[논문 리뷰] Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
논문: Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
주제: reasoning distillation에서 teacher가 생성한 CoT trajectory 중 student가 실제로 잘 배울 수 있는 데이터를 어떻게 고를 것인가?
한 줄 요약
이 논문은 강한 teacher가 만든 reasoning trajectory가 항상 좋은 학습 데이터는 아니다라는 문제의식에서 출발한다. 저자들은 student model 기준으로 “낯설지만 배울 수 있는” trajectory를 찾기 위해 Rank-Surprisal Ratio(RSR)라는 간단한 metric을 제안한다.
핵심 아이디어는 다음과 같다.
좋은 reasoning trajectory는 student가 스스로 쉽게 생성할 정도로 익숙해서는 안 되지만, 그렇다고 student의 분포에서 완전히 벗어나서도 안 된다.
즉, 좋은 trajectory는 student model 기준으로:
- 절대 확률은 낮다. → student가 원래는 잘 생성하지 못하므로 새로운 학습 신호가 있다.
- 상대적 순위는 높다. → 완전히 말도 안 되는 token은 아니며, student의 후보군 안에서는 그럴듯한 선택이다. 수치적으로는 rank 값이 낮다는 뜻이다.
이를 수식으로 만들면 RSR이다.
\[\mathrm{RSR}(x) = \frac{ \sum_k \min(\mathrm{Rank}(t_k), r_{\max}) }{ \sum_k \mathrm{Surprisal}(t_k) }\]낮은 RSR은 alignment와 informativeness가 잘 균형 잡힌 trajectory를 의미한다.
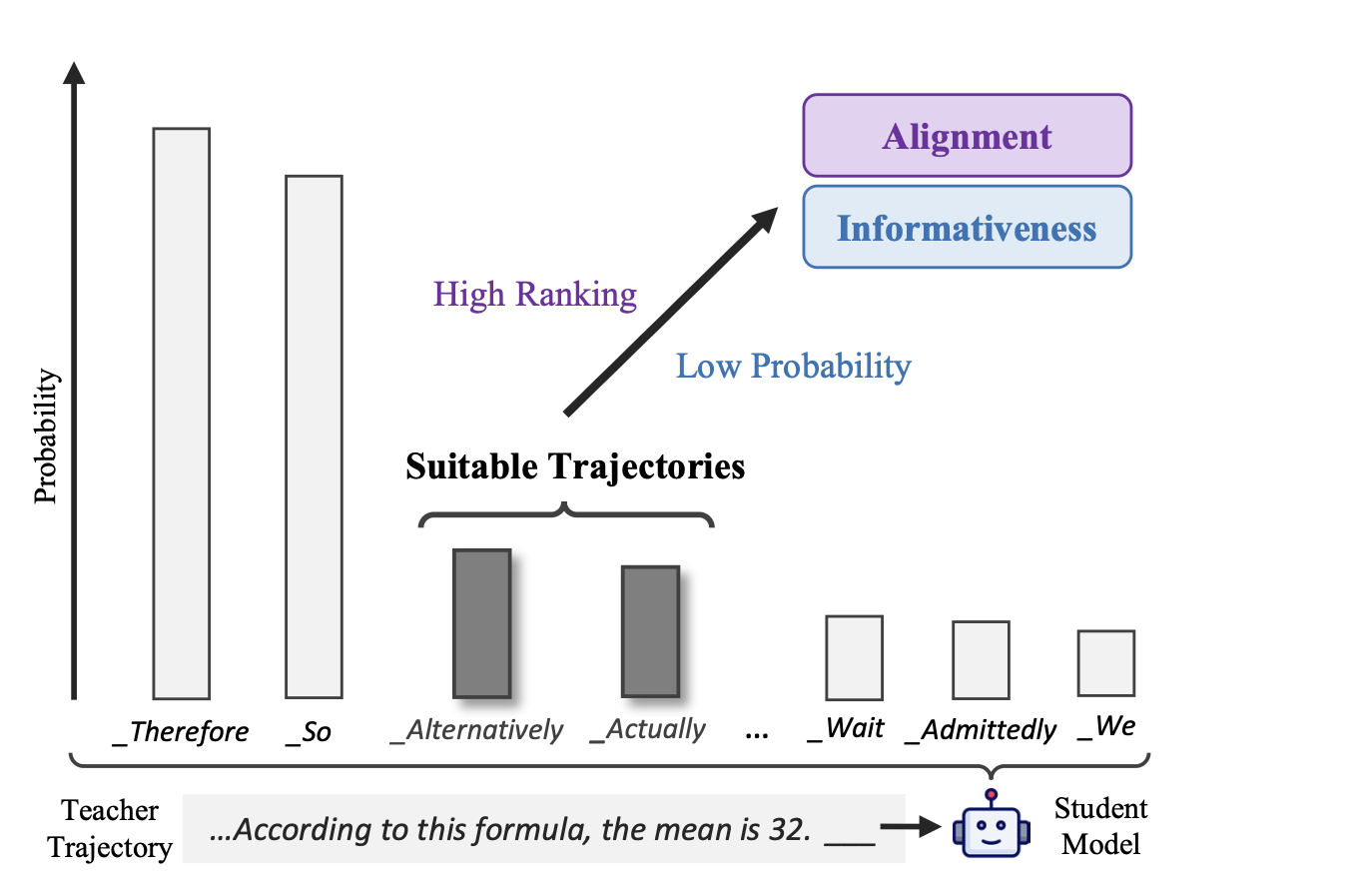
Figure 1. RSR의 핵심 직관. 좋은 trajectory는 student 기준으로 절대 확률은 낮지만, token rank는 상대적으로 높은 영역에 위치한다. 즉, 너무 쉽지도 너무 낯설지도 않은 데이터다.
1. 왜 이 논문이 중요한가?
최근 reasoning-oriented LLM의 발전은 긴 Chain-of-Thought(CoT) trajectory를 생성하는 능력과 밀접하게 연결되어 있다. 긴 CoT는 test-time reasoning을 가능하게 할 뿐 아니라, teacher model의 reasoning 능력을 student model로 distillation하기 위한 SFT 데이터로도 활용된다.
일반적으로 생각하면 더 강한 teacher가 만든 reasoning data가 더 좋은 student를 만들 것 같지만, 논문은 이것이 항상 성립하지 않는다고 말한다. 실제로 강한 teacher의 trajectory가 작은 student에게는 너무 어렵거나, 모델 family가 달라 reasoning pattern이 낯설어서 잘 흡수되지 않을 수 있다.
따라서 중요한 질문은 다음과 같다.
어떤 reasoning trajectory가 특정 student model에게 가장 좋은 학습 데이터인가?
이 논문은 이 문제를 data-student suitability라고 부른다. 즉, 데이터 자체의 절대적 품질뿐 아니라, 그 데이터가 특정 student에게 얼마나 적합한가를 봐야 한다는 것이다.
2. 기존 likelihood 기반 selection의 한계
기존 data selection 방법들은 주로 student model이 해당 trajectory에 부여하는 likelihood를 사용한다. 쉽게 말해, student가 이미 높은 확률로 예측할 수 있는 trajectory를 좋은 데이터로 판단하는 방식이다.
하지만 이 방식에는 문제가 있다.
학생에게 이미 너무 쉬운 문제만 계속 풀게 하면 새로 배울 것이 별로 없다. LLM도 비슷하다. student가 이미 높은 확률로 생성할 수 있는 trajectory는 현재 behavior와는 잘 맞지만, 추가적인 학습 신호는 약할 수 있다.
반대로 너무 어려운 데이터도 문제다. student의 prediction distribution에서 완전히 벗어난 trajectory는 informative해 보일 수 있지만, student가 흡수하기 어렵다.
정리하면 다음과 같다.
| 유형 | student 기준 확률 | token rank | 해석 | 학습 효과 |
|---|---|---|---|---|
| 너무 쉬운 trajectory | 높음 | 높음, 즉 rank 값 낮음 | 이미 student가 잘 생성할 수 있음 | 새 학습 신호가 약함 |
| 너무 어려운 trajectory | 낮음 | 낮음, 즉 rank 값 큼 | student 분포와 너무 멀리 있음 | 흡수하기 어려움 |
| 좋은 trajectory | 낮음 | 높음, 즉 rank 값 낮음 | 낯설지만 후보군 안에서는 그럴듯함 | 학습에 효과적 |
여기서 “순위가 높다”는 표현은 자연어적으로는 top-ranked에 가깝다는 뜻이고, 수치적으로는 rank 값이 작다는 뜻이다.
3. 핵심 직관: 낯설지만 배울 수 있어야 한다
논문이 말하는 좋은 trajectory는 다음과 같은 데이터다.
student가 평소에 스스로 만들지는 못하지만, 보여주면 “아, 이 방향도 가능하구나” 하고 배울 수 있는 reasoning path
예를 들어 다음 token이 따라서라고 하자. student의 다음 token 분포가 다음과 같다면:
1위: "이므로" 0.25
2위: "그래서" 0.20
3위: "따라서" 0.08
4위: "하지만" 0.04
...
따라서의 절대 확률은 0.08로 낮지만, 전체 vocabulary 안에서는 3위다. 즉 student가 강하게 선택하지는 않았지만, 후보군 안에서는 충분히 그럴듯한 token이다.
이런 token들이 많은 trajectory는 student에게 새롭지만 완전히 낯설지는 않은 데이터다. 논문은 이런 특성을 absolute unfamiliarity + relative familiarity라고 설명한다.
- absolute unfamiliarity: student가 생성할 절대 확률은 낮다.
- relative familiarity: 다른 token 후보들과 비교하면 여전히 높은 순위에 있다.
이 두 가지를 함께 보는 것이 RSR의 핵심이다.
4. 실험 설정: teacher-student pairing
논문은 먼저 “stronger teacher가 항상 better student를 만드는가?”를 확인하기 위해 대규모 teacher-student pairing 실험을 수행한다.
4.1 Student models
Student model은 총 5개이며, 모두 pre-trained base model이다.
| Student model | 크기 |
|---|---|
| Qwen-3-14B | 14B |
| LLaMA-3.1-8B | 8B |
| Qwen-2.5-7B | 7B |
| Qwen-3-4B | 4B |
| Qwen-2.5-3B | 3B |
4.2 Teacher models
Teacher model은 총 11개이며, 4B부터 671B까지 다양한 reasoning-oriented model을 포함한다.
| Teacher model | 크기 |
|---|---|
| DeepSeek-R1-0528 | 671B |
| Qwen-3-235B-Thinking-2507 | 235B |
| GPT-OSS-120B high | 120B |
| LLaMA-3.3-Nemotron-Super-49B-v1.5 | 49B |
| QwQ-32B | 32B |
| Qwen-3-30B-Thinking-2507 | 30B |
| Magistral-Small-2506 | 24B |
| GPT-OSS-20B high | 20B |
| Phi-4-Reasoning-Plus | 14B |
| Qwen-3-8B thinking | 8B |
| Qwen-3-4B-Thinking-2507 | 4B |
Teacher와 student를 조합하면 총 55개의 teacher-student pair가 된다.
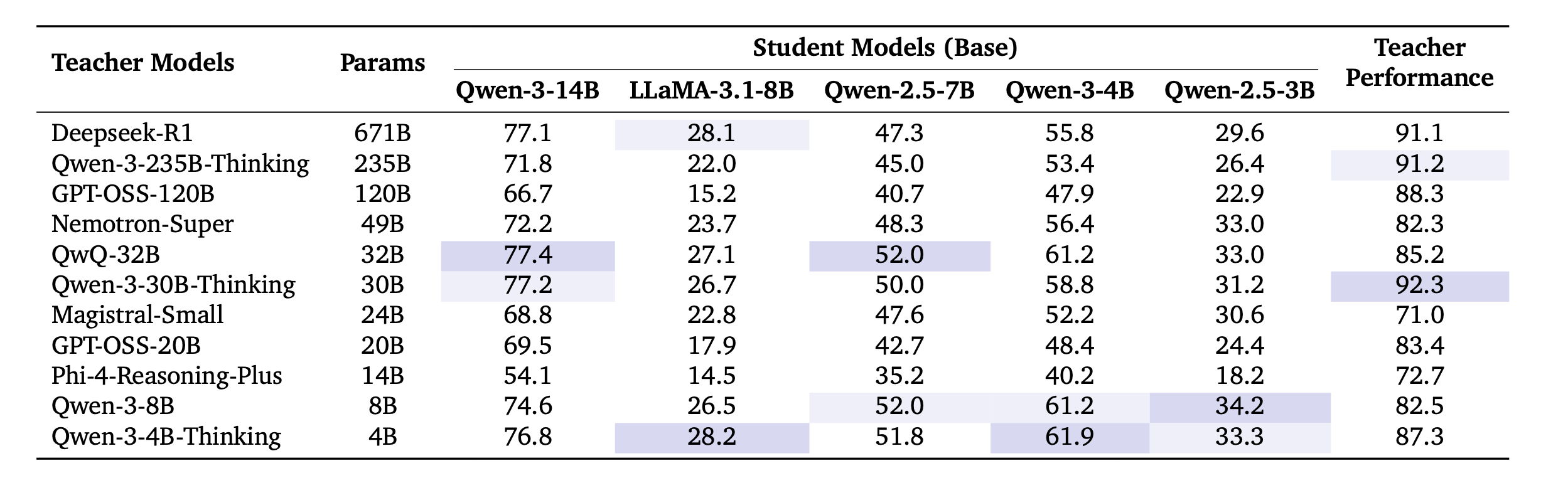
Table 1. 11개 teacher와 5개 student의 pairing distillation 결과. teacher의 크기나 reasoning 성능만으로 student의 최종 성능을 예측하기 어렵다는 점을 보여준다.
4.3 Dataset과 benchmark
각 teacher는 5,000개 수학 문제에 대해 long CoT response를 생성한다. 그리고 각 student는 해당 teacher가 만든 trajectory dataset으로 SFT된다.
평가는 다음 네 가지 수학 reasoning benchmark에서 수행된다.
- AIME’25
- AIME’24
- AMC’23
- MATH500
Metric은 Acc@4를 사용한다.
Acc@4는 한 문제에 대해 4번 독립적으로 답변을 생성하고, 그 4개의 정답 여부를 평균낸 정확도다. 예를 들어 한 문제에서 4번 중 2번 맞으면 해당 문제의 점수는 0.5가 된다. 이는 4번 중 하나라도 맞으면 정답 처리하는 pass@4와 다르다.
5. 더 강한 teacher가 항상 좋은 것은 아니다
논문의 첫 번째 중요한 결과는 다음이다.
teacher capability는 student improvement를 안정적으로 예측하지 못한다.
예를 들어 671B, 235B 규모의 teacher가 여러 student에서 QwQ-32B 같은 더 작은 teacher보다 낮은 결과를 보이는 경우가 있었다. 또한 reasoning performance가 강한 teacher라도 모든 student에서 항상 최고의 결과를 만들지는 못했다.
이 결과는 단순히 다음과 같은 규칙이 통하지 않는다는 것을 보여준다.
큰 teacher를 쓰면 된다.
가장 reasoning benchmark가 높은 teacher를 쓰면 된다.
같은 model family의 teacher를 쓰면 된다.
물론 모델 family나 scale이 전혀 의미 없다는 뜻은 아니다. 다만 그것만으로 data-student suitability를 설명하기에는 부족하다는 것이다.
논문의 결론은 명확하다.
reasoning distillation에서는 teacher의 절대적 성능보다, teacher trajectory가 student에게 얼마나 잘 맞는지가 중요하다.
6. Surprisal과 Rank
RSR을 이해하기 위해서는 먼저 두 가지 token-level measure를 이해해야 한다.
6.1 Surprisal
Surprisal은 student model이 현재 token을 얼마나 낯설게 보는지를 나타낸다.
이전 context를 $c_k = (t_1, \dots, t_{k-1})$라고 할 때, token $t_k$의 surprisal은 다음과 같이 정의된다.
\[\mathrm{Surprisal}(t_k) = -\log p_\theta(t_k \mid c_k)\]확률이 낮을수록 surprisal은 커진다.
예를 들어:
p(token) = 0.8 → surprisal ≈ 0.22
p(token) = 0.1 → surprisal ≈ 2.30
p(token) = 0.01 → surprisal ≈ 4.61
즉 surprisal이 높다는 것은 student에게 더 낯선 token이라는 뜻이다.
6.2 Rank
Rank는 현재 token이 student의 prediction distribution 안에서 몇 번째 후보인지를 나타낸다.
\[\mathrm{Rank}(t_k) = 1 + \sum_{t' \in \mathcal{V}} I[p_\theta(t' \mid c_k) > p_\theta(t_k \mid c_k)]\]여기서 1을 더하는 이유는 rank를 0등이 아니라 1등부터 시작하게 만들기 위해서다. 현재 token보다 확률이 높은 token이 0개라면 rank는 1이다.
Rank는 probability와 달리 relative familiarity를 본다. 어떤 token의 절대 확률은 낮더라도, vocabulary 전체에서는 여전히 top candidate일 수 있다.
7. Probability-based metric의 한계
기존 연구들은 주로 average log-probability 또는 average surprisal을 사용해 data suitability를 평가했다.
Surprisal은 log-probability의 음수이므로 다음 관계가 성립한다.
\[\mathrm{Avg\text{-}Surprisal}(x) = -\mathrm{Avg\text{-}LogProb}(x)\]따라서 high log-probability를 선호한다는 것은 low surprisal을 선호한다는 뜻이다.
하지만 논문은 low surprisal이 반드시 좋은 post-training performance로 이어지지 않는다는 것을 보인다. 예를 들어 Nemotron-Super나 Magistral-Small의 trajectory는 student 기준 surprisal이 낮게 나오지만, 실제 학습 성능 향상은 크지 않았다. 이는 해당 trajectory가 student에게 너무 익숙해서 새로운 학습 신호가 약할 수 있음을 시사한다.
반대로 surprisal이 너무 높은 trajectory도 좋지 않다. GPT-OSS-20B처럼 student 분포에서 지나치게 멀어지는 trajectory는 정보량이 많아 보이지만, student가 흡수하기 어려울 수 있다.
따라서 surprisal 하나만으로는 부족하다. 낯섦과 정렬성을 함께 봐야 한다.
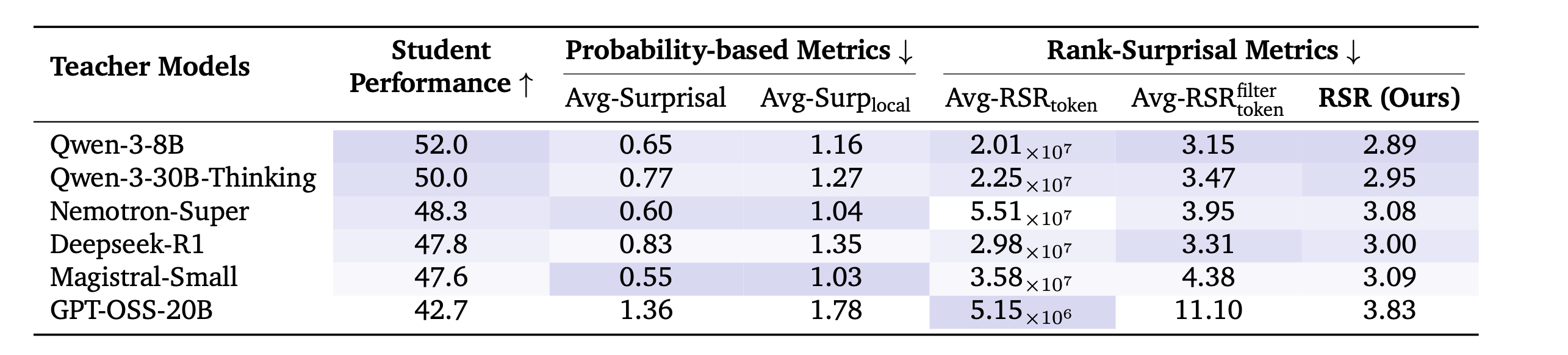
Table 2. Avg-Surprisal, Avg-Surp_local, RSR 계열 metric의 preliminary 비교. 낮은 surprisal, 즉 높은 likelihood가 항상 좋은 학습 결과로 이어지지 않음을 보여준다.
8. Simulation: 왜 Rank와 Surprisal을 같이 봐야 하는가?
논문은 student의 token prediction distribution을 단순화해 simulation한다. 핵심은 student의 분포를 두 개의 mode가 섞인 bimodal distribution으로 보는 것이다.
- $Z_A$: student의 dominant generation pattern
- $Z_B$: dominant pattern은 아니지만 student에게 어느 정도 익숙한 minor pattern
전체 분포 $Z$는 다음과 같이 구성된다.
\[Z = \pi Z_A + (1 - \pi) Z_B\]여기서 $Z_A$와 $Z_B$는 Zipf distribution으로 모델링된다.
\[Z_A, Z_B \sim \mathrm{Zipf}(\alpha)\]그리고:
\[\pi = \frac{M_A}{M_A + M_B}, \quad M_A > M_B\]$M_A > M_B$라는 것은 $Z_A$가 major mode이고, $Z_B$가 minor mode라는 뜻이다.
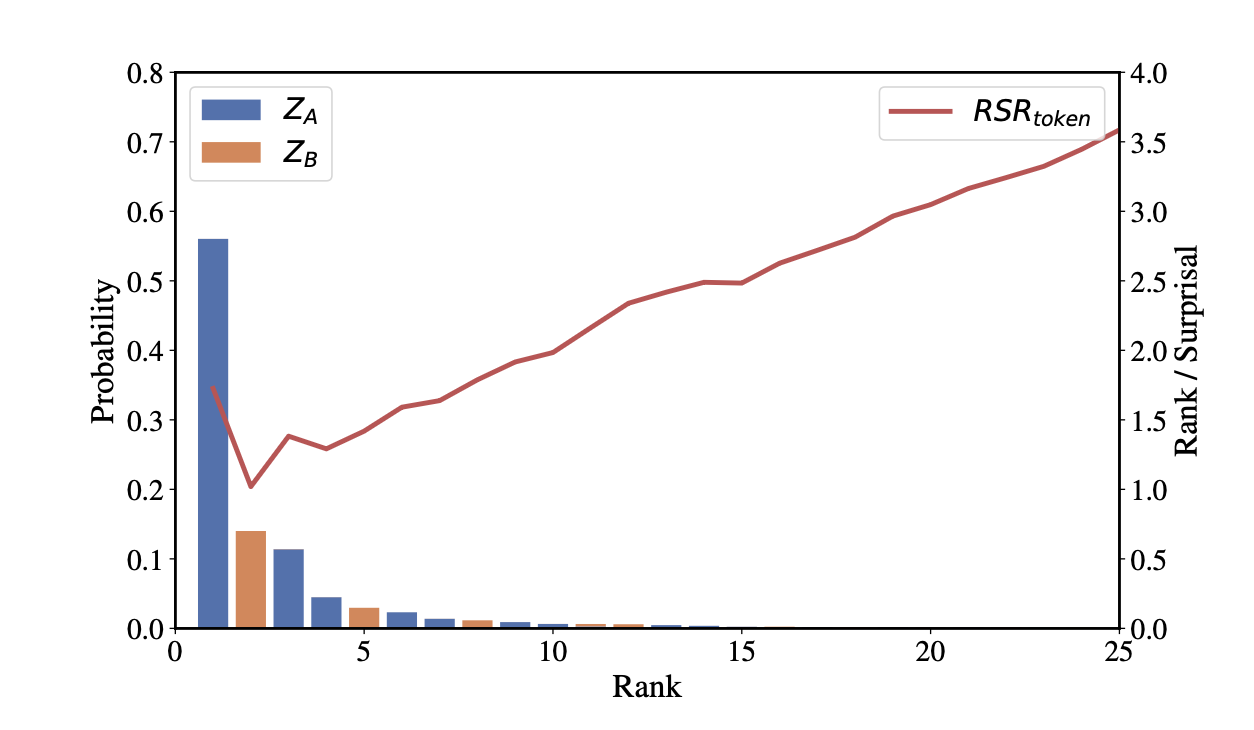
Figure 2. Student의 prediction distribution을 dominant mode (Z_A)와 minor mode (Z_B)의 mixture로 모델링한 simulation. 논문은 효과적인 trajectory가 (Z_B)와 align되는 (X_B) 형태에 가깝다고 본다.
이제 논문은 네 가지 trajectory type을 정의한다.
| Trajectory | 샘플링 분포 | 의미 |
|---|---|---|
| $X_A$ | $Z_A$ | student의 dominant pattern을 강하게 따르는 trajectory |
| $X_B$ | $Z_B$ | dominant pattern에서는 벗어나지만 student의 minor pattern과 align되는 trajectory |
| $X_C$ | $Z_A$, $Z_B$와 다른 분포 | student와 misaligned된 trajectory |
| $X_D$ | $Z$ | student의 전체 predictive behavior를 반영하는 trajectory |
논문이 선호하는 것은 $X_B$다.
$X_B$는 dominant pattern $Z_A$에서는 벗어나므로 surprisal이 높다. 하지만 student 내부의 minor pattern $Z_B$와는 align되어 있으므로 rank는 낮다. 즉, 절대 확률은 낮지만 상대적 순위는 높은 trajectory다.
이 simulation은 RSR의 직관을 잘 보여준다.
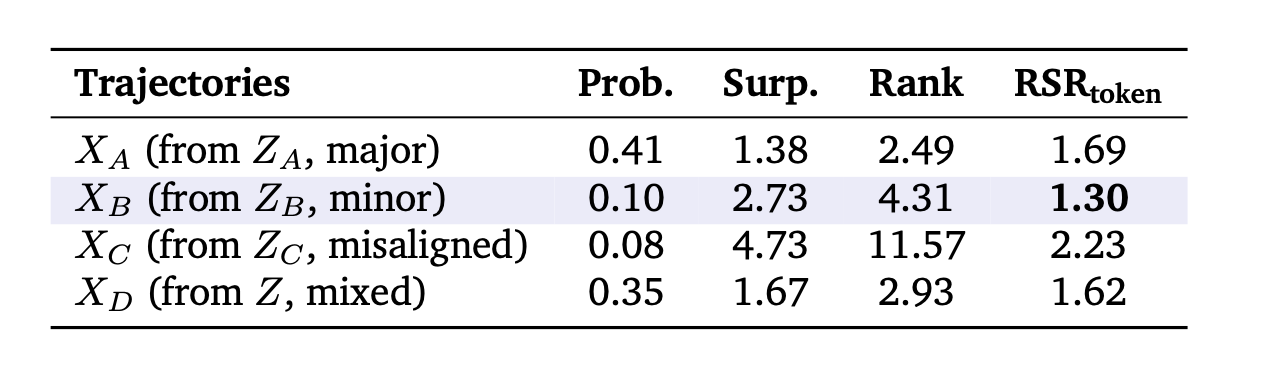
Table 3. Simulation 결과. 선호되는 (X_B)는 surprisal은 높지만 rank 값은 낮아, RSR이 가장 낮게 나타난다.
9. Rank-Surprisal Ratio
9.1 Token-level RSR
Surprisal과 rank를 결합하기 위해 논문은 token-level ratio를 먼저 정의한다.
\[\mathrm{RSR}_{\mathrm{token}}(t_k) = \frac{\mathrm{Rank}(t_k)}{\mathrm{Surprisal}(t_k)}\]여기서 중요한 것은 Rank가 분자, Surprisal이 분모라는 점이다.
좋은 token은 다음 특징을 갖는다.
- rank 값이 낮다. → student의 후보군 안에서 비교적 상위에 있다.
- surprisal이 높다. → student가 쉽게 생성하지 못하므로 새로운 학습 신호가 있다.
따라서 좋은 token일수록 RSR 값은 낮아진다.
9.2 왜 token-level ratio를 그냥 평균내면 안 되는가?
단순히 모든 token의 $\mathrm{RSR}_{\mathrm{token}}$을 평균내면 값이 불안정해질 수 있다. 어떤 token은 student가 매우 높은 확률로 예측해서 surprisal이 거의 0에 가까울 수 있다. 이 경우 분모가 0에 가까워지므로 ratio가 매우 커진다.
따라서 논문은 surprisal이 낮은 token의 영향을 줄이기 위해 두 가지 아이디어를 사용한다.
첫째, surprisal이 높은 token만 보는 filtered average를 고려한다. $\mathcal{T}_H(x)$를 trajectory $x$에서 surprisal이 상위 $H\%$에 속하는 token 집합이라고 하자.
\[\mathrm{Avg\text{-}RSR}^{\mathrm{filter}}_{\mathrm{token}}(x) = \frac{ \sum_{t_k \in \mathcal{T}_H(x)} \mathrm{RSR}_{\mathrm{token}}(t_k) }{ |\mathcal{T}_H(x)| }\]실험적으로는 surprisal 상위 30% token을 사용할 때 post-training performance와 더 높은 correlation을 보였다고 한다.
둘째, hard filtering 대신 surprisal-weighted average를 사용한다. $r_k = \mathrm{Rank}(t_k)$, $s_k = \mathrm{Surprisal}(t_k)$라고 하면:
\[\frac{ \sum_k s_k \mathrm{RSR}_{\mathrm{token}}(t_k) }{ \sum_k s_k } = \frac{ \sum_k s_k \frac{r_k}{s_k} }{ \sum_k s_k } = \frac{ \sum_k r_k }{ \sum_k s_k } = \frac{ \sum_k \mathrm{Rank}(t_k) }{ \sum_k \mathrm{Surprisal}(t_k) }\]결국 trajectory-level RSR은 token rank의 합을 token surprisal의 합으로 나눈 형태가 된다.
9.3 Final RSR
실제로는 vocabulary size가 크기 때문에 매우 낯선 token은 rank 값이 지나치게 커질 수 있다. 이런 token들은 student 입장에서는 사실상 모두 구분하기 어려운 tail token이므로, 논문은 rank 값을 $r_{\max}$에서 clipping한다.
최종 RSR은 다음과 같다.
\[\mathrm{RSR}(x) = \frac{ \sum_k \min(\mathrm{Rank}(t_k), r_{\max}) }{ \sum_k \mathrm{Surprisal}(t_k) }\]논문은 이후 실험에서 $r_{\max}=100$을 사용한다.
9.4 RSR 해석
RSR의 해석은 단순하다.
- 분자 Rank: relative familiarity를 나타낸다. 작을수록 student와 잘 align된다.
- 분모 Surprisal: absolute unfamiliarity를 나타낸다. 클수록 새로운 학습 신호가 강하다.
따라서 RSR이 낮다는 것은:
rank는 낮고,
surprisal은 높은 trajectory
라는 뜻이다.
즉, student에게 낯설지만 배울 수 있는 trajectory를 의미한다.
10. Correlation Analysis
논문은 RSR이 실제 post-training reasoning performance와 얼마나 잘 맞는지 correlation analysis를 수행한다.
10.1 Dataset-level score로 aggregate
각 teacher는 5,000개 trajectory를 생성한다. trajectory마다 RSR을 계산할 수 있지만, teacher dataset 하나를 대표하려면 trajectory-level score들을 하나의 dataset-level score로 합쳐야 한다.
이 과정을 논문에서는 aggregate한다고 표현한다.
예를 들어:
Teacher A dataset
- trajectory 1: RSR = 2.0
- trajectory 2: RSR = 3.0
- trajectory 3: RSR = 2.5
...
이 값들을 평균 또는 weighted average로 합쳐 Teacher A dataset의 대표 RSR을 만든다.
논문에서는 단순 평균보다 Eq. 6과 유사한 weighted averaging scheme이 약간 더 좋은 correlation을 보였다고 설명한다. 직관적으로는 dataset 전체 token에 대해 다음과 비슷하게 계산하는 방식이다.
\[\mathrm{RSR}_{\mathrm{dataset}} \approx \frac{ \sum_{x \in D}\sum_{t_k \in x}\min(\mathrm{Rank}(t_k), r_{\max}) }{ \sum_{x \in D}\sum_{t_k \in x}\mathrm{Surprisal}(t_k) }\]그 후 teacher dataset별 RSR과, 그 dataset으로 SFT한 student의 benchmark 성능 사이의 Spearman correlation을 측정한다.
10.2 비교 metric
논문은 RSR을 다양한 metric과 비교한다.
- teacher model performance
- token length
- average surprisal
- local surprisal
- rank-based metric
- word frequency 기반 rule-based quality score
- LLM-judged quality score
- answer accuracy
- gradient-based score, 예: G-Norm, GRACE
- influence score
10.3 결과
RSR은 모든 student model에 대해 post-training reasoning performance와 강한 correlation을 보였다. 평균 Spearman correlation은 0.86이며, 비교 metric들을 일관되게 능가했다.
반면 surprisal-only metric이나 rank-only metric은 correlation이 훨씬 약했다. 논문은 이 결과를 통해 informativeness와 alignment를 동시에 modeling하는 것이 중요하다고 주장한다.
개인적으로 이 부분이 이 논문의 핵심 근거라고 느꼈다. RSR은 단순히 그럴듯한 직관을 제시하는 데 그치지 않고, 실제 teacher-student pairing 결과와 높은 상관을 보였기 때문이다.
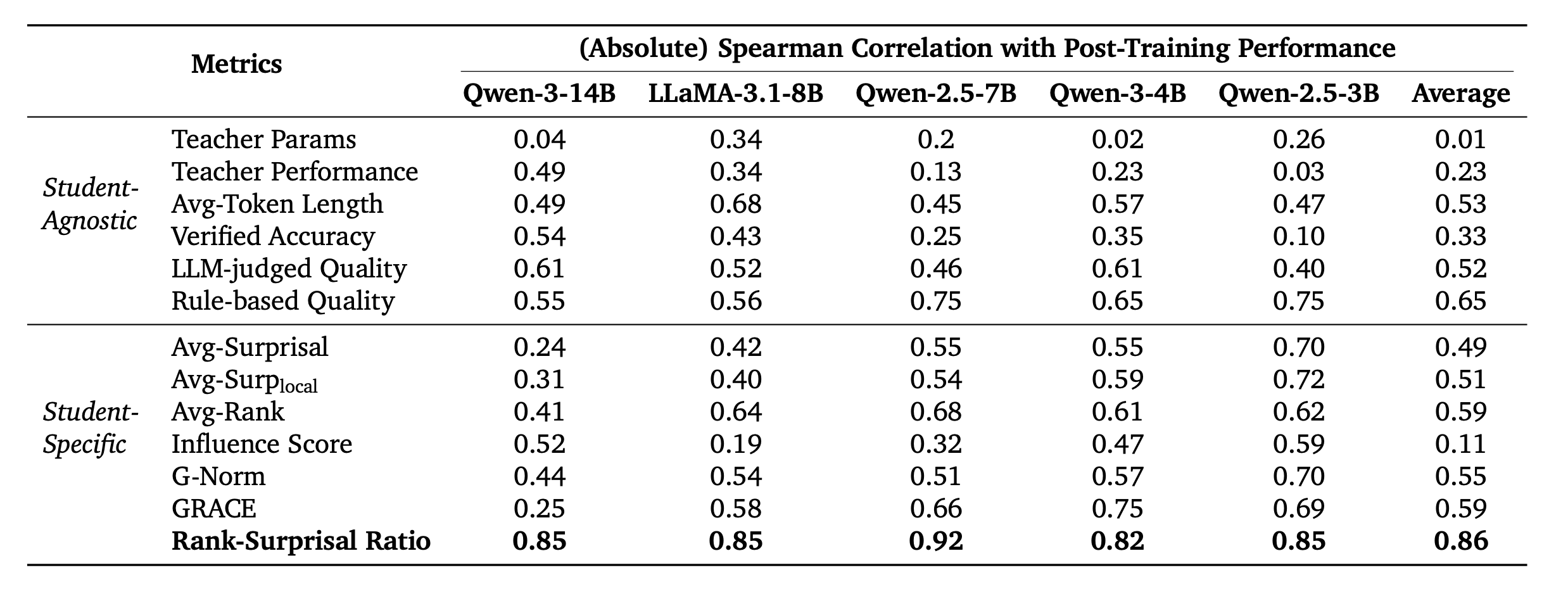
Table 4. Dataset-level metric과 post-training reasoning performance 사이의 Spearman correlation. RSR은 평균 0.86으로 다른 metric보다 높은 상관을 보인다.
11. Ablation Study
논문은 RSR의 구성 요소가 실제로 필요한지 ablation study를 통해 확인한다.
주요 ablation은 다음과 같다.
- rank clipping 제거
- surprisal-weighted averaging 제거
- $r_{\max}$ 변경
- teacher당 5,000개가 아니라 200개 trajectory만 사용
결과적으로 rank clipping과 surprisal-weighted averaging을 제거하면 correlation이 크게 떨어진다. 이는 두 구성 요소가 RSR의 안정성에 중요하다는 것을 보여준다.
또한 teacher당 200개 trajectory만 사용해도 RSR의 correlation이 꽤 유지되었다. 이 점은 실무적으로 중요하다. 모든 candidate teacher에 대해 대규모 데이터를 생성하지 않아도, 소량 pilot data만으로 teacher suitability를 추정할 수 있기 때문이다.
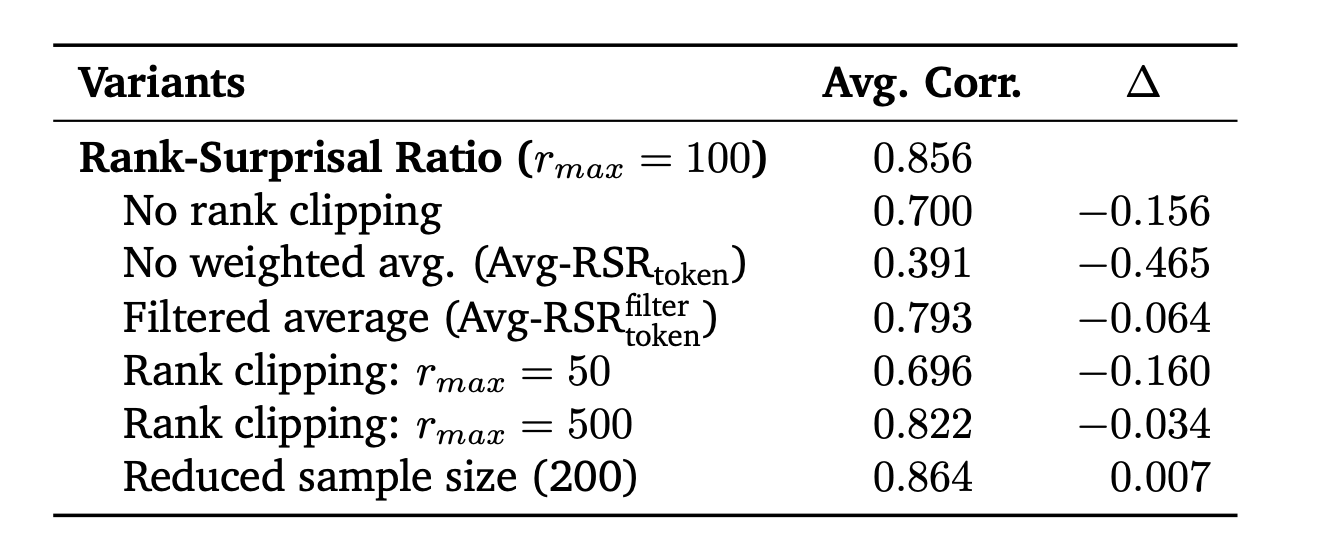
Table 5. RSR ablation study. Rank clipping과 surprisal-weighted averaging을 제거하면 correlation이 낮아지며, teacher당 200개 trajectory만 사용해도 RSR의 경향은 비교적 유지된다.
12. Data Engineering에서의 활용
논문은 RSR을 두 가지 data engineering scenario에 적용한다.
- Trajectory selection
- Teacher selection
12.1 Trajectory Selection
Trajectory selection은 같은 문제에 대해 여러 teacher가 생성한 후보 trajectory가 있을 때, 어떤 trajectory를 학습 데이터로 사용할지 선택하는 문제다.
예를 들어 한 수학 문제에 대해 다음과 같은 후보가 있다고 하자.
Problem 1
- DeepSeek-R1 trajectory
- Qwen-3-235B trajectory
- QwQ-32B trajectory
- GPT-OSS trajectory
...
RSR은 각 trajectory를 target student 기준으로 scoring하고, RSR이 낮은 trajectory를 선택한다.
논문 결과에 따르면 RSR 기반 selection은 random selection, token length 기반 selection, rule-based quality, LLM-judge quality, answer accuracy 기반 selection보다 전반적으로 더 좋은 post-training performance를 보였다.
흥미로운 점은 LLM-judge도 꽤 좋은 baseline이라는 것이다. 이는 LLM-judge가 trajectory 자체의 품질, 예를 들어 논리성, 완성도, 표현 품질 등을 어느 정도 잘 평가한다는 뜻이다. 다만 LLM-judge는 “이 trajectory가 특정 student에게 잘 맞는가?”를 직접 보는 metric은 아니다.
따라서 실무적으로는 다음처럼 역할을 나누는 것이 좋아 보인다.
LLM Judge: 이 reasoning 자체가 좋은가?
RSR: 이 reasoning을 우리 student가 잘 배울 수 있는가?
즉 LLM-judge는 quality filter로, RSR은 student-specific selector로 사용하는 것이 합리적이다.
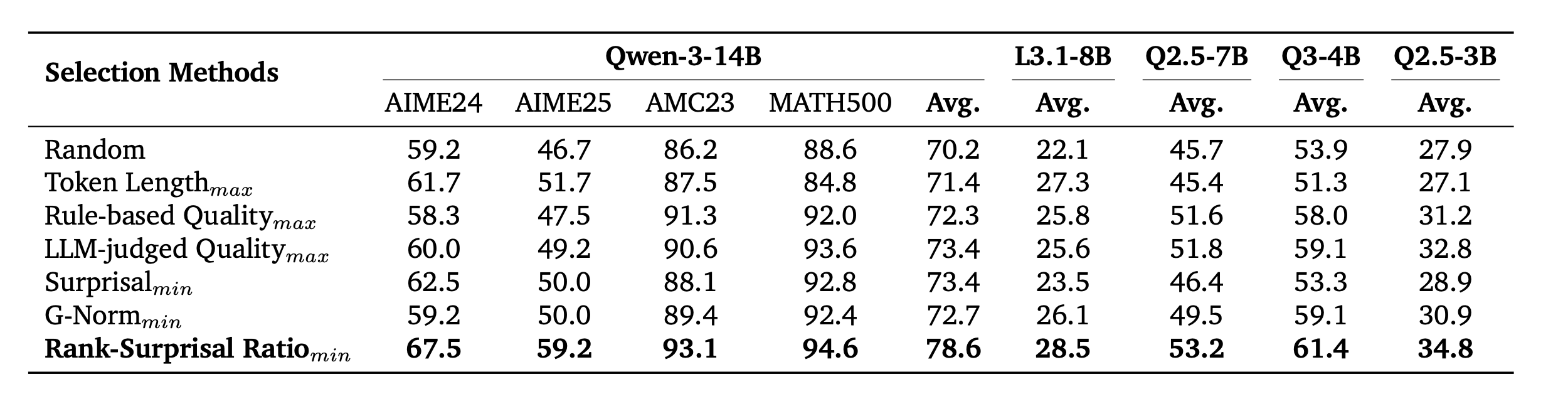
Table 6. Trajectory selection 결과. RSR은 random, length, rule-based quality, LLM-judge quality, answer accuracy 기반 selection보다 전반적으로 높은 post-training 성능을 보인다.
12.2 Teacher Selection
Teacher selection은 distillation 전에 어떤 teacher model을 사용할지 고르는 문제다.
현실에서는 모든 candidate teacher로 full training dataset을 생성하는 것이 비싸다. 논문은 이를 고려해 low-resource setting을 사용한다.
절차는 다음과 같다.
- 후보 teacher별로 200개 trajectory만 샘플링한다.
- target student 기준으로 각 trajectory의 RSR을 계산한다.
- teacher별 dataset-level average score를 구한다.
- RSR이 낮은 teacher를 선택한다.
Teacher selection 실험의 candidate pool은 다음 6개 모델이다.
- DeepSeek-R1
- Qwen-3-235B-Thinking
- Nemotron-Super
- Qwen-3-30B-Thinking
- Magistral-Small
- GPT-OSS-20B
논문은 항상 잘하는 teacher를 일부러 제외해 teacher selection task가 너무 쉬워지지 않게 만들었다고 설명한다.
결과적으로 RSR이 선택한 best teacher와 second-best teacher는 oracle teacher에 가까운 post-training reasoning performance를 보였다. 여기서 oracle teacher는 실제로 모든 teacher로 학습해 본 뒤 가장 좋은 teacher를 의미한다.
이 결과는 꽤 실용적이다. full-scale distillation을 시작하기 전에, teacher당 200개 정도의 작은 sample만으로 어떤 teacher가 target student에게 적합한지 추정할 수 있기 때문이다.
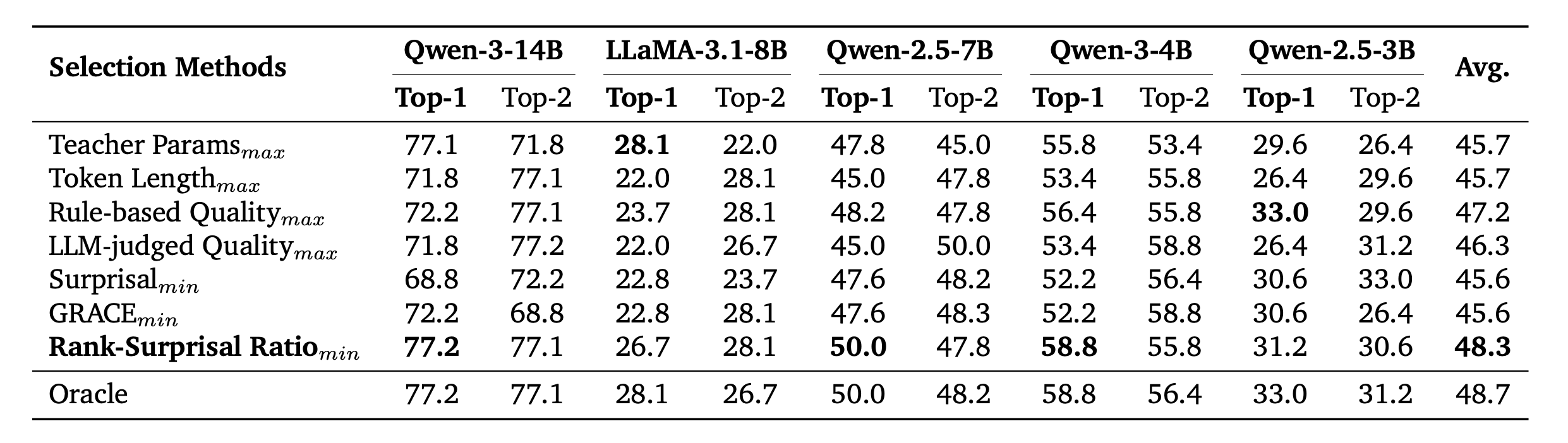
Table 7. Teacher selection 결과. Teacher별 200개 trajectory만 사용해 RSR을 계산해도, oracle에 가까운 teacher를 고를 수 있음을 보여준다.
13. Broader Applicability
논문은 RSR이 CoT reasoning data에만 국한되지 않을 수 있다고 말한다.
13.1 Beyond CoT Data
RSR은 본질적으로 token-level rank와 surprisal을 사용하는 metric이다. 따라서 꼭 reasoning trajectory에만 적용할 필요는 없다. 일반 text data, instruction-following data, dialogue data에도 적용할 수 있는 가능성이 있다.
다만 논문은 실제 실험을 주로 mathematical reasoning에 집중했기 때문에, 다른 domain에서의 효과는 향후 연구 과제로 남겨두고 있다.
13.2 Subset Selection
또 하나의 가능성은 subset selection이다.
Trajectory selection은 같은 문제에 대해 여러 trajectory를 비교하는 것이다. 반면 subset selection은 서로 다른 문제와 서로 다른 trajectory들이 섞인 dataset에서 어떤 sample을 남길지 선택하는 문제다.
예를 들어 문제당 trajectory가 하나씩만 있는 데이터셋이 있다고 하자.
Problem 1 - trajectory 1
Problem 2 - trajectory 2
Problem 3 - trajectory 3
...
이 경우 같은 문제 내 후보 비교는 불가능하다. 대신 서로 다른 문제 간 RSR을 비교해 더 좋은 subset을 고를 수 있다.
다만 이 setting은 더 어렵다. 문제 자체의 난이도, domain, prompt style이 모두 다르기 때문에 RSR 차이가 trajectory-student suitability 때문인지, 문제 난이도 때문인지 분리하기 어렵다.
논문은 내부 preliminary experiment에서 가능성을 확인했다고 하지만, 체계적인 검증은 향후 연구로 남겨두고 있다.
14. Limitations
논문이 인정하는 한계는 크게 세 가지다.
14.1 Candidate pool의 품질과 다양성에 의존한다
RSR은 고정된 후보 trajectory 중 더 나은 것을 선택하는 metric이다. 따라서 후보 자체가 모두 나쁘거나, 특정 student에게 잘 맞는 trajectory가 전혀 없다면 selection만으로 얻을 수 있는 성능 향상은 제한적이다.
논문은 향후에는 RSR을 단순 selection이 아니라 trajectory rewriting 또는 synthesis에 활용할 수 있다고 제안한다.
14.2 이론적 grounding은 아직 부족하다
RSR은 단순하고 해석 가능한 metric이지만, 이를 더 깊은 이론적 framework로 설명하지는 못했다. 논문도 이 부분을 future work로 남긴다.
14.3 실험 domain이 주로 수학 reasoning이다
논문은 extensive controlled study를 위해 주로 math reasoning task를 사용했다. GPQA를 통해 일부 generalization을 확인했지만, code, commonsense reasoning, 일반 instruction following, multilingual reasoning 등에 대해서는 아직 충분히 검증되지 않았다.
따라서 RSR을 다른 domain에 적용하려면 별도의 실험이 필요하다.
15. 내가 실제로 적용한다면
이 논문을 읽으면서 가장 많이 떠오른 적용처는 teacher-generated reasoning distillation pipeline이다. 특히 Claude, Qwen, DeepSeek, GPT-OSS 같은 teacher로 reasoning trace를 만들고, 이를 Gemma/Qwen 계열 student에 SFT하는 상황에서 바로 활용할 수 있다.
내가 적용한다면 다음과 같은 pipeline을 구성할 것 같다.
1. Teacher model로 reasoning trace 생성
- Claude Sonnet
- Claude Opus
- Qwen Thinking
- GPT-OSS
- DeepSeek 계열
2. Rule-based filter
- 형식 오류 제거
- 정답 오류 제거
- 길이 제한 초과 제거
- 반복 패턴 제거
- 언어 mixing 과도한 sample 제거
3. LLM Judge quality scoring
- factual accuracy
- logical rigor
- solution completeness
- reasoning efficiency
- presentation quality
4. Student-side RSR scoring
- target student 기준 token logprob 계산
- token rank 계산
- surprisal 계산
- trajectory-level RSR 계산
5. Selection
- LLM Judge 하위 품질 제거
- 남은 후보 중 RSR 낮은 sample 선택
- domain/length bucket 비율 유지
6. SFT
- random selection
- LLM Judge selection
- RSR selection
- LLM Judge + RSR selection
을 ablation으로 비교
여기서 중요한 점은 LLM Judge와 RSR의 역할을 구분하는 것이다.
- LLM Judge는 trajectory 자체의 품질을 본다.
- RSR은 trajectory와 student의 적합성을 본다.
따라서 둘 중 하나만 쓰기보다, LLM Judge로 품질을 거르고 RSR로 student-specific suitability를 보는 방식이 가장 안정적일 것 같다.
16. Qwopus식 curriculum과 비교하면?
최근 공개 모델들 중에는 Qwopus3.6-35B-A3B-v1처럼 multi-teacher distillation과 curriculum learning을 강조하는 사례도 있다. 해당 접근은 대략 다음과 같은 전략을 사용한다.
Stage 1. 짧고 안정적인 reasoning format 학습
Stage 2. 복잡한 reasoning과 multi-teacher distillation 확대
Stage 3. long-context reasoning 강화 + short sample replay
이 전략은 “어떤 순서와 길이 분포로 학습할 것인가”에 대한 실전적인 recipe다.
반면 RSR은 “어떤 trajectory를 고를 것인가”에 대한 selection metric이다. 따라서 둘은 경쟁 관계라기보다 상호보완적이다.
내가 본다면:
데이터 선택: RSR
학습 스케줄: curriculum learning
품질 검수: LLM Judge
이 조합이 가장 현실적이다.
17. 정리
이 논문의 핵심 메시지는 간단하지만 중요하다.
reasoning distillation에서는 teacher가 강한지만 볼 것이 아니라, teacher trajectory가 student에게 얼마나 적합한지를 봐야 한다.
RSR은 이를 측정하기 위한 간단한 metric이다. 좋은 trajectory는 student 기준으로 확률은 낮지만, rank는 높은 token들로 구성된다. 즉, student에게 낯설지만 배울 수 있는 데이터다.
논문은 RSR이 post-training reasoning performance와 강한 correlation을 보이며, trajectory selection과 teacher selection 모두에서 유용하다는 것을 보인다.
개인적으로 이 논문은 reasoning SFT 데이터셋을 만들 때 꽤 실용적인 기준을 제공한다고 느꼈다. 특히 Claude나 Qwen 같은 강한 teacher로 distillation data를 만들 때, 생성된 데이터를 그대로 학습하는 대신 student 기준으로 다시 scoring하고 선별해야 한다는 점이 중요하다.
마지막으로 이 논문을 한 문장으로 정리하면 다음과 같다.
좋은 distillation data는 teacher가 가장 잘 쓴 답변이 아니라, student가 가장 잘 배울 수 있는 답변이다.
Comments