저장하는 경우가 많으므로, optimizer state만 4 + 4 = 8 bytes/parameter가 됩니다.
한국어 PDF에는 AdamW도 recap 형태로 등장합니다. AdamW는 Adam에서 weight decay를 decoupled 방식으로 적용한 optimizer입니다. 일반 Adam에 L2 regularization처럼 weight decay를 섞으면 adaptive learning rate와 상호작용하면서 의도한 weight decay 효과가 약해질 수 있습니다. AdamW는 weight decay를 gradient update와 분리해 일반화 성능을 개선하려는 방식입니다.
23. Training memory accounting
간단한 DeepNetwork를 기준으로 memory를 세어 봅니다.
변수는 다음과 같습니다.
-
B: batch size -
D: hidden dimension -
L: number of layers -
num_parameters = D x D x L
공식 강의의 mixed precision 기준 memory는 다음처럼 볼 수 있습니다.
23.1 Parameter memory
parameter를 bf16으로 저장한다고 하면 parameter 하나는 2 bytes입니다.
\text{parameter memory} = 2 \times \#params
23.2 Gradient memory
gradient도 bf16으로 저장한다고 하면 parameter 하나당 gradient 하나가 필요합니다.
\text{gradient memory} = 2 \times \#params
23.3 Optimizer state memory
AdaGrad는 second moment 하나만 저장하므로 fp32 기준 다음입니다.
\text{AdaGrad optimizer state memory} = 4 \times \#params
Adam은 first moment와 second moment를 모두 저장하므로 다음입니다.
\text{Adam optimizer state memory} = 8 \times \#params
23.4 Activation memory
각 layer의 activation을 bf16으로 저장한다고 하면 다음처럼 근사할 수 있습니다.
\text{activation memory} = 2 \times B \times D \times L
여기서 activation memory는 batch size, sequence length, hidden dimension, number of layers에 따라 커집니다. 실제 Transformer에서는 attention activation, MLP intermediate activation, residual stream 등 때문에 더 복잡합니다.
공식 강의에서는 Transformer의 정확한 accounting은 assignment에서 다룬다고 하며, 참고 자료로 Transformer training memory usage와 Transformer FLOPs를 제시합니다.
24. Training loop: 실제 학습 step의 구조
강의에서는 가장 기본적인 training loop도 보여줍니다. 예시는 D = 16 차원의 입력을 받고, 실제 정답 함수를 true_w = [0, 1, 2, ..., D-1]로 둔 뒤, x @ true_w를 정답 y로 만드는 toy regression 설정입니다. 모델은 L = 2개의 layer를 가진 DeepNetwork이고, optimizer는 앞에서 직접 정의한 AdaGrad(lr=0.01)입니다. 강의 코드는 구조를 보여주기 위해 num_train_steps = 3으로 짧게 둡니다.
D = 16
true_w = torch.arange(D, dtype=torch.float32, device=cuda_if_available())
B = 4
L = 2
model = DeepNetwork(dim=D, num_layers=L).to(cuda_if_available())
optimizer = AdaGrad(model.parameters(), lr=0.01)
num_train_steps = 3
for t in range(num_train_steps):
x, y = get_batch()
pred_y = model(x).mean()
loss = F.mse_loss(pred_y, y)
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
이 loop는 LLM 학습에서도 기본 구조는 같습니다.
-
batch를 가져온다.
-
forward pass로 prediction과 loss를 계산한다.
-
backward pass로 gradients를 계산한다.
-
optimizer step으로 parameters를 업데이트한다.
-
gradients를 초기화한다.
resource accounting 관점에서는 각 단계가 무엇을 요구하는지 봐야 합니다.
-
forward: activations를 생성하고 저장한다.
-
backward: 저장된 activations를 사용해 gradients를 계산한다.
-
optimizer step: parameters, gradients, optimizer states를 읽고 업데이트한다.
-
zero_grad: 다음 step을 위해 gradient memory를 초기화하거나 None으로 둔다.
25. Gradient accumulation: batch size를 키우되 memory는 줄이는 방법
큰 batch size는 학습 안정성에 도움이 될 수 있습니다. gradient estimate의 variance가 줄어들고, 대규모 분산 학습에서 throughput을 높이는 데도 유리합니다.
하지만 batch size를 키우면 activation memory가 증가합니다.
강의 예시에서는 activation memory를 다음처럼 둡니다.
2 \times B \times D \times L
B = 64, D = 1024, L = 16이면 다음입니다.
2 \times 64 \times 1024 \times 16
= 2,097,152\ \text{bytes}
단순 예시에서는 약 2MB지만, 실제 Transformer에서는 sequence length와 intermediate activation까지 포함되어 훨씬 커집니다.
Gradient accumulation의 핵심은 큰 batch를 여러 micro-batch로 쪼개는 것입니다.
예를 들어 global batch size가 64인데 micro-batch size를 16으로 두면, 4번의 forward/backward를 수행하면서 gradient를 누적하고, 그 후 한 번 optimizer step을 수행합니다.
절차는 다음과 같습니다.
-
micro-batch로 forward/backward를 수행한다.
-
optimizer.zero_grad()를 호출하지 않고 gradient를 누적한다. -
batch_size / micro_batch_size번 누적한 뒤 optimizer step을 수행한다. -
그때 gradient를 초기화한다.
이렇게 하면 activation memory는 micro-batch size에 비례하므로 줄어듭니다. 대신 optimizer update 한 번을 위해 forward/backward를 여러 번 수행해야 하므로 wall-clock time이나 throughput 측면에서는 trade-off가 있습니다.
중요한 점은 gradient accumulation이 parameter memory나 optimizer state memory를 줄이는 것은 아니라는 점입니다. 줄어드는 것은 주로 activation memory입니다.
26. Activation checkpointing: memory를 compute로 바꾸는 방법
학습에서는 backward pass를 위해 forward pass 중간 activations를 저장해야 합니다. 왜냐하면 gradient를 계산할 때 각 layer의 input/output activation이 필요하기 때문입니다.
반면 inference에서는 gradient를 계산하지 않으므로, 모든 layer의 activation을 저장할 필요가 없습니다. 현재 layer의 activation만 있으면 다음 layer로 넘길 수 있습니다.
이 차이 때문에 training activation memory가 inference보다 훨씬 큽니다.
Activation checkpointing은 이 문제를 줄이기 위한 기법입니다. 다른 이름으로는 다음과 같이 부릅니다.
-
gradient checkpointing
-
rematerialization
핵심 아이디어는 다음입니다.
-
forward pass에서 모든 activation을 저장하지 않는다.
-
일부 checkpoint layer의 activation만 저장한다.
-
backward pass에서 필요한 activation은 마지막 checkpoint부터 다시 forward 계산해 복원한다.
즉, memory를 줄이는 대신 compute를 더 쓰는 방식입니다.
PyTorch에서는 다음처럼 사용할 수 있습니다.
x = torch.utils.checkpoint.checkpoint(layer, x)
강의는 이 차이를 다음처럼 직관적으로 보여줍니다.
모든 activation 저장:
x, g1, h1, g2, h2, g3, h3, g4, h4
activation checkpointing:
x, h1, h2, h3, h4
더 깊은 네트워크에서는 어떤 layer를 checkpoint로 남길지 선택해야 합니다.
모든 layer 저장: | h1 h2 h3 h4 h5 h6 h7 h8 h9 |
아무 layer도 저장하지 않음: | |
일부 layer만 저장: | h3 h6 h9 |
강의에서는 checkpoint 빈도에 따른 trade-off를 다음처럼 설명합니다.
-
모든 layer activation을 저장하면 activation memory는
O(L)이고 recomputation은 없다. -
아무 activation도 저장하지 않으면 memory는
O(1)이지만, backward 때 매번 처음부터 재계산해야 하므로 compute가O(L^2)까지 늘 수 있다. -
sqrt(L)간격으로 checkpoint를 저장하면 activation memory는O(sqrt(L))이고, recomputation은O(L)수준으로 유지할 수 있다.
실제 LLM 학습에서 gradient checkpointing은 매우 자주 사용됩니다. 특히 sequence length가 길거나 batch size를 키우고 싶을 때 activation memory를 줄이는 핵심 기법입니다.
27. Inference와 연결: prefill은 compute-bound, decoding은 memory-bound가 되기 쉽다
공식 강의의 arithmetic intensity 파트는 training과 inference를 이해하는 데도 중요합니다. 특히 LLM inference는 크게 두 단계로 나눌 수 있습니다.
27.1 Prefill phase
prefill은 사용자의 prompt 전체를 한 번에 모델에 넣어 KV cache를 만드는 단계입니다. 예를 들어 prompt가 1024 tokens라면, 이 1024 tokens를 병렬적으로 처리하면서 각 layer의 key/value를 cache에 저장합니다.
이 단계에서는 여러 token을 한 번에 처리하므로 연산이 matrix-matrix multiplication에 가깝습니다. 따라서 arithmetic intensity가 높아지고 compute-bound가 되기 쉽습니다.
즉, prefill은 다음과 같은 성격을 가집니다.
-
prompt 길이만큼 많은 token을 한 번에 처리한다.
-
큰 matmul이 많이 발생한다.
-
GPU compute를 비교적 잘 활용한다.
-
prompt가 길수록 prefill 비용이 커진다.
27.2 Decoding phase
decoding은 새 token을 하나씩 생성하는 단계입니다. 이미 만들어 둔 KV cache를 참조하면서 다음 token을 예측하고, 생성된 token을 다시 KV cache에 추가합니다.
이 단계에서는 한 step에 새 token 하나 또는 작은 batch만 처리하는 경우가 많습니다. 따라서 큰 matrix-matrix multiplication보다 matrix-vector 또는 skinny matrix multiplication 성격이 강해집니다. 이 경우 arithmetic intensity가 낮아지고, GPU compute보다 memory bandwidth가 병목이 되기 쉽습니다.
즉, decoding은 다음과 같은 성격을 가집니다.
-
token을 순차적으로 생성한다.
-
매 token마다 model weights와 KV cache를 읽어야 한다.
-
compute unit보다 memory bandwidth가 병목이 되기 쉽다.
-
batch size가 작으면 특히 memory-bound가 강해진다.
이것이 “LLM inference는 memory-bound다”라는 말의 핵심입니다. 더 정확히 말하면, prefill은 compute-bound에 가까울 수 있고, decoding은 memory-bound에 가까운 경우가 많다고 보는 것이 좋습니다.
28. 전체 요약
이번 강의의 핵심은 LLM 학습을 감으로만 보지 말고, memory와 compute를 직접 세자는 것입니다.
먼저 memory 관점에서는 tensor가 모든 것을 저장합니다.
-
parameters
-
gradients
-
optimizer states
-
activations
-
data
각 tensor의 memory는 원소 수와 dtype으로 계산됩니다.
\text{memory} = \text{numel} \times \text{element size}
dtype은 memory와 stability를 함께 결정합니다.
-
fp32는 안정적이지만 크다.
-
fp16은 작지만 dynamic range가 좁다.
-
bf16은 fp16과 같은 memory를 쓰면서 fp32에 가까운 dynamic range를 가진다.
-
fp8/fp4는 더 작지만 scale 관리와 hardware/kernel 지원이 중요하다. 특히 NVFP4는 FP4 값만 쓰는 것이 아니라 16개 값 단위의 FP8 scale과 tensor-level scale을 함께 사용해 quantization error를 줄인다.
-
mixed precision은 LLM 학습의 표준적인 절충안이다.
compute 관점에서는 matmul이 핵심입니다.
-
linear forward FLOPs는 대략
2 x data x params입니다. -
backward FLOPs는 대략
4 x data x params입니다. -
training 전체는 대략
6 x data x params입니다.
이 식으로 70B 모델을 15T tokens로 학습할 때 필요한 총 연산량도 빠르게 추정할 수 있습니다.
또한 실제 성능을 이해하려면 FLOPs만 보면 안 됩니다. memory bandwidth와 arithmetic intensity를 함께 봐야 합니다.
-
elementwise operation은 memory-bound가 되기 쉽다.
-
dot product와 matrix-vector product도 memory-bound가 되기 쉽다.
-
큰 matrix multiplication은 compute-bound가 되기 쉽다.
-
LLM training은 큰 matmul이 많아 compute-bound 성격이 강하다.
-
LLM decoding inference는 matrix-vector 성격이 강해 memory-bound가 되기 쉽다.
마지막으로 memory를 줄이는 대표적인 기법으로 gradient accumulation과 activation checkpointing이 등장합니다.
-
gradient accumulation은 micro-batch로 gradient를 누적해 activation memory를 줄인다.
-
activation checkpointing은 일부 activation만 저장하고 backward 때 재계산해 memory를 줄인다.
-
둘 다 memory를 줄이지만, throughput이나 compute overhead와 trade-off가 있다.
29. 실전 체크리스트
LLM 학습 실험을 설계할 때는 다음 순서로 생각하면 좋습니다.
-
모델 parameter 수는 얼마인가?
-
dtype은 무엇인가? bf16인가, fp16인가, fp32인가?
-
parameter memory는 얼마인가?
-
gradient memory는 얼마인가?
-
optimizer state는 몇 개이며 fp32로 저장되는가?
-
activation memory는 batch size, sequence length, layer 수에 따라 얼마나 커지는가?
-
forward/backward FLOPs는 대략 얼마인가?
-
GPU peak FLOP/s와 예상 MFU를 고려하면 학습 시간이 얼마나 걸리는가?
-
연산이 compute-bound인지 memory-bound인지 판단할 수 있는가?
-
memory가 부족하면 gradient accumulation이나 activation checkpointing으로 줄일 수 있는가?
이 체크리스트를 습관화하면, “GPU가 부족하다”, “batch size를 못 키운다”, “학습이 생각보다 느리다” 같은 문제를 더 구조적으로 분석할 수 있습니다.
30. 링크 및 이미지 모음
위 본문에는 강의 원문에서 링크가 등장하는 위치에 맞춰 주요 링크를 다시 삽입했습니다. 아래는 검수용 모음입니다.
공식 강의 및 코드:
-
CS336 Lecture 02: https://cs336.stanford.edu/lectures/?trace=lecture_02
-
lecture_02.py: https://github.com/stanford-cs336/lectures/blob/main/lecture_02.py
-
references.py: https://github.com/stanford-cs336/lectures/blob/main/references.py
이미지:
-
Marin run image: https://pbs.twimg.com/media/HE1P1HmaUAAjLXF?format=jpg&name=medium
-
fp32: https://raw.githubusercontent.com/stanford-cs336/lectures/refs/heads/main/images/fp32.png
-
fp16: https://raw.githubusercontent.com/stanford-cs336/lectures/refs/heads/main/images/fp16.png
-
bf16: https://raw.githubusercontent.com/stanford-cs336/lectures/refs/heads/main/images/bf16.png
-
CPU/GPU: https://raw.githubusercontent.com/stanford-cs336/lectures/refs/heads/main/images/cpu-gpu.png
-
compute/memory: https://raw.githubusercontent.com/stanford-cs336/lectures/refs/heads/main/images/compute-memory.png
-
deep network: https://raw.githubusercontent.com/stanford-cs336/lectures/refs/heads/main/images/deep-network.png
-
roofline plot: https://jax-ml.github.io/scaling-book/assets/img/roofline-improved-1400.webp
-
FP8 formats: https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/_images/fp8_formats.png
참고 자료:
-
DeepSeek V3.2: https://arxiv.org/abs/2512.02556
-
DeepSeek V3.2 HF weights index: https://huggingface.co/deepseek-ai/DeepSeek-V3.2?show_file_info=model.safetensors.index.json
-
fp32 Wikipedia: https://en.wikipedia.org/wiki/Single-precision_floating-point_format
-
fp16 Wikipedia: https://en.wikipedia.org/wiki/Half-precision_floating-point_format
-
bf16 Wikipedia: https://en.wikipedia.org/wiki/Bfloat16_floating-point_format
-
Mixed Precision Training: https://arxiv.org/pdf/1710.03740.pdf
-
PyTorch AMP docs: https://pytorch.org/docs/stable/amp.html
-
NVIDIA FP8 primer: https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/examples/fp8_primer.html
-
FP8 paper: https://arxiv.org/pdf/2209.05433.pdf
-
NVFP4 blog: https://developer.nvidia.com/blog/introducing-nvfp4-for-efficient-and-accurate-low-precision-inference/
-
Nemotron 3 Super report: https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf
-
Einops tutorial: https://einops.rocks/1-einops-basics/
-
GPT-3 FLOPs explanation: https://lambdalabs.com/blog/demystifying-gpt-3
-
GPT-4 FLOPs estimate: https://patmcguinness.substack.com/p/gpt-4-details-revealed
-
H100 Tensor Core datasheet: https://resources.nvidia.com/en-us-tensor-core/nvidia-tensor-core-gpu-datasheet
-
H100 datasheet: https://resources.nvidia.com/en-us-gpu-resources/h100-datasheet-24306
-
JAX Scaling Book roofline: https://jax-ml.github.io/scaling-book/roofline/
-
AdaGrad paper: https://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf
-
AdamW paper: https://arxiv.org/pdf/1711.05101.pdf
-
Transformer memory usage: https://erees.dev/transformer-memory/
-
Transformer FLOPs: https://www.adamcasson.com/posts/transformer-flops
Comments