0. 이 정리본을 읽는 방법
이 강의는 일반적인 PDF 슬라이드가 아니라 executable lecture 형식이다. 즉, Python 코드가 실행되면서 강의 내용, 이미지, 링크, 예시 코드, 변수 inspection이 함께 나타나는 구조다.
따라서 이 정리본도 단순히 제목을 나열하는 방식이 아니라 다음 흐름을 따른다.
-
CS336이라는 수업이 왜 만들어졌는지
-
현재 language model 생태계가 어떻게 변했는지
-
왜 open model과 효율성이 중요한지
-
수업 전체가 어떤 구성으로 진행되는지
-
그 첫 번째 기술 주제인 tokenization이 왜 중요한지
-
character / byte / word / BPE tokenizer가 각각 어떤 장단점을 갖는지
핵심은 하나다.
Language model을 제대로 이해하려면 API 사용법이 아니라,
데이터 → 토크나이저 → 모델 구조 → 학습 → 시스템 → 평가 → 정렬까지
전체 stack을 직접 뜯어봐야 한다.
1. Welcome: CS336의 출발점

강의는 CS336: Language Models From Scratch라는 제목으로 시작한다. Spring 2026은 세 번째 offering이며, Spring 2025 강의는 YouTube에 공개되어 있다.
Spring 2026에서 강조하는 변화는 다음과 같다.
-
기존과 동일하게 “from scratch” 철학을 유지한다.
-
세부 구현에 매몰되지 않고, 시간 대비 가치가 높은 개념을 우선한다.
-
최신 language model 구성 요소를 더 많이 다룬다.
-
Mixture of Experts
-
Long-context modeling
-
Agents
CS336의 핵심은 “LLM을 사용하는 법”이 아니라 LLM을 만드는 법이다. 여기서 from scratch는 모든 것을 C/CUDA로 처음부터 만든다는 뜻은 아니다. 오히려 LLM을 이루는 핵심 계층을 직접 구현하거나 정량적으로 이해한다는 의미에 가깝다.
예를 들어 일반적인 AI 강의는 Transformer 구조를 설명하고 Hugging Face로 fine-tuning하는 정도에서 끝나는 경우가 많다. 반면 CS336은 tokenizer 구현, Transformer 구현, AdamW 구현, training loop, GPU profiling, scaling laws, data filtering, DPO/GRPO까지 연결한다.
즉 이 강의의 목표는 다음에 가깝다.
LLM을 블랙박스로 쓰는 사람이 아니라,
LLM 시스템의 병목과 설계 선택을 설명할 수 있는 사람이 되는 것.
2. Why did we make this course?
강의는 먼저 문제의식을 제시한다.
Problem: researchers are becoming disconnected from the underlying technology.
즉, 연구자들이 점점 underlying technology에서 멀어지고 있다는 것이다.
강의에서는 시기별 변화를 다음과 같이 정리한다.
| 시기 | 연구자가 주로 하던 일 | 의미 |
|---|---|---|
| 2016년 | 직접 모델을 구현하고 학습 | 모델 내부와 학습 과정에 가까움 |
| 2018년 | BERT 같은 pretrained model을 다운로드해 fine-tuning | 모델 구현보다 활용 중심으로 이동 |
| 현재 | GPT, Claude, Gemini 같은 API 모델에 prompt 입력 | 내부 구조와 학습 과정에서 멀어짐 |
이 흐름은 생산성 측면에서는 자연스럽다. API를 쓰면 빠르게 실험할 수 있고, 좋은 성능도 쉽게 얻을 수 있다. 하지만 강의는 이 추상화가 leaky abstraction이라고 지적한다.
프로그래밍 언어나 운영체제의 abstraction은 비교적 안정적이다. 예를 들어 Python에서 리스트를 쓰는 사람은 매번 메모리 allocator를 이해하지 않아도 된다. 하지만 LLM API는 다르다.
LLM API의 추상화는 다음과 같은 이유로 쉽게 샌다.
-
prompt 길이에 따라 비용과 latency가 크게 달라진다.
-
모델이 언제 hallucination하는지 API만 보고는 알기 어렵다.
-
같은 prompt도 decoding 설정, system prompt, tokenizer, context length에 따라 달라진다.
-
모델 업데이트가 일어나면 이전 실험이 재현되지 않을 수 있다.
-
모델이 왜 특정 task에서 실패하는지 내부 구조를 모르면 분석하기 어렵다.
그래서 CS336은 말한다.
Full understanding of this technology is necessary for fundamental research.
즉, 근본적인 연구를 하려면 LLM stack을 이해해야 한다. 이 수업의 철학은 understanding via building, 즉 직접 만들어보면서 이해하는 것이다.
3. The industrialization of language models

이제 강의는 LLM이 산업화되었다는 점을 강조한다. Frontier model은 너무 비싸고, 내부 정보도 공개되지 않는다.
강의에서 언급하는 예시는 다음과 같다.
- 2023년: GPT-4 학습 비용이 약 1억 달러였을 것으로 언급됨
- 2025년: xAI가 Grok 학습을 위해 230K GPU cluster를 구축했다고 언급됨
GPT-4 technical report에 대한 강의 이미지도 등장한다.

이 부분의 메시지는 간단하다.
프론티어 모델은 너무 비싸서 우리가 직접 재현할 수 없고,
기술 보고서도 핵심 학습 세부사항을 충분히 공개하지 않는다.
예전에는 논문을 읽고 모델을 어느 정도 재현할 수 있었다. 하지만 GPT-4 이후의 frontier model은 다음 정보가 공개되지 않는 경우가 많다.
-
정확한 모델 구조
-
parameter 수
-
데이터 구성
-
데이터 필터링 기준
-
학습 토큰 수
-
optimizer 세팅
-
learning rate schedule
-
RLHF 또는 RLVR 세부 recipe
-
serving system 구조
따라서 연구자는 두 가지 문제에 부딪힌다.
-
첫째, frontier model을 직접 만들 수 없다.
-
둘째, frontier model이 왜 잘 되는지 완전히 알기 어렵다.
그렇다고 작은 모델만 학습하면 충분할까? 강의는 그렇지 않다고 말한다.
4. 작은 모델은 frontier model을 대표할 수 있는가?
강의는 작은 language model, 예를 들어 1B 미만 모델을 만들 수는 있지만, 그것이 large language model을 항상 대표하지는 않는다고 설명한다.
Example 1. Attention과 MLP FLOPs 비율은 scale에 따라 달라진다
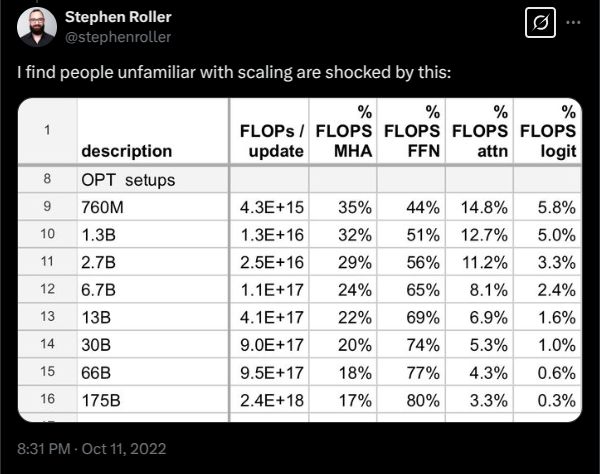
관련 게시물: Stephen Roller post
작은 모델에서는 attention과 MLP의 상대적 계산 비중이 큰 모델과 다를 수 있다. 즉, 작은 모델에서 병목이었던 것이 큰 모델에서는 병목이 아닐 수 있고, 반대로 작은 모델에서 중요하지 않았던 최적화가 큰 모델에서는 결정적일 수 있다.
Example 2. Emergent behavior
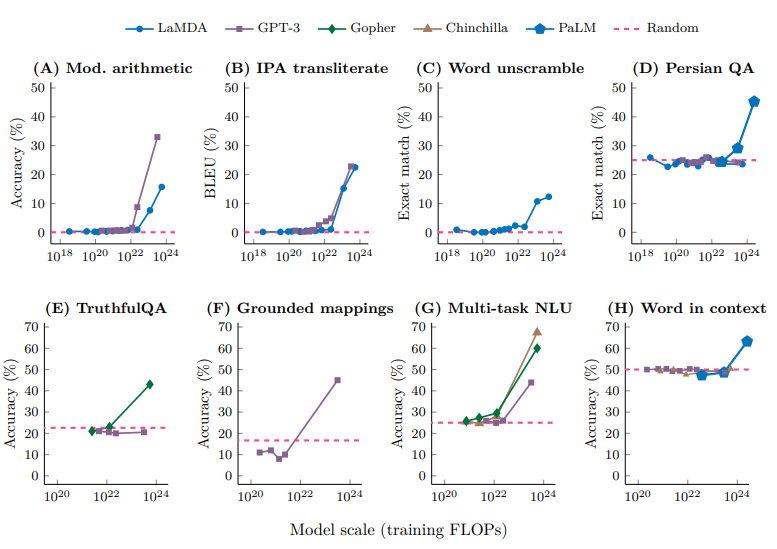
관련 논문: Emergent Abilities of Large Language Models
일부 능력은 모델 scale이 커질 때 갑자기 나타나는 것처럼 보인다. 작은 모델 실험만으로는 이런 현상을 예측하기 어렵다.
이 섹션은 LLM 연구에서 매우 중요한 현실적인 문제를 다룬다.
작은 모델은 실험하기 쉽다. 하지만 작은 모델에서 얻은 직관이 큰 모델로 그대로 전이된다고 보장할 수 없다. 예를 들어 다음과 같은 설계 선택은 scale에 따라 효과가 달라질 수 있다.
-
context length 증가
-
tokenizer vocabulary size 변경
-
MoE routing 방식
-
normalization 방식
-
learning rate schedule
-
data mixture
-
post-training recipe
따라서 CS336은 작은 모델을 실험하되, 그 실험에서 얻을 수 있는 지식의 종류를 구분한다.
5. What can we learn that transfers to frontier models?
강의는 우리가 배울 수 있는 지식을 세 가지로 구분한다.
| 종류 | 의미 | frontier model로 전이되는가? |
|---|---|---|
| Mechanics | Transformer, model parallelism, optimizer, tokenizer 등 작동 원리 | 잘 전이됨 |
| Mindset | 하드웨어를 최대한 활용하고 scale을 진지하게 보는 사고방식 | 잘 전이됨 |
| Intuitions | 어떤 data/modeling decision이 성능을 올리는지에 대한 감 | 부분적으로만 전이됨 |
이 구분이 중요하다. 작은 모델로 frontier model의 모든 직관을 얻을 수는 없다. 하지만 다음은 충분히 배울 수 있다.
-
Transformer forward/backward가 어떻게 계산되는지
-
attention이 왜 메모리 병목을 만드는지
-
optimizer state가 왜 GPU memory를 크게 차지하는지
-
prefill과 decode의 병목이 왜 다른지
-
data filtering이 왜 compute efficiency와 연결되는지
-
scaling law가 왜 큰 모델 학습 전 의사결정에 필요한지
즉, CS336은 “작은 모델로 GPT-4를 재현하자”가 아니다.
더 정확한 목표는 다음이다.
작은 모델과 제한된 compute 안에서,
frontier model을 이해하는 데 필요한 mechanics와 mindset을 익히자.
6. Intuitions: 실험으로만 얻어지는 설계 감각
강의는 일부 설계 결정은 아직 이론적으로 완전히 정당화되지 않았고, 실험에서 나온 경험적 선택이라고 말한다.
예시로 Noam Shazeer의 SwiGLU 관련 논문이 등장한다.

관련 논문: GLU Variants Improve Transformer
SwiGLU는 오늘날 많은 LLM에서 쓰이는 activation/FFN 구조다. 하지만 이 구조가 왜 항상 최선인지에 대한 완전한 이론이 먼저 있었던 것은 아니다. 여러 activation variant를 실험하고, scale이 커졌을 때 잘 되는 방향이 축적되면서 표준적인 선택이 되었다.
이 지점은 LLM 연구의 성격을 잘 보여준다.
-
이론만으로 모든 설계를 결정하기 어렵다.
-
scale이 커지면 작은 차이도 큰 성능 차이를 만든다.
-
많은 선택은 실험적 recipe로 축적된다.
-
하지만 실험적 recipe를 이해하려면 mechanics와 resource accounting이 필요하다.
7. The bitter lesson: scale이 아니라 scalable algorithm이 중요하다
강의는 Rich Sutton의 “bitter lesson”을 언급하며 다음과 같이 정리한다.
Wrong interpretation: scale is all that matters, algorithms don't matter.
Right interpretation: algorithms that scale are what matter.
즉, 단순히 scale만 중요하다는 뜻이 아니다. 중요한 것은 scale을 잘 활용할 수 있는 algorithm이다.
강의는 이를 다음 공식으로 표현한다.
accuracy = efficiency × resources
관련 논문: Measuring the Algorithmic Efficiency of Neural Networks
이 공식은 CS336 전체를 관통하는 핵심 프레임이다.
모델 성능을 높이는 방법은 두 가지다.
- Resources를 늘린다.
-
더 많은 GPU
-
더 많은 학습 시간
-
더 많은 데이터
-
더 큰 모델
- Efficiency를 높인다.
-
같은 compute로 더 좋은 loss를 얻는다.
-
같은 memory로 더 큰 모델을 학습한다.
-
같은 latency로 더 많은 token을 생성한다.
-
같은 token budget으로 더 좋은 data mixture를 구성한다.
기업 frontier lab은 resources를 크게 늘릴 수 있다. 하지만 학계나 일반 연구자는 resources가 제한적이다. 따라서 CS336은 fixed compute and data budget에서 최선의 모델을 만드는 법에 집중한다.
Part II. Current LM Landscape
8. Pre-neural language models: 2010년대 이전
강의는 language model의 역사를 pre-neural 시기부터 시작한다.
- Shannon의 English entropy 연구
Prediction and Entropy of Printed English
- N-gram language model
Language Models in Machine Translation
Language model의 본질은 “다음에 어떤 token이 올 확률이 높은가?”를 모델링하는 것이다. Neural network 이전에는 주로 n-gram이 사용되었다.
예를 들어 trigram model은 다음과 같이 생각한다.
P(w_t | w_1, ..., w_{t-1}) ≈ P(w_t | w_{t-2}, w_{t-1})
즉, 전체 문맥이 아니라 최근 n개 단어만 본다. 이 방식은 단순하고 빠르지만, 긴 문맥을 반영하기 어렵고 sparse data 문제가 크다.
9. Neural ingredients: 2010년대의 핵심 재료
강의는 2010년대에 등장한 신경망 기반 language model의 주요 재료를 나열한다.
| 구성 요소 | 대표 자료 | 의미 |
|---|---|---|
| LSTM | Long Short-Term Memory | 긴 sequence를 RNN으로 처리 |
| Neural LM | A Neural Probabilistic Language Model | 단어 예측을 neural network로 수행 |
| Seq2Seq | Sequence to Sequence Learning | 입력 sequence를 출력 sequence로 변환 |
| Adam | Adam | adaptive optimizer |
| Attention | Bahdanau Attention | 필요한 입력 위치를 동적으로 참조 |
| Transformer | Attention Is All You Need | attention 기반 병렬 sequence model |
| MoE | Outrageously Large Neural Networks | 일부 expert만 활성화하는 sparse model |
| Model parallelism | GPipe, ZeRO, Megatron-LM | 큰 모델을 여러 장치에 나누어 학습 |
현재 LLM은 갑자기 생긴 것이 아니라, 여러 기술이 누적된 결과다. 특히 Transformer가 중요하지만, Transformer 하나만으로 LLM이 완성된 것은 아니다.
실제로 대규모 LLM에는 다음이 모두 필요하다.
-
sequence를 잘 표현하는 architecture
-
안정적으로 학습시키는 optimizer
-
대규모 데이터를 처리하는 tokenizer/data pipeline
-
수천 GPU에서 학습 가능한 parallelism
-
학습 후 모델을 사용자 요구에 맞추는 alignment
즉, LLM은 단일 알고리즘이라기보다 architecture + optimization + systems + data + post-training의 결합물이다.
10. Early foundation models: late 2010s
강의는 early foundation model로 ELMo, BERT, T5를 소개한다.
-
ELMo: LSTM 기반 pretraining, downstream fine-tuning 개선
-
BERT: Transformer 기반 pretraining, fine-tuning paradigm 확산
-
T5: 모든 task를 text-to-text로 변환
이 시기의 핵심은 pretrain then fine-tune이다.
BERT는 특히 NLP 연구 방식 자체를 바꿨다. 이전에는 task별 모델을 따로 설계하는 경우가 많았지만, BERT 이후에는 대규모 말뭉치로 pretraining한 뒤 downstream task에 fine-tuning하는 방식이 표준이 되었다.
하지만 이 시기의 모델은 오늘날 ChatGPT식 모델과는 다르다. BERT는 주로 encoder-only 구조이며, 사용자는 모델과 “대화”하기보다 특정 task에 맞게 fine-tuning했다.
11. Embracing scaling
강의는 본격적인 scaling 흐름을 다음과 같이 설명한다.
-
GPT-2: fluent text generation과 zero-shot 가능성
-
Scaling laws: scale이 성능을 예측 가능하게 만든다는 희망 제공
-
GPT-3: 175B parameter, in-context learning
-
PaLM: 540B parameter, massive scale, undertrained
-
Chinchilla: compute-optimal scaling laws
이 흐름에서 중요한 전환은 in-context learning이다. GPT-3 이후 language model은 단순히 fine-tuning하는 대상이 아니라, prompt 안에 예시를 넣어 task를 수행하게 하는 general-purpose system처럼 사용되기 시작했다.
또 하나의 핵심은 scaling laws다. Scaling laws는 모델 크기, 데이터 크기, compute 사이의 관계를 정량화하려는 시도다. 예를 들어 compute budget이 정해졌을 때 다음 질문을 던진다.
더 큰 모델을 적은 데이터로 학습할 것인가?
아니면 더 작은 모델을 더 많은 데이터로 학습할 것인가?
Chinchilla는 기존 모델들이 너무 큰 모델을 너무 적은 token으로 학습하는 경향이 있었고, compute-optimal 관점에서는 더 많은 token을 학습하는 것이 중요하다고 주장했다.
12. Open models
강의는 open model의 흐름을 세 단계로 나눈다.
12.1 Early attempts: GPT-3 replication 시도
-
EleutherAI: The Pile dataset과 GPT-J
-
Meta OPT 175B: GPT-3 replication, 많은 hardware issue
-
Hugging Face / BigScience BLOOM 176B: data sourcing에 초점
초기 open model은 “GPT-3 같은 모델을 공개적으로 재현할 수 있는가?”에 가까웠다. 성능이 frontier closed model과 완전히 같지는 않았지만, 이 시도들은 매우 중요했다.
왜냐하면 처음으로 다음이 공개되었기 때문이다.
-
대규모 데이터셋 구성
-
학습 중 발생한 hardware failure
-
distributed training의 현실적 어려움
-
모델 weight와 paper
-
community 기반 재현 가능성
OPT 논문은 특히 대규모 학습에서 hardware failure가 얼마나 자주 발생하는지 보여주는 자료로도 중요하다.
12.2 Credible open-weight models: weights + paper
-
Meta Llama models
-
Mistral models
-
DeepSeek models
DeepSeek 67B, DeepSeek-V2 / MLA, DeepSeek-V3, DeepSeek-R1, DeepSeek-V3.2
-
Alibaba Qwen models
-
Moonshot Kimi models
-
Z.ai GLM models
-
MiniMax models
-
Xiaomi MIMO models
강의는 이 모델들이 GPT, Claude, Gemini 같은 closed model에 점점 가까워지고 있다고 설명한다.
open-weight model은 weight는 공개하지만, 학습 데이터와 전체 pipeline이 완전히 공개되지는 않는 경우가 많다. 그래도 연구자에게는 매우 큰 의미가 있다.
-
직접 inference 가능
-
fine-tuning 가능
-
activation 분석 가능
-
alignment 실험 가능
-
serving system 연구 가능
-
tokenizer/model architecture 비교 가능
예를 들어 Llama 계열은 open LLM 생태계의 기준점이 되었고, Mistral은 작은 모델에서도 strong performance를 보여주었다. DeepSeek은 MLA, MoE, RL 계열 post-training 등에서 큰 영향을 주었다. Qwen은 multilingual/code/reasoning 계열에서 중요한 open-weight model family로 자리잡았다.
12.3 Open-source models: weights + paper + code + data
-
AI2 OLMo models
-
NVIDIA Nemotron models
-
Marin models, open development
관련 논의: Openness is important for trust and innovation
여기서 open-source의 의미는 단순히 weight 공개가 아니다.
open-weight: weight와 paper 중심
open-source: weight + paper + code + data + training recipe에 가까움
CS336에서 open model이 중요한 이유는 명확하다.
공개된 모델과 recipe가 있어야 수업에서 실제로 가르칠 수 있다.
프론티어 closed model은 성능은 뛰어나지만, 내부가 공개되지 않기 때문에 교육과 연구 재현성에는 한계가 있다. 반대로 open model은 실험하고, 분석하고, 고치고, 재현할 수 있다.
13. What is a language model?
강의는 “language model이 무엇인가?”라는 질문의 답이 시대에 따라 달라졌다고 설명한다.
| 시기 | language model의 의미 |
|---|---|
| 2018년, BERT | fine-tune하는 대상 |
| 2020년, GPT-3 | prompt하는 대상 |
| 2022년, ChatGPT | 대화하는 대상 |
| 2026년, agents | 자율적으로 행동하는 대상 |
예시 링크:
강의의 핵심 문장은 다음이다.
The fundamentals are the same: attention, kernels, optimization.
The specs are different: longer context, inference efficiency matters even more.
Language model의 interface는 계속 바뀌었다.
-
BERT 시대: 분류기 위에 붙여 fine-tuning
-
GPT-3 시대: prompt로 task를 지정
-
ChatGPT 시대: multi-turn conversation
-
Agent 시대: tool use, browser, code execution, long-horizon planning
하지만 내부의 핵심 문제는 크게 바뀌지 않았다.
-
attention을 어떻게 효율적으로 계산할 것인가?
-
긴 context를 어떻게 처리할 것인가?
-
inference latency를 어떻게 줄일 것인가?
-
optimizer와 data mixture를 어떻게 설정할 것인가?
-
model output을 어떻게 human preference에 맞출 것인가?
따라서 CS336은 최신 agent framework 자체보다 그 아래의 fundamentals를 다룬다.
Part III. Executable Lecture and Logistics
14. What is this program?
이 강의는 executable lecture다. 즉, Python 프로그램의 실행이 강의 내용을 생성한다.
Executable lecture의 장점은 다음과 같다. (사실 난 잘 모르겠다. 오히려 가독성 떨어지는것 같은데;;)
-
모든 것이 code이므로 직접 실행하고 확인할 수 있다.
-
강의의 계층 구조를 볼 수 있다.
-
특정 개념이나 함수 정의로 이동할 수 있다.
-
예시 코드의 변수 값을 inspection할 수 있다.
이 구조는 CS336의 철학과 잘 맞는다. 이 강의는 슬라이드를 보는 수업이 아니라, 실행 가능한 프로그램을 따라가며 시스템을 이해하는 수업이다.
특히 LLM 시스템에서는 “개념을 안다”와 “코드로 구현할 수 있다” 사이의 차이가 크다. 예를 들어 AdamW를 수식으로 아는 것과 실제로 optimizer state를 관리하면서 구현하는 것은 다르다.
Executable lecture는 그 차이를 줄이려는 시도다. (흠…?)
15. Course logistics
공식 사이트:
How you can follow along at home
-
모든 lecture material과 assignment는 온라인에 공개된다.
-
Stanford 수강생이 아니어도 공개된 자료를 따라가며 self-study할 수 있다.
-
강의 녹화는 CGOE를 통해 이루어진다.
Assignments 운영 방식
-
총 5개 assignment로 구성된다: basics, systems, scaling laws, data, alignment.
-
scaffolding code는 거의 없지만, correctness 확인을 위한 unit test와 adapter interface가 제공된다.
-
로컬에서 correctness를 먼저 확인한 뒤, cluster에서 accuracy와 speed benchmark를 수행하는 흐름이다.
-
일부 과제에는 leaderboard가 있으며, 정해진 training budget 안에서 perplexity 또는 loss를 최소화하는 식으로 평가된다.
강의는 5-unit class이며, 과제 workload가 매우 큰 수업이라고 설명한다.
강의에서 인용한 Spring 2024 평가:
The entire assignment was approximately the same amount of work as all 5 assignments from CS 224n plus the final project. And that’s just the first homework assignment.
Why you should take this course
-
어떻게 작동하는지 집요하게 이해하고 싶다.
-
research engineering muscle을 키우고 싶다.
Why you should not take this course
-
이번 quarter에 실제 연구 성과를 내는 것이 더 중요하다.
-
multimodality, RAG 같은 최신 유행 기술 자체를 배우고 싶다.
-
자신의 application domain에서 바로 좋은 결과를 내고 싶다.
AI policy
-
Coding agent는 과제를 풀 수 있지만, 그러면 아무것도 배우지 못한다.
-
AI는 질문 답변과 tutoring에는 유용하게 쓸 수 있다.
-
제공된
AGENTS.md를 사용해야 하며, AI가 pedagogically-minded하게 답하도록 요구한다.
Compute
-
Modal이 compute를 제공한다.
이 부분은 수업의 성격을 명확히 한다. CS336은 단순히 “LLM 개념 강의”가 아니다. 구현량이 매우 많고, 효율성과 시스템 감각을 훈련하는 수업이다.
특히 “AI를 쓰지 말라”가 아니라 “AI를 사용하되 학습을 대체하지 말라”는 policy가 중요하다. LLM 시대의 CS 교육에서 매우 현실적인 지점이다.
Part IV. Course Syllabus Overview
16. 전체 syllabus의 큰 그림
강의는 수업 전체를 다섯 개 assignment로 나눈다.
나는 이 과제들을 모두 진행해 보려고 한다..!
| Assignment | 주제 | 핵심 질문 |
|---|---|---|
| Assignment 1 | Basics | 기본 language model을 직접 학습할 수 있는가? |
| Assignment 2 | Systems | GPU/TPU를 최대한 효율적으로 사용할 수 있는가? |
| Assignment 3 | Scaling laws | 작은 실험으로 큰 실험의 성능을 예측할 수 있는가? |
| Assignment 4 | Data | 좋은 data를 어떻게 만들고 섞을 것인가? |
| Assignment 5 | Alignment | weak supervision으로 모델을 어떻게 개선할 것인가? |
강의는 다시 efficiency를 강조한다.
- Resources = data + hardware
- Hardware = compute + memory + communication bandwidth
그리고 핵심 질문은 다음이다.
How do you train the best model given a fixed set of resources?
CS336은 LLM을 단순히 모델 구조 하나로 보지 않는다. LLM을 다음의 resource optimization problem으로 본다.
제한된 데이터와 제한된 하드웨어가 있을 때, 가장 좋은 모델을 어떻게 만들 것인가?
이 관점에서 수업의 모든 주제가 연결된다.
-
Systems는 명백히 efficiency 문제다.
-
Tokenization은 raw byte를 그대로 쓰면 sequence length가 길어져 compute-inefficient하다는 문제와 연결된다.
-
Architecture 변화는 memory 또는 FLOPs를 줄이기 위해 등장한다.
-
Data filtering은 나쁜 데이터에 compute를 낭비하지 않기 위한 것이다.
-
Scaling laws는 큰 모델을 직접 학습하기 전, 작은 모델로 hyperparameter를 추정하기 위한 것이다.
17. Assignment 1: Basics
Goal
기본 language model을 직접 학습할 수 있어야 한다.
Components
-
Tokenization
-
Model architecture
-
Training
17.1 Tokenization
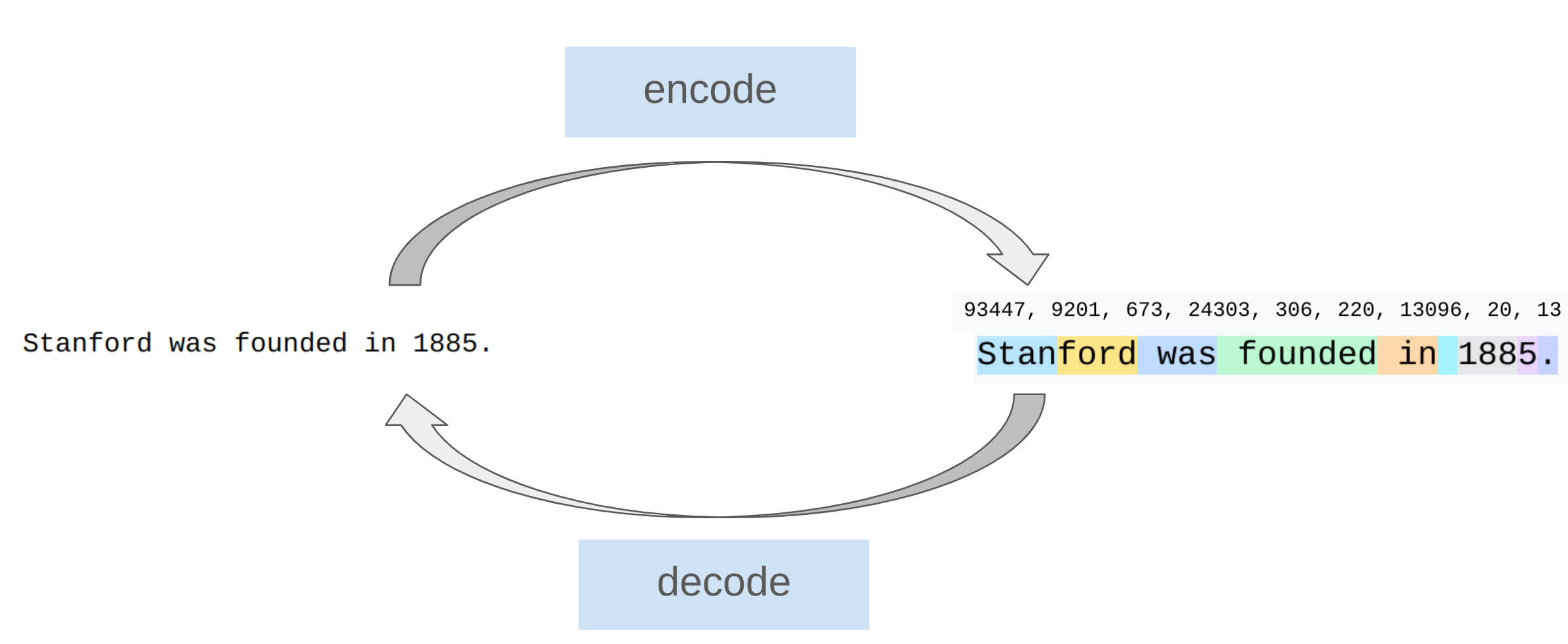
Tokenizer는 raw input, 즉 bytes/string을 integer token sequence로 변환한다.
raw text / bytes ↔ token ids
대표적인 tokenizer는 Byte-Pair Encoding, BPE다.
BPE의 직관은 입력을 자주 등장하는 chunk로 나누는 것이다.
모델은 문자열을 직접 처리하지 않는다. Transformer의 embedding layer는 integer id를 입력으로 받는다. 따라서 text를 integer sequence로 바꾸는 tokenizer가 필요하다.
Tokenizer는 단순 전처리 같지만 실제로는 모델 효율에 큰 영향을 준다.
예를 들어 같은 문장을 다음처럼 표현할 수 있다.
byte 단위: 길이가 김, vocabulary 작음
word 단위: 길이가 짧음, vocabulary 큼
BPE 단위: 중간 지점, 자주 등장하는 문자열은 하나의 token으로 압축
강의는 tokenization을 efficiency lens로 본다.
-
1000 bytes를 약 250 tokens로 줄이면 attention 비용이 크게 줄어든다.
-
token 단위가 의미 있는 chunk가 되면 모델 capacity를 더 중요한 부분에 쓸 수 있다.
다만 tokenizer-free model이라는 꿈도 있다.
하지만 강의는 이 방식들이 아직 frontier scale까지 충분히 확장되지는 않았다고 설명한다.
17.2 Model architecture
출발점은 original Transformer다.
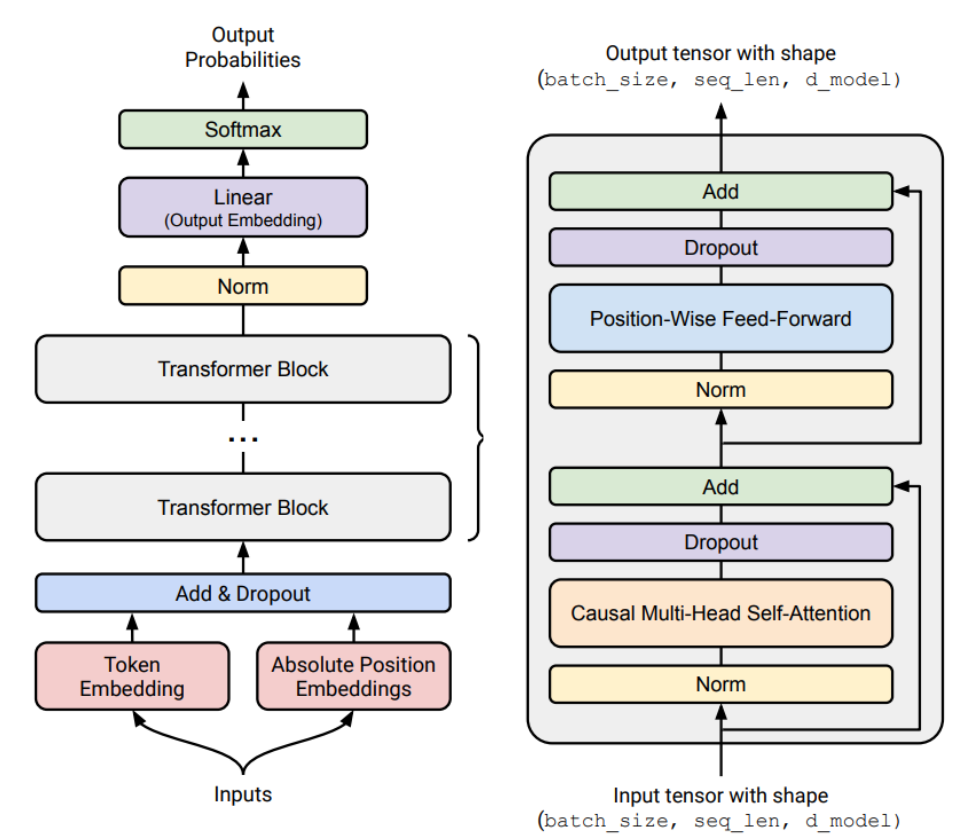
강의는 Transformer 이후의 refinement를 다음처럼 나열한다.
| 영역 | 예시 | 링크 |
|---|---|---|
| Activation | ReLU, SwiGLU | SwiGLU |
| Positional encoding | sinusoidal, RoPE | RoPE |
| Normalization | LayerNorm, RMSNorm, QK norm, pre/post norm | LayerNorm, RMSNorm, QK norm, pre/post norm |
| Attention | full, sparse/local, GQA, MLA | Sparse Transformer, GQA, MLA |
| State-space / recurrence | Mamba, Gated DeltaNet | Linear Attention, Mamba-2, Gated DeltaNet, Mamba-3 |
| MLP | dense, MoE | MoE, Switch Transformer |
이 부분은 앞으로 강의에서 다룰 architecture design space를 미리 보여준다.
Transformer는 기본 틀이지만, 실제 LLM은 순수한 2017 Transformer 그대로가 아니다. 예를 들어 최근 모델들은 다음과 같은 변화를 갖는다.
-
LayerNorm 대신 RMSNorm 사용
-
absolute positional embedding 대신 RoPE 사용
-
full attention 대신 GQA/MLA/sliding window attention 사용
-
dense MLP 대신 MoE 사용
-
ReLU 대신 SwiGLU 계열 사용
이 변화들은 대부분 성능만을 위한 것이 아니라 효율성과 관련된다.
예를 들어 GQA는 KV cache 크기를 줄여 inference memory bandwidth 부담을 줄인다. MoE는 전체 parameter 수를 키우면서도 token당 활성화되는 parameter 수를 제한한다. Sliding window attention은 long context에서 attention 비용을 줄인다.
17.3 Training
Training은 모델 parameter를 어떻게 설정할 것인가의 문제다.
강의는 다음 항목을 언급한다.
| 항목 | 예시 | 링크 |
|---|---|---|
| Loss function | Multi-token prediction | MTP, DeepSeek-V3 |
| Optimizer | AdamW, SOAP, Muon | Adam, AdamW, SOAP, Muon |
| Initialization | Xavier, muP | Xavier init, muP |
| LR schedule | cosine, WSD | Cosine LR, WSD |
| Regularization | dropout, weight decay | - |
| Batch size | critical batch size | Large batch training |
| MoE-specific | load balancing, aux-free | Aux-free load balancing, DeepSeek-V3 |
Training은 단순히 loss.backward()와 optimizer.step()을 호출하는 문제가 아니다. 큰 모델에서는 다음이 모두 민감하다.
-
initialization scale이 잘못되면 activation/gradient norm이 불안정해진다.
-
learning rate가 너무 크면 발산하고, 너무 작으면 compute를 낭비한다.
-
batch size가 커질수록 throughput은 좋아질 수 있지만 generalization이나 optimization dynamics가 달라진다.
-
MoE에서는 expert load balancing이 안 되면 일부 expert만 사용되고 나머지는 죽는다.
즉 training은 expressivity, stability, efficiency의 균형 문제다.
17.4 Assignment 1 links
Assignment 1에서 하는 일:
-
BPE tokenizer 구현
-
Transformer 구현
-
cross-entropy loss 구현
-
AdamW optimizer 구현
-
training loop 구현
-
resource accounting 수행
-
TinyStories와 OpenWebText에서 학습
-
B200에서 45분 안에 OpenWebText perplexity 최소화
강의의 high-level principle:
Expressivity: 데이터의 복잡한 의존성을 표현할 수 있는가?
Stability: parameter/gradient norm을 적절한 범위에 유지하는가?
Efficiency: 학습과 추론이 하드웨어에서 빠르게 실행되는가?
18. Assignment 2: Systems
Goal
GPU 또는 TPU 같은 하드웨어를 최대한 효율적으로 사용한다.
Components
-
Kernels
-
Parallelism
-
Inference
18.1 Resource accounting
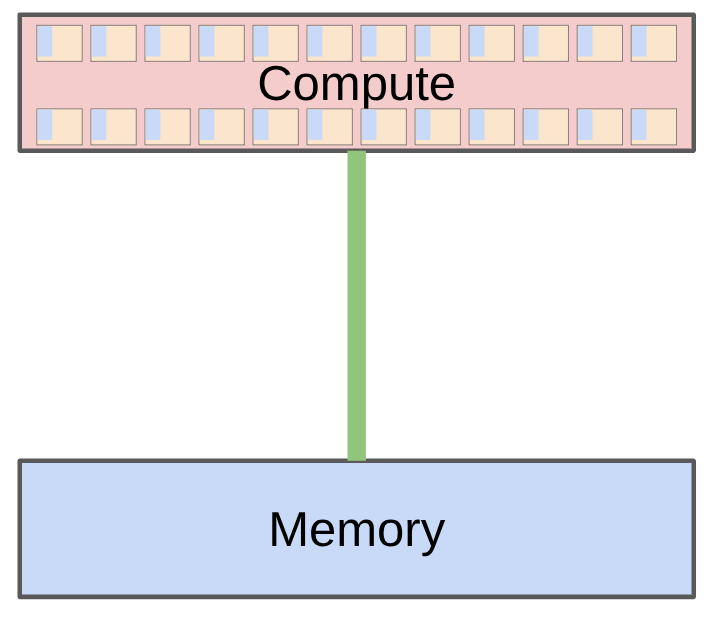
강의는 systems의 첫 번째 주제로 resource accounting을 제시한다.
예시 계산:
Training 70B parameters on 1T tokens
Total FLOPs = 6 × 70e9 × 1e12 = 4.2e23 FLOPs
모델 parameter는 GPU memory, 즉 HBM에서 compute unit인 SM으로 이동해야 한다.
강의에서 언급하는 B200 예시:
B200: 2.25 PFLOP/sec bf16 compute, 8 TB/sec memory bandwidth
관련 이미지:
Resource accounting은 “내 모델이 얼마나 비싼가?”를 계산하는 것이다. 여기서 중요한 것은 compute와 memory가 서로 다른 병목이라는 점이다.
-
Compute-bound: 연산량이 병목이다.
-
Memory-bound: 데이터를 memory에서 읽고 쓰는 속도가 병목이다.
LLM training의 큰 matmul은 compute-bound에 가까운 경우가 많지만, inference decode처럼 batch가 작고 KV cache를 계속 읽는 작업은 memory-bound가 되기 쉽다.
Roofline analysis는 이 차이를 정량적으로 보는 도구다. 어떤 연산이 compute peak에 의해 제한되는지, memory bandwidth에 의해 제한되는지 판단한다.
18.2 Kernels
Kernel은 GPU에서 실행되는 함수다. PyTorch에서 primitive operation을 호출하면 일반적으로 표준 kernel이 launch된다.
강의는 custom kernel을 작성하는 이유를 다음 원칙으로 설명한다.
Organize computation to minimize data movement.
Naive 방식:
read HBM → compute A → write HBM → read HBM → compute B → write HBM
Fused 방식:
read HBM → compute A and B → write HBM
대표 전략:
-
operator fusion
-
tiling
-
FlashAttention
-
memory coalescing
-
bank conflict 회피
-
occupancy 개선
-
CUDA / Triton / CUTLASS / ThunderKittens
GPU 연산 최적화에서 중요한 것은 FLOPs만이 아니다. 실제로는 memory movement가 큰 병목이 된다.
예를 들어 RMSNorm, activation, dropout, residual add 같은 연산을 각각 따로 실행하면 매번 HBM에 읽고 쓰는 비용이 발생한다. 이를 하나의 fused kernel로 합치면 memory traffic이 줄어든다.
FlashAttention도 비슷한 철학이다. Attention 계산을 수학적으로 바꾸는 것이 아니라, attention matrix 전체를 HBM에 저장하지 않도록 계산 순서를 바꿔 memory I/O를 줄인다.
18.3 Parallelism
강의는 1024 GPU를 사용할 때를 생각해보라고 한다.
GPU 간 데이터 이동은 GPU 내부 HBM 접근보다 훨씬 느리다. 따라서 multi-GPU에서도 동일한 원칙이 적용된다.
Minimize data movement.
주요 개념:
-
gather
-
reduce
-
all-reduce
-
parameter sharding
-
activation sharding
-
gradient sharding
-
optimizer state sharding
-
data parallelism
-
tensor parallelism
-
pipeline parallelism
-
sequence parallelism
-
expert parallelism
모델이 한 GPU에 들어가지 않거나, 학습 시간이 너무 길면 여러 GPU를 사용해야 한다. 하지만 GPU를 많이 쓴다고 자동으로 빨라지지는 않는다.
GPU 병렬화의 핵심 trade-off는 다음이다.
연산을 나누면 각 GPU의 부담은 줄지만,
GPU 간 통신이 늘어난다.
따라서 어떤 parallelism을 사용할지는 모델 구조, batch size, sequence length, interconnect bandwidth에 따라 달라진다.
18.4 Inference: prefill and decode
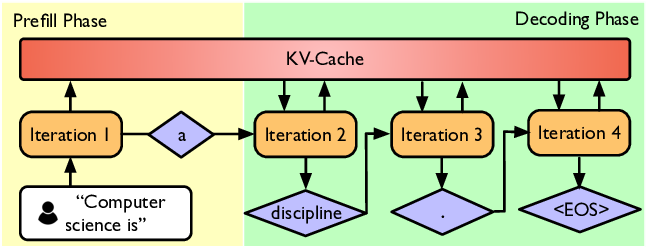
Inference의 목표는 prompt가 주어졌을 때 token을 생성하는 것이다. 이는 모델 serving뿐 아니라 reinforcement learning, test-time compute, evaluation에도 필요하다.
강의는 inference를 두 단계로 나눈다.
1. Prefill
2. Decode
Prefill
Prefill은 prompt tokens가 모두 주어진 상태에서 전체 prompt를 한 번에 처리하는 단계다.
prompt 전체 forward
→ 각 layer의 key/value 계산
→ KV cache 생성
→ 첫 번째 next token 준비
Prefill은 training과 비슷하게 많은 token을 병렬로 처리할 수 있으므로 대체로 compute-bound 성격이 강하다.
Decode
Decode는 token을 하나씩 생성하는 단계다.
이전 KV cache를 읽음
새 token 하나를 입력
다음 token 하나를 예측
이 과정을 반복
Decode는 매 step마다 KV cache를 읽어야 하고, 한 번에 처리하는 token 수가 작기 때문에 memory-bound가 되기 쉽다.
Prefill과 decode를 구분하는 것은 LLM serving에서 매우 중요하다.
긴 prompt를 넣으면 prefill 비용이 커진다. 긴 답변을 생성하면 decode 비용이 커진다. 그런데 두 비용의 성격이 다르다.
| 단계 | 처리 방식 | 병목 | 특징 |
|---|---|---|---|
| Prefill | prompt 전체 병렬 처리 | compute | GPU matmul 활용도가 높음 |
| Decode | token-by-token 생성 | memory bandwidth | KV cache 읽기가 병목 |
따라서 serving system은 두 단계를 다르게 최적화한다.
-
continuous batching
-
paged attention
-
fused kernels
-
KV cache management
-
speculative decoding
-
quantization
-
distillation
Speculative decoding은 작은 draft model이 여러 token을 먼저 제안하고, 큰 model이 이를 병렬로 검증하는 방식이다. 정확한 decoding 결과를 유지하면서 latency를 줄일 수 있다.
18.5 Assignment 2 links
Assignment 2에서 하는 일:
-
Triton으로 fused RMSNorm kernel 구현
-
distributed data parallel training 구현
-
optimizer state sharding 구현
-
benchmark와 profiling 수행
19. Assignment 3: Scaling laws
강의는 다음 상황을 제시한다.
1e25 FLOPs의 compute가 있다면,
좋은 모델을 학습하기 위해 어떤 hyperparameter를 써야 하는가?
문제는 full scale에서 hyperparameter tuning을 하기에는 너무 비싸다는 것이다.
따라서 scaling law의 핵심 전환은 다음이다.
단일 scale에서 hyperparameter를 고르는 것이 아니라,
FLOPs → hyperparameters로 이어지는 scaling recipe를 설계한다.
방법:
-
작은 scale에서 여러 실험을 수행한다.
-
각 실험의 loss를 측정한다.
-
scaling law를 fit한다.
-
target scale의 loss와 hyperparameter를 예측한다.
관련 개념:
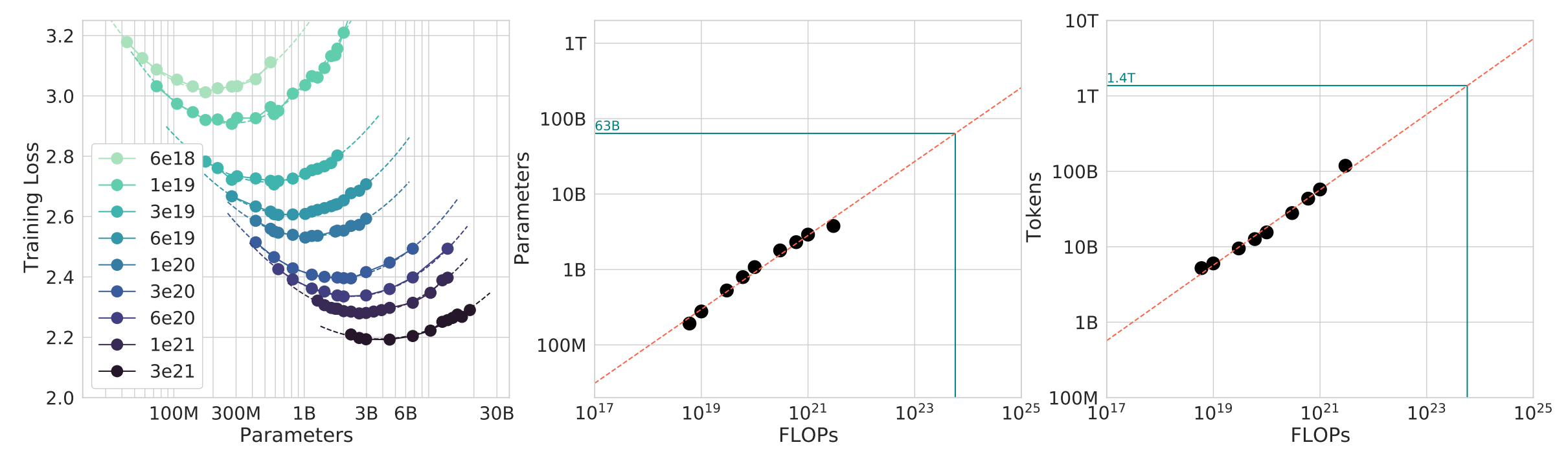
강의의 TL;DR:
D = 20N 정도가 rough하게 compute-optimal하다. 예: 70B parameter model은 약 1.4T tokens로 학습하는 것이 적절하다.
단, inference cost까지 고려하면 더 작은 모델을 더 오래 학습하는 쪽이 유리할 수 있다.
Marin 관련 live example:

중요한 것은 scaling law가 자동으로 생기지 않는다는 점이다. 좋은 scaling law를 얻으려면 다음이 필요하다.
-
작은 scale 실험도 충분히 잘 학습되어야 한다.
-
learning rate와 schedule이 scale별로 적절해야 한다.
-
architecture와 data distribution이 target scale과 일관되어야 한다.
-
hyperparameter transfer가 가능하도록 parameterization을 설계해야 한다.
강의는 “optimality만큼 predictability가 중요하다”고 말한다. 실제 대규모 학습에서는 약간 최적이 아니더라도 예측 가능한 recipe가 매우 중요하다.
Assignment 3 links
Assignment 3에서 하는 일:
-
training API를 사용해 hyperparameters → loss 관계 관찰
-
FLOPs budget 안에서 training jobs 제출
-
data points를 모아 scaling laws fit
-
extrapolated hyperparameters와 loss prediction 제출
-
leaderboard에서 FLOPs budget 내 loss 최소화
20. Assignment 4: Data
강의는 다음 질문을 던진다.
What capabilities do we want the model to have?
예시:
-
Multilingual capability
-
Conversation quality
-
Agentic coding capability
20.1 Evaluation
Evaluation의 목적은 두 가지다.
- Internal evaluation
-
model development를 가이드한다.
-
scale 간 smoothness와 relative performance가 중요하다.
- External evaluation
-
실제 use case의 absolute quality를 측정한다.
-
ecological validity가 중요하다.
예시 evaluation:
-
Perplexity
-
GPQA
-
HLE
-
SWE-Bench
-
Terminal-Bench
Evaluation은 단순히 benchmark 점수를 얻기 위한 것이 아니다. Internal eval은 개발 과정에서 의사결정을 돕는 계기판이고, external eval은 실제 사용자 가치와 연결되는 평가다.
예를 들어 perplexity는 모델이 text distribution을 얼마나 잘 예측하는지 보여주지만, coding agent 성능을 직접 보장하지는 않는다. 반대로 SWE-Bench는 agentic coding에 가까운 평가지만 비용이 크고 noisy할 수 있다.
20.2 Data curation
강의는 데이터가 하늘에서 떨어지지 않는다고 말한다.
데이터 source:
-
webpages crawled from Internet
-
books
-
arXiv papers
-
GitHub code
-
etc.
The Pile 관련 이미지:
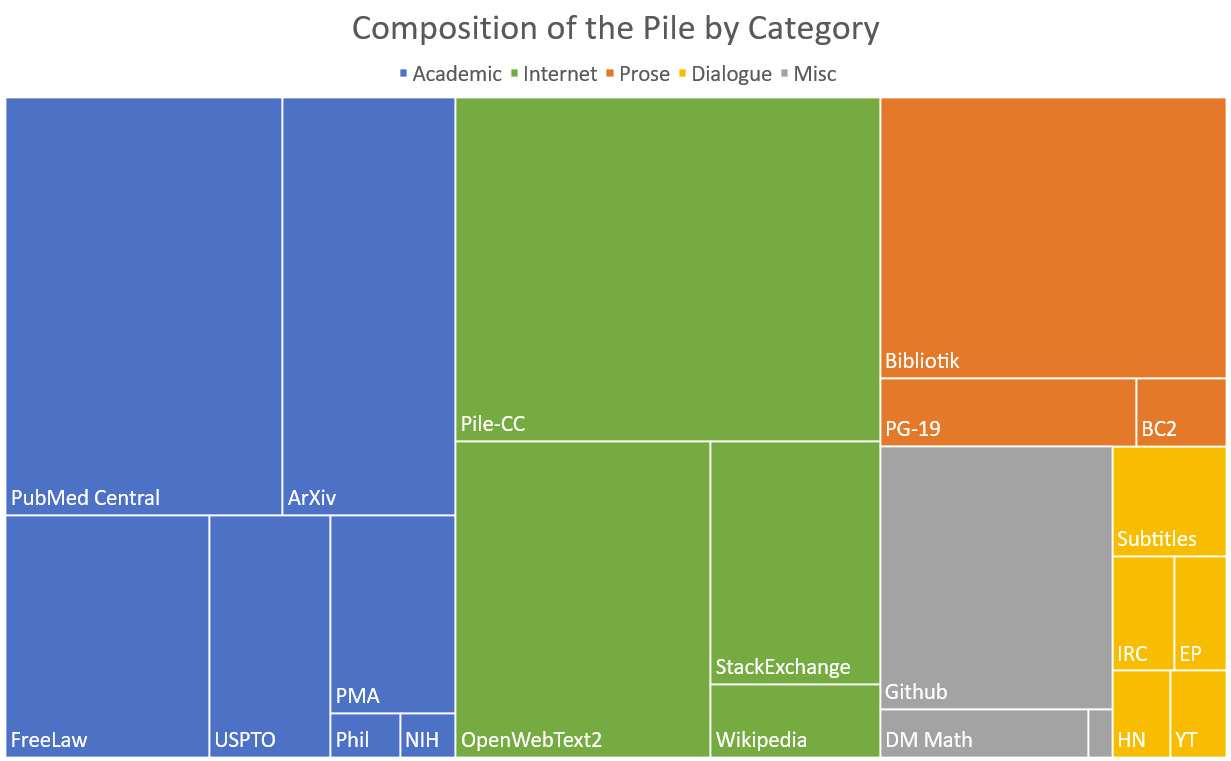
관련 링크:
LLM 데이터는 단순한 텍스트 파일이 아니다. 원본 데이터는 HTML, PDF, code repository, forum dump, book scan 등 다양한 형태로 존재한다.
따라서 data curation은 다음 문제를 포함한다.
-
HTML에서 main content만 추출하기
-
PDF에서 깨끗한 text 뽑기
-
boilerplate 제거
-
중복 제거
-
저품질/유해 데이터 필터링
-
domain mixture 조정
-
copyright/license 고려
20.3 Data processing
강의가 제시하는 data processing 항목:
-
Transformation: HTML/PDF를 text로 변환
-
Filtering: 고품질 데이터 유지, harmful content 제거
-
Deduplication: compute 절약, memorization 방지
-
Data mixing: source별 upweight/downweight 결정
-
Rewriting / synthetic data: LM으로 real data를 downstream task와 더 비슷하게 변형
관련 링크:
데이터 유형:
-
Pretraining data: 크고 다양함
-
Mid-training data: 고품질, long-context 포함
-
Post-training data: supervised fine-tuning, conversations, tool-calling agentic traces
데이터는 모델 성능의 핵심이지만, 단순히 많이 모으면 되는 것이 아니다. 나쁜 데이터에 학습 compute를 쓰면 모델이 나빠질 뿐 아니라 비싼 GPU 시간을 낭비한다.
따라서 data filtering은 단순한 품질 관리가 아니라 compute efficiency 문제다.
좋은 token에 gradient update를 써야 한다.
나쁜 token에 compute를 쓰면 모델도 나빠지고 비용도 낭비된다.
Assignment 4 links
Assignment 4에서 하는 일:
-
Common Crawl HTML을 text로 변환
-
quality/harmful content classifier 학습
-
MinHash 기반 deduplication
-
token budget 내 perplexity 최소화
21. Assignment 5: Alignment
강의는 지금까지의 모델 학습을 full supervision으로 본다.
Predict the next token.
그 다음 단계는 weak supervision을 통해 모델을 개선하는 것이다.
왜 weak supervision이 필요한가?
정답을 직접 생성하는 것보다 critique하는 것이 더 쉬운 경우가 많기 때문이다.
기본 template:
-
모델에서 response를 생성한다.
-
human, verifier, LM judge가 response를 score한다.
-
더 좋은 response를 선호하도록 모델을 업데이트한다.
관련 알고리즘:
-
PPO
-
DPO
-
GRPO
Alignment는 모델을 단순 next-token predictor에서 사용자에게 유용한 assistant로 바꾸는 과정이다.
Pretraining은 인터넷 텍스트 분포를 모방하게 만든다. 하지만 사용자는 인터넷 텍스트 continuation을 원하는 것이 아니라, helpful하고 harmless하며 instruction-following을 잘하는 답변을 원한다.
따라서 post-training에서는 preference data나 reward signal을 이용한다.
하지만 강의는 alignment의 어려움도 강조한다.
-
RL algorithm은 불안정하고 tuning이 어렵다.
-
scale이 커지면 inference rollout infrastructure가 필요하다.
-
systems efficiency와 on-policyness 사이의 trade-off가 생긴다.
예를 들어 GRPO나 PPO를 대규모로 하려면 모델이 계속 response를 생성해야 하고, 생성된 response를 평가해야 하며, 그 결과를 다시 학습에 반영해야 한다. 이때 inference system과 training system이 결합된다.
Assignment 5 links
Assignment 5에서 하는 일:
-
DPO 구현
-
GRPO 구현
Part V. Tokenization
22. Tokenization unit intro
강의는 tokenization unit이 Andrej Karpathy의 tokenization video에서 영감을 받았다고 말한다.
이제 본격적으로 tokenization을 다룬다.
강의의 기본 정의:
Tokenizer: strings ↔ tokens(indices)
즉 tokenizer는 문자열을 integer id sequence로 encode하고, integer id sequence를 다시 문자열로 decode한다.
23. Intro to tokenization
Raw text는 일반적으로 Unicode string으로 표현된다.
예시 문자열:
Hello, ! 你好!
Language model은 token sequence 위에 probability distribution을 둔다. 이 token은 보통 integer index로 표현된다.
예시:
indices = [15496, 11, 995, 0]
따라서 필요한 것은 두 가지다.
encode: string → token ids
decode: token ids → string
강의에서는 Tokenizer라는 abstract interface를 둔다.
class Tokenizer:
def encode(self, string: str) -> list[int]:
raise NotImplementedError
def decode(self, indices: list[int]) -> str:
raise NotImplementedError
Tokenizer의 가장 중요한 조건은 round-trip 가능성이다.
decode(encode(x)) == x
즉 문자열을 token으로 바꿨다가 다시 문자열로 복원했을 때 원문이 유지되어야 한다.
Tokenizer는 모델 앞단의 단순 부품처럼 보이지만, 실제로는 다음에 영향을 준다.
-
sequence length
-
vocabulary size
-
embedding matrix 크기
-
attention cost
-
rare word 처리
-
multilingual 처리
-
code 처리
-
whitespace 처리
-
special token 처리
-
perplexity 계산
24. Tokenization examples: GPT-style tokenizer 관찰
강의는 tokenizer를 감각적으로 이해하기 위해 interactive site를 보라고 한다.
관찰 포인트:
- 단어와 앞 공백이 같은 token에 포함될 수 있다.
- 예:
" world"
- 문장 시작의 단어와 중간의 단어가 다르게 표현될 수 있다.
- 예:
"hello hello"
- 숫자는 몇 자리 단위로 쪼개져 tokenization될 수 있다.
강의는 OpenAI의 GPT-5 tokenizer로 tiktoken의 o200k_base encoding을 사용한다.
tokenizer = tiktoken.get_encoding("o200k_base")
Compression ratio 정의:
compression ratio = UTF-8 byte 수 / token 수
compression ratio가 클수록 같은 문자열을 더 적은 token으로 표현한다는 뜻이다.
왜 compression ratio가 중요한가?
Transformer attention은 sequence length에 대해 비용이 크게 증가한다. 특히 full attention의 attention matrix는 대략 sequence length의 제곱에 비례한다.
sequence length가 길어질수록 attention 비용이 급격히 증가한다.
따라서 tokenizer가 동일한 text를 더 짧은 token sequence로 표현하면 학습과 추론이 모두 효율적이다.
하지만 vocabulary size를 무작정 키워 compression ratio를 높이면 다른 문제가 생긴다.
-
embedding matrix가 커진다.
-
output softmax가 커진다.
-
rare token이 늘어난다.
-
각 token의 학습 빈도가 줄어 sparsity 문제가 생긴다.
즉 tokenizer는 다음 trade-off를 가진다.
짧은 sequence length ↔ 큰 vocabulary / sparse learning
25. Character tokenizer
Character tokenizer는 Unicode string을 Unicode code point sequence로 표현한다.
예:
ord("a") == 97
chr(97) == "a"
즉 encode는 각 character에 ord를 적용하고, decode는 각 integer에 chr를 적용한다.
class CharacterTokenizer(Tokenizer):
def encode(self, string: str) -> list[int]:
return list(map(ord, string))
def decode(self, indices: list[int]) -> str:
return "".join(map(chr, indices))
강의는 Unicode character가 약 150K개 있다고 설명한다.
장점
-
구현이 단순하다.
-
대부분의 문자열을 character 단위로 표현할 수 있다.
-
word-level UNK 문제는 덜하다.
문제점
-
Vocabulary가 매우 크다.
-
많은 character가 매우 rare하다.
-
Compression ratio가 낮다.
-
큰 vocabulary와 긴 sequence라는 문제를 동시에 가진다.
강의의 표현:
This tokenizer is the worst of both worlds.
Character tokenizer는 직관적으로 좋아 보일 수 있다. 단어보다 작으므로 unseen word 문제가 줄어들고, byte보다 의미 단위에 가까운 것처럼 보인다.
하지만 Unicode 전체를 vocabulary로 보면 크기가 매우 커진다. 게다가 실제 데이터에서 대부분의 character는 거의 등장하지 않는다.
예를 들어 영어 위주 corpus에서 희귀 emoji나 특수 문자는 embedding이 충분히 학습되지 않는다. 반면 한국어/중국어/일본어처럼 문자 집합이 큰 언어에서는 character vocabulary 문제가 더 크게 나타날 수 있다.
26. Byte tokenizer
Byte tokenizer는 Unicode string을 UTF-8 byte sequence로 바꾼다.
UTF-8:
예:
bytes("a", encoding="utf-8") == b"a"
일부 Unicode character는 여러 byte로 표현된다.
bytes("🌍", encoding="utf-8") == b"\xf0\x9f\x8c\x8d"
Byte tokenizer 구현:
class ByteTokenizer(Tokenizer):
def encode(self, string: str) -> list[int]:
string_bytes = string.encode("utf-8")
return list(map(int, string_bytes))
def decode(self, indices: list[int]) -> str:
string_bytes = bytes(indices)
return string_bytes.decode("utf-8")
장점
-
Vocabulary size가 256으로 매우 작다.
-
모든 Unicode string을 표현할 수 있다.
-
UNK token이 필요 없다.
문제점
-
Compression ratio가 1이다.
-
Sequence가 너무 길어진다.
-
Transformer context length가 제한되어 있으므로 비효율적이다.
Byte tokenizer는 vocabulary 관점에서는 매우 아름답다. 모든 텍스트를 256개 값만으로 표현할 수 있기 때문이다.
하지만 sequence length가 너무 길어진다. 예를 들어 하나의 한글 글자는 UTF-8에서 보통 3 bytes를 사용한다. emoji는 4 bytes를 사용할 수 있다. 따라서 byte-level model은 같은 텍스트를 훨씬 긴 sequence로 처리해야 한다.
Transformer의 full attention은 sequence length가 길어질수록 비용이 커지므로, byte tokenizer는 현재의 Transformer architecture에서는 compute-inefficient하다.
이것이 tokenizer-free model이 아직 frontier에서 어려운 이유 중 하나다. bytes를 직접 쓰려면 architecture가 긴 sequence를 효율적으로 처리할 수 있어야 한다.
27. Word tokenizer
Word tokenizer는 문자열을 단어 단위로 나눈다. 강의에서는 regex를 사용한다.
예시:
string = "I'll say supercalifragilisticexpialidocious!"
chunks = regex.findall(r"\w+|.", string)
이 정규식은 alphanumeric character를 하나의 word로 묶고, 나머지는 개별 문자처럼 처리한다.
장점
-
각 token이 인간에게 의미 있는 단위에 가깝다.
-
Compression ratio가 좋다.
-
sequence length가 짧아진다.
문제점
-
Vocabulary size가 매우 커질 수 있다.
-
rare word가 많다.
-
training 때 보지 못한 word는 UNK token으로 처리해야 한다.
-
fixed vocabulary size를 정하기 어렵다.
-
UNK는 perplexity 계산에도 문제를 일으킬 수 있다.
Word tokenizer는 전통 NLP에서 자연스러운 선택이었다. 하지만 LLM에서는 문제가 크다.
예를 들어 다음 단어를 생각해보자.
supercalifragilisticexpialidocious
이 단어가 training vocabulary에 없다면 word tokenizer는 이를 UNK로 바꿔야 한다. 그러면 모델은 단어 내부 구조를 전혀 활용할 수 없다.
또한 code, URL, 숫자, 신조어, 오탈자, 다국어 text에서는 word boundary가 명확하지 않다. 한국어처럼 조사와 어미가 붙는 언어에서도 word 단위는 비효율적일 수 있다.
28. Byte Pair Encoding, BPE
BPE는 원래 1994년 Philip Gage가 data compression을 위해 제안한 알고리즘이다.
이후 neural machine translation에서 rare word 처리를 위해 NLP에 적용되었다.
그리고 GPT-2에서도 사용되었다.
Basic idea
BPE의 핵심은 tokenizer를 raw text에서 학습한다는 것이다.
자주 등장하는 byte sequence는 하나의 token으로 합친다.
드물게 등장하는 sequence는 여러 token으로 남긴다.
Algorithm sketch:
-
각 byte를 하나의 token으로 시작한다.
-
인접 token pair의 빈도를 센다.
-
가장 자주 등장하는 pair를 하나의 새 token으로 merge한다.
-
원하는 merge 수만큼 반복한다.
BPE는 character/byte/word tokenizer의 중간 지점이다.
| 방식 | 장점 | 단점 |
|---|---|---|
| Character | 단순함 | vocabulary 큼, sequence 길다 |
| Byte | vocabulary 256, UNK 없음 | sequence 너무 길다 |
| Word | sequence 짧음, 의미 단위 | vocabulary 큼, UNK 문제 |
| BPE | 적절한 compression, rare word 처리 가능 | tokenizer 학습 필요, heuristic |
BPE는 frequent pattern을 하나의 token으로 만들어 compression ratio를 높인다. 동시에 rare word는 subword나 byte 조합으로 표현할 수 있어 UNK 문제를 줄인다.
29. BPE training 예시
강의의 예시 문자열:
the cat in the hat
BPE training은 먼저 문자열을 UTF-8 bytes로 바꾼다.
indices = list(map(int, string.encode("utf-8")))
그 다음 merge를 저장할 dictionary와 vocabulary를 만든다.
merges = {}
vocab = {x: bytes([x]) for x in range(256)}
각 반복에서 하는 일:
-
adjacent pair의 빈도를 센다.
-
가장 빈도가 높은 pair를 찾는다.
-
새 index를 만든다.
-
merges에 pair → new index를 저장한다.
-
vocab에 new index → merged bytes를 저장한다.
-
indices 안의 해당 pair를 new index로 치환한다.
핵심 함수:
def count_adjacent_pairs(indices):
counts = defaultdict(int)
for index1, index2 in zip(indices, indices[1:]):
counts[(index1, index2)] += 1
return counts
merge 함수:
def merge(indices, pair, new_index):
new_indices = []
i = 0
while i < len(indices):
if i + 1 < len(indices) and indices[i] == pair[0] and indices[i + 1] == pair[1]:
new_indices.append(new_index)
i += 2
else:
new_indices.append(indices[i])
i += 1
return new_indices
예를 들어 the cat in the hat에서 t h, h e, e space 같은 pair의 빈도를 센다. 가장 자주 등장하는 pair를 merge하면 sequence length가 줄어든다.
이 과정을 반복하면 자주 등장하는 문자열 조각이 점점 하나의 token이 된다.
중요한 점은 BPE가 의미론적으로 “좋은 단어”를 직접 찾는 알고리즘은 아니라는 것이다. BPE는 빈도 기반 compression heuristic이다. 하지만 language data에서는 자주 등장하는 byte sequence가 대체로 유용한 subword 단위와 겹치기 때문에 효과적이다.
30. BPE tokenizer 사용
BPE tokenizer는 학습된 vocab과 merges를 사용한다.
@dataclass(frozen=True)
class BPETokenizerParams:
vocab: dict[int, bytes]
merges: dict[tuple[int, int], int]
Encode:
-
문자열을 UTF-8 byte index sequence로 바꾼다.
-
학습된 merge rule을 순서대로 적용한다.
-
최종 token id sequence를 반환한다.
Decode:
-
token id를 vocab의 byte sequence로 바꾼다.
-
bytes를 이어 붙인다.
-
UTF-8로 decode해 문자열을 복원한다.
class BPETokenizer(Tokenizer):
def encode(self, string: str) -> list[int]:
indices = list(map(int, string.encode("utf-8")))
for pair, new_index in self.params.merges.items():
indices = merge(indices, pair, new_index)
return indices
def decode(self, indices: list[int]) -> str:
bytes_list = list(map(self.params.vocab.get, indices))
return b"".join(bytes_list).decode("utf-8")
이 구현은 교육용으로 단순하다. 실제 tokenizer는 훨씬 빠르게 구현되어야 한다. 강의에서도 현재 encode()가 모든 merge를 loop한다고 지적한다.
Assignment 1에서는 다음을 개선해야 한다.
-
모든 merge를 매번 순회하지 않고, 실제로 필요한 merge만 고려한다.
-
special token을 감지하고 보존한다.
-
예:
<|endoftext|> -
GPT-2 tokenizer regex 같은 pre-tokenization을 사용한다.
-
가능한 빠르게 구현한다.
31. Tokenization summary
강의의 tokenization 요약:
Tokenizer: strings ↔ tokens(indices)
Character-based, byte-based, word-based tokenization are highly suboptimal.
BPE is an effective heuristic that is data-driven.
Tokenization is a separate step; maybe one day we do it end-to-end from bytes.
하지만 어떤 해법이든 다음 조건을 만족해야 한다.
- 모델은 sequence의 chunk, 즉 abstraction 위에서 작동해야 한다.
-
text
-
video
-
DNA
-
etc.
- chunk는 variable해야 한다.
- 중요한 부분에는 더 많은 modeling capacity를 배정해야 한다.
이 마지막 문장이 중요하다. Tokenization은 단순히 text preprocessing 문제가 아니라, sequence를 어떤 단위로 추상화할 것인가의 문제다.
Text뿐 아니라 video, audio, DNA sequence에서도 비슷한 문제가 있다.
-
너무 작은 단위로 쪼개면 sequence가 길어져 compute가 비싸다.
-
너무 큰 단위로 묶으면 rare pattern과 unseen pattern을 처리하기 어렵다.
-
좋은 단위는 데이터에서 자주 등장하는 구조를 효율적으로 압축해야 한다.
BPE는 완벽한 해법은 아니지만, 현재 Transformer 기반 LLM에서는 매우 실용적인 타협이다.
32. 전체 강의의 핵심 연결
Lecture 01은 단순한 OT + tokenization 강의가 아니다. 전체 CS336의 문제의식을 세운 뒤, 첫 번째 구체적 주제로 tokenization에 들어간다.
강의의 큰 흐름은 다음과 같다.
1. LLM 연구자는 underlying technology에서 멀어지고 있다.
2. Frontier model은 너무 비싸고, 내부 정보가 공개되지 않는다.
3. 그렇다고 작은 모델의 모든 직관이 큰 모델에 전이되지는 않는다.
4. 하지만 mechanics와 mindset은 전이된다.
5. 핵심 mindset은 efficiency다.
6. Efficiency는 data, compute, memory, communication bandwidth를 모두 고려해야 한다.
7. CS336은 이 관점으로 tokenizer, architecture, training, systems, scaling, data, alignment를 다룬다.
8. Tokenization은 그 첫 예시다.
마지막으로 이 강의를 한 문장으로 요약하면 다음과 같다.
CS336 Lecture 01은 LLM을 API가 아니라 전체 시스템으로 바라보게 만들고,
그 첫 번째 관문으로 text를 token sequence로 바꾸는 문제를 efficiency 관점에서 설명한다.
Comments